Rozwiązań jest sporo, ale jednym z najprostszych jest policzenie index of coincidence dla różnych przesunięć ciphertextu (http://en.wikipedia.org/wiki/Index_of_coincidence).
Przykładowo jeśli masz ciphertext:
ciph: AURNFOAHJFNFAIJNFEEU
Liczysz najpierw IOC1:
AURNFOAHJFNFAIJNFEEU
AURNFOAHJFNFAIJNFEEU
-0000000000000000010-
(tutaj 1 albo 0.05, zależnie jak definiować IoC (0.05 jest praktyczniejsze))
Następnie IOC2:
AURNFOAHJFNFAIJNFEEU
AURNFOAHJFNFAIJNFEEU
--000000000000000000--
(tutaj 0)
Dalej IOC3:
AURNFOAHJFNFAIJNFEEU
AURNFOAHJFNFAIJNFEEU
---00000000000000000---
(tutaj 0)
I tak dalej, aż do maksymalnej podejrzewanej długości klucza (powiedzmy 20 albo 100).
Tutaj akurat wyniki nie robią wrażenia, bo przykładowe dane są bardzo sztuczne, ale docelowo szukamy takiego n, gdzie IoC będzie najwyższe - zresztą dla wielokrotności n również IoC powinien odbiegać (być wyższy) od normy.
Dlaczego - bo szyfr polialfabetyczny działa tak, że (zakładamy n=4) dla tekstu ABCDEFGHIJKL otrzymujemy wynikowy tekst (gdzie a, b, c, d to funkcje szyfrujące dla każdego znaku):
a(A), b(B), c(C), d(D), a(E), b(F), c(G), d(H), a(I), b(J), c(K), d(L)
Teraz licząc ioc dla n=3, mamy:
a(A), b(B), c(C), d(D), a(E), b(F), c(G), d(H), a(I), b(J), c(K), d(L)
a(A), b(B), c(C), d(D), a(E), b(F), c(G), d(H), a(I), b(J), c(K), d(L)
Widać że porównujemy wyniki róznych funkcji, co powoduje że rezultat jest dość losowy.
Natomiast ioc dla n=4 daje:
a(A), b(B), c(C), d(D), a(E), b(F), c(G), d(H), a(I), b(J), c(K), d(L)
a(A), b(B), c(C), d(D), a(E), b(F), c(G), d(H), a(I), b(J), c(K), d(L)
Tutaj porównujemy wyniki tej samej funkcji za każdym razem, więc siłą rzeczy 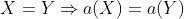 . W drugą stronę też mamy implikacje, bo inaczej funkcja by sie nie nadawała do szyfru podstawnego, więc
. W drugą stronę też mamy implikacje, bo inaczej funkcja by sie nie nadawała do szyfru podstawnego, więc 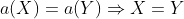
Z tego wynika równoważność 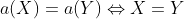 , więc IOC tak przesuniętego ciphertekstu będzie prawie taki sam jak dla (typowego) plaintextu - a więc znacząco wyższy.
, więc IOC tak przesuniętego ciphertekstu będzie prawie taki sam jak dla (typowego) plaintextu - a więc znacząco wyższy.
Oczywiście trzeba mieć trochę ciphertextu do tego, bo bez tekstu do analizy nic się nie osiągnie, ale w zasadzie tyle.