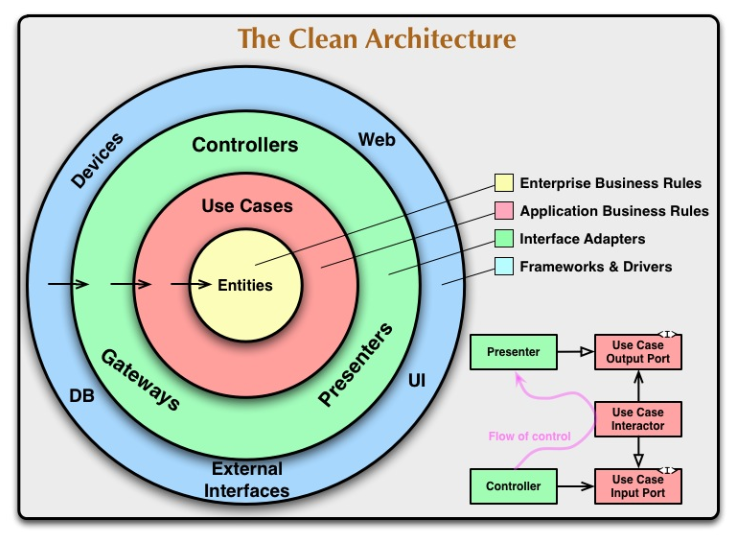
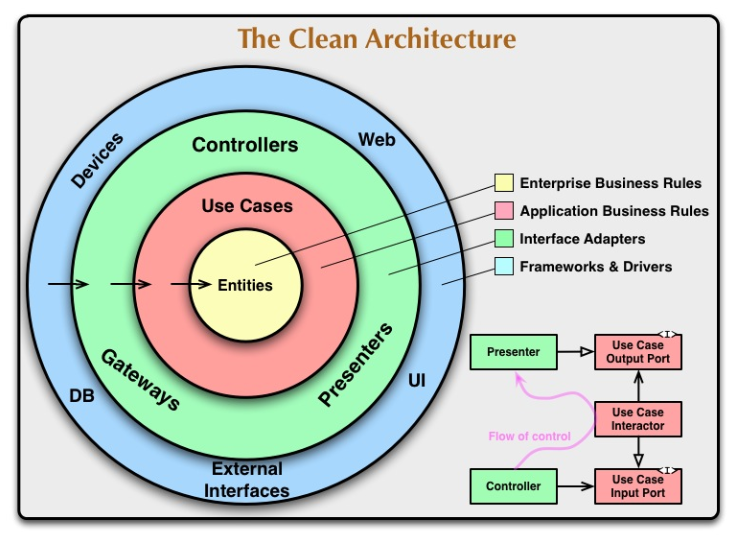
Wzoruje się na Clean Architecture i mam kilka wątpliwości.
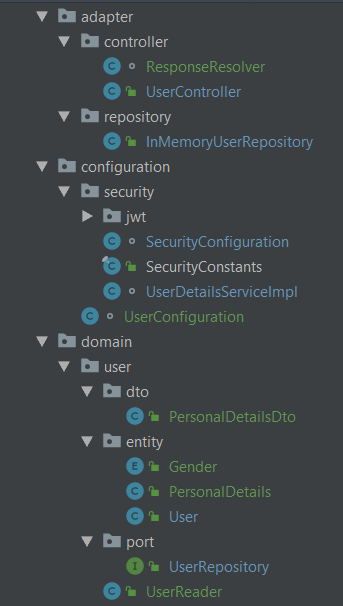
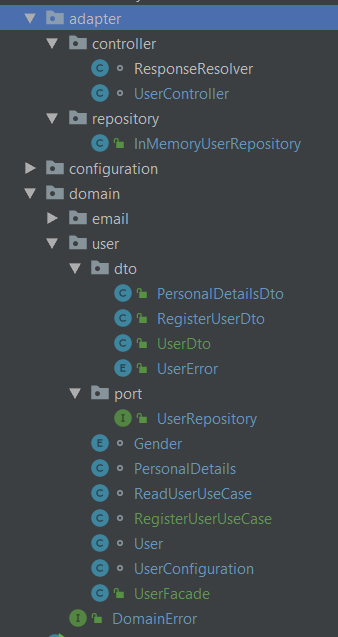
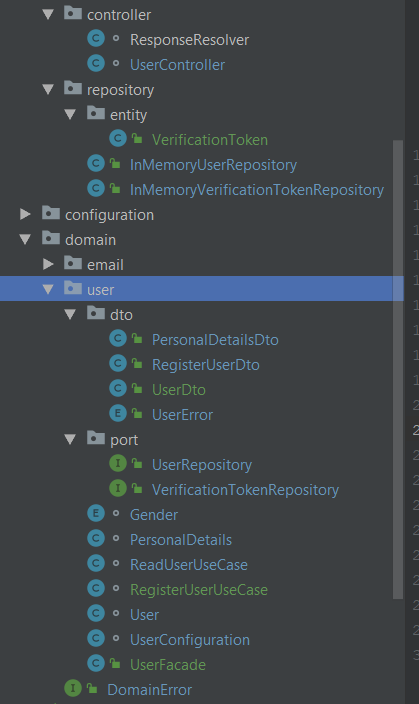
Struktura mojego projektu to obecnie
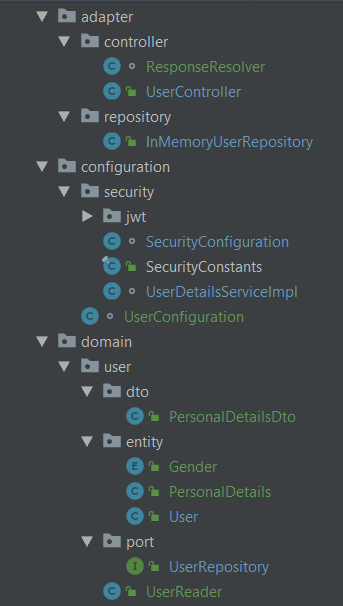
W domain/user/port mam zdefiniowany interfejs oraz jakiś serwis "biznesowy", który ma mi zwrócić dane personalne uzytkownika
public interface UserRepository {
Optional<User> findUser(String username);
}
@RequiredArgsConstructor
public class UserReader {
private final UserRepository repository;
public Optional<PersonalDetailsDto> readPersonalData(String username) {
return repository.findUser(username)
.map(User::getPersonalDetails)
.map(PersonalDetailsDto::new);
}
}
W tej części aplikacji nie używam nic związanego z frameworkiem, tak więc klasy reprezentujące encje są pozbawione adnotacji SpringData
@Getter
@Builder
public class User {
private final String username;
private final String password;
private final String[] roles;
private final PersonalDetails personalDetails;
}
Warstwa controllerów, będzie dostawać Optional'a bądź Either'a i jedyne co tu chcę robić to mapować ewentualny Either.left() na odpowiedni kod HTTP. Tak więc DTO z odpowiednim setem danych będzie przygotowywane przy wyjściu z serwisów w warstwie biznesowej.
@Getter
public class PersonalDetailsDto {
private final String firstName;
private final String lastName;
private final String gender;
private final String birthDate;
private final String weight;
private final String height;
public PersonalDetailsDto(PersonalDetails personalDetails) {
this.firstName = personalDetails.getFirstName();
this.lastName = personalDetails.getFirstName();
this.gender = personalDetails.getGender().getValue();
this.birthDate = personalDetails.getBirthDate()
.format(DateTimeFormatter.ofLocalizedDate(FormatStyle.FULL)
.withLocale(Locale.UK));
this.weight = personalDetails.getWeight() + " kg";
this.height = personalDetails.getHeight() + " cm";
}
}
Do tej pory ma to sens, mapuje sobie rzeczy jak Gender.MALE na Mężczyzna, czy tam parsuje w różny sposób datę, w zależności od tego co potrzebuje dostać na wyjściu w danym wypadku.
Wątpliwości zaczynam mieć przy warstwie encji bazodanowych.
Obecnie moja implementacja UserRepository wygląda tak
@Component
public class InMemoryUserRepository implements UserRepository {
private final Map<String, User> users = new HashMap<>();
public InMemoryUserRepository() {
users.put("admin", User.builder()
.username("admin")
.password("pass")
.roles(new String[] {"ADMIN"}).build());
users.put("user", User.builder()
.username("user")
.password("pass")
.roles(new String[] {"USER"})
.personalDetails(PersonalDetails.builder()
.firstName("John")
.lastName("Doe")
.gender(Gender.MALE)
.height(183.0)
.weight(90.0)
.birthDate(LocalDate.of(1993, 5, 20))
.build())
.build());
}
@Override
public Optional<User> findUser(String username) {
return Optional.ofNullable(users.get(username));
}
}
Jednak docelowo, będzie tutaj musiała powstać dodatkowa klasa, reprezentująca użytkownika w bazie danych. Czyli praktycznie kopia tego co mam w warstwie domeny z dodatkowym polem ID + innymi adnotacjami SpringData. Pytanie czy to już nie zaczyna być przerost nad treścią, czy może kompletnie źle zrozumiałem jak ma wyglądać taki podział architektury?
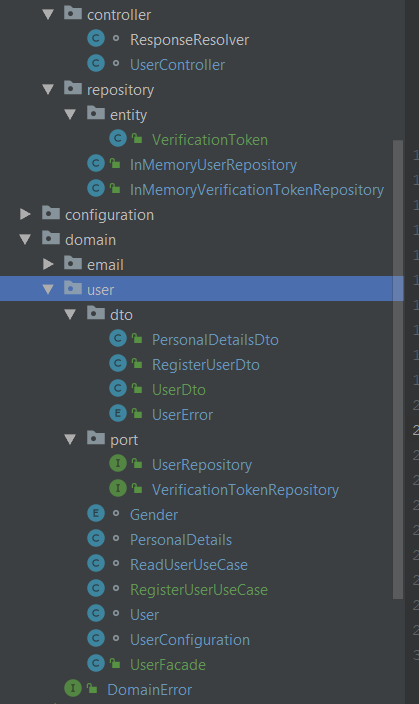
- screenshot-20190803230846.png (368 KB) - ściągnięć: 176
- screenshot-20190803231214.png (39 KB) - ściągnięć: 195




{kind=link}
{kind=link}
{kind=link}
{kind=link}