Na forum 4programmers.net korzystamy z plików cookies. Część z nich jest niezbędna do funkcjonowania
naszego forum, natomiast wykorzystanie pozostałych zależy od Twojej dobrowolnej zgody, którą możesz
wyrazić poniżej. Klikając „Zaakceptuj Wszystkie” zgadzasz się na wykorzystywanie przez nas plików cookies
analitycznych oraz reklamowych, jeżeli nie chcesz udzielić nam swojej zgody kliknij „Tylko niezbędne”.
Możesz także wyrazić swoją zgodę odrębnie dla plików cookies analitycznych lub reklamowych. W tym celu
ustaw odpowiednio pola wyboru i kliknij „Zaakceptuj Zaznaczone”. Więcej informacji o technologii cookie
znajduje się w naszej polityce prywatności.
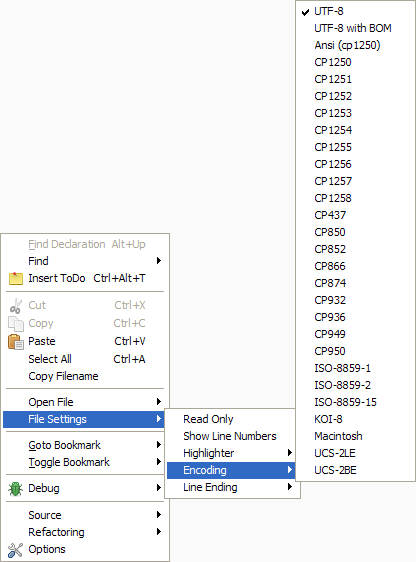
Lazarus nie używa domyślnie markera BOM do plików źródłowych, ani do plików .pas, ani do plików .lfm. Jeżeli nie wiesz jak kodowane są pliki źródłowe to możesz to łatwo sprawdzić - otwórz plik w środowisku, a następnie kliknij PPM w edytorze i przejdź do poniższej opcji:
Domyślnie jest UTF-8 - sprawdź co u Ciebie pokazuje w pliku .lfm tego formularza.
Otwórz sobie ten plik .lfm np. w Notepad++, przekonwertuj zawartość na gołe UTF-8, a następnie ręcznie popraw te krzaki. Wtedy już Lazarus powinien prawidłowo je odczytywać.
Witam serdecznie. Dziękuję za szybką odpowiedź. JUż chyba wszystko robiłem: zmieniałem czcionkę na Default, charset na Default, same plik źródłowe na UTF8 z BOM i bez. Raz projekt zapisuje jest OK, a raz otwieram i dalej to samo - krzaczki. Zauważyłem, że krzaczki najczęściej pojawiają się po zakończeniu projektu i wyłączeniu komputera. Kiedy włącze komputer i odpalę projekt to one już na mnie czekają ://
Otwórz plik .lfm w Notepad++ (tylko nie w środowisku) i zamień wszystkie popsute ciągi na prawidłowe. Tyle wystarczy - sprawdziłem. Po zmianie wszystkich Caption i zapisaniu zmian, Lazarus nie pozmienia znaków diakrytyzowanych na krzaki.
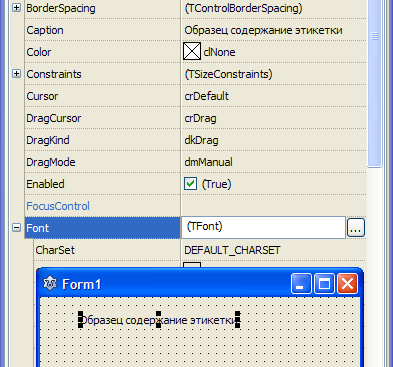
Druga sprawa - LCL natywnie obsługuje UTF-8, tak więc aby w kontrolkach wyświetlić ruskie znaczki, wystarczy je po prostu wkleić do pola w oknie inspektora obiektów:
A Ty niepotrzebnie zmieniłeś charsety labelków:
Kopiuj
Font.CharSet = RUSSIAN_CHARSET
Być może to wpłynęło na zawartość pliku .lfm, ale nie chce mi się już drążyć tego tematu. Popraw te ciągi i nie zmieniaj charsetów - niech pozostaną domyślne.
Poza tym, od niedawna dostępna jest nowa wersja środowiska (Lazarus 1.6.4), a także nowa wersja kompilatora (FPC 3.0.2), więc dokonaj aktualizacji, jeśli używasz starszych wersji.
Problem rozwiązany. Zrobiłem tak, że utworzyłem nowy projekt z pustymi plikami typu "pas, lfm". Następnie skopiowałem zawartość - treść swoich plików do nich, zapisałem pod edytorem w Lazarusie i voila kodowanie wszystkich jest w porządku pod UTF-8 i wszystko działa :)
Jeszcze raz serdecznie dziękuję za pomoc :)
Usunąć wpis?
Tej operacji nie będzie można cofnąć.
Zarejestruj się i dołącz do największej społeczności programistów w Polsce.
Otrzymaj wsparcie, dziel się wiedzą i rozwijaj swoje umiejętności z najlepszymi.






{kind=link}
{kind=link}