
Mam taką metodę:
public List<org.bson.Document> crawlForAllMongoDoc() {
List<org.bson.Document> allDocuments = new ArrayList<>();
for (Page page : forumTopic) {
LOG.log(Level.INFO, "downloading url=" + page.url);
for (Post post : page) {
allDocuments.add(post.toMongoDocument());
}
}
return allDocuments;
}
Pobiera html ze strony internetowej i przerabia. Jak przerobi to pobiera następny html z kolejnej strony i znów przerabia. itd.
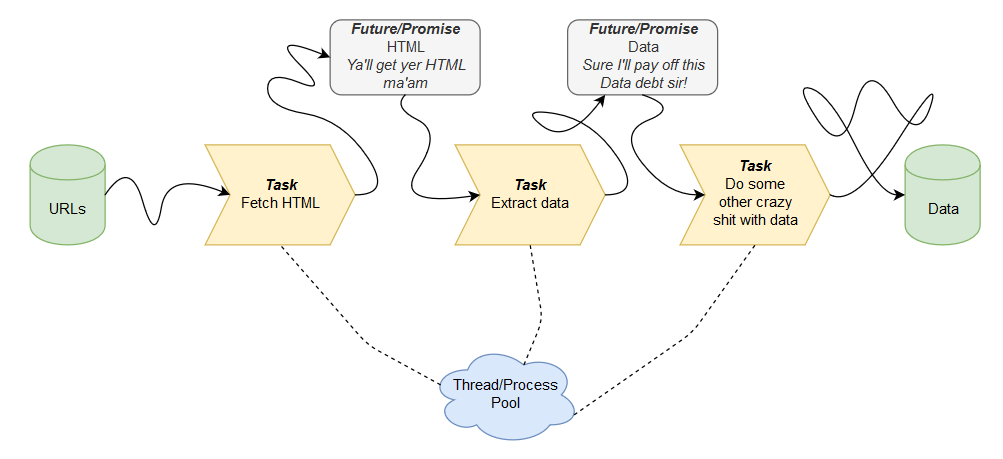
Chciałbym to sparaleryzować:
1 wątek pobiera html ze strony i nie czeka, aż html zostanie przerobiony tylko pobiera od razu następny.
2 wątek przerabia pobrane html, jeśli są jakieś pobrane.
public List<org.bson.Document> crawlForAllMongoDocParraler() {
List<org.bson.Document> allDocuments = new ArrayList<>();
Queue<Page> pagesQueue = new LinkedList<>();
Thread pagerThread = new Thread(() -> {
for (Page page : forumTopic) {
LOG.log(Level.INFO, "downloading url=" + page.url);
pagesQueue.add(page);
synchronized (this) {
notify();
}
}
});
Thread posterThread = new Thread(() -> {
while (!pagesQueue.isEmpty() || pagerThread.isAlive()) {
if (pagesQueue.isEmpty()) {
synchronized (this) {
try {
wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} else {
for (Post post : pagesQueue.poll()) {
allDocuments.add(post.toMongoDocument());
}
}
}
});
pagerThread.start();
posterThread.start();
try {
pagerThread.join();
posterThread.join();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return allDocuments;
}
czy to jest w miarę OK? Zszedłem ze 150 sekund do 130 dzięki temu.
Widzę ryzyko, że jak w 17 linijce wątek 1 będzie żywy, ale już w 21 martwy to wątek 2 nigdy się nie zatrzyma.




{kind=link}
bibliotekarze, omg :Dkomuher