Cześć
Czy zajmuje się ktoś tutaj CNN i ML ?
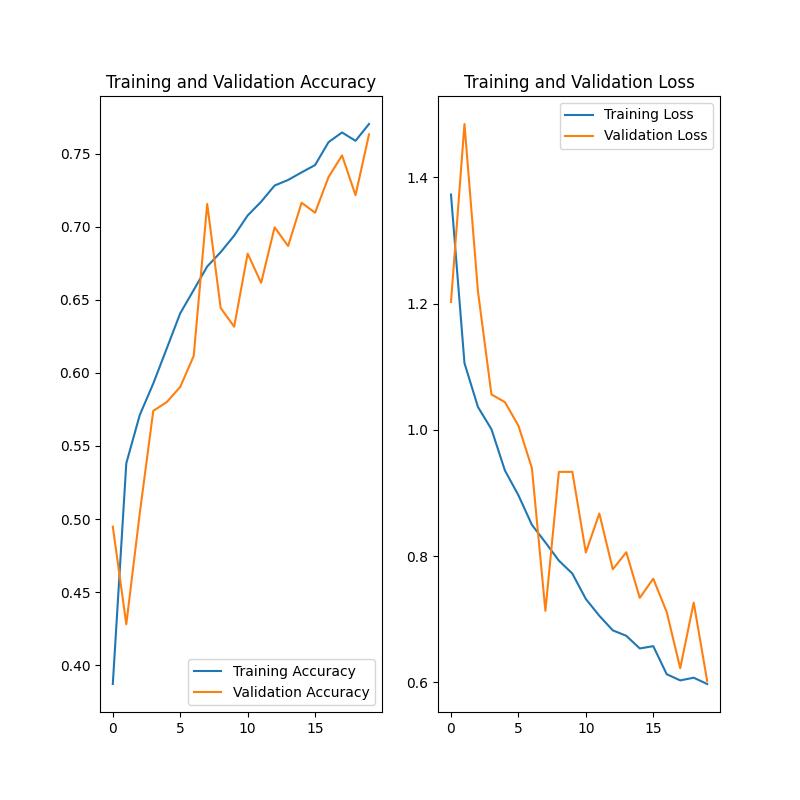
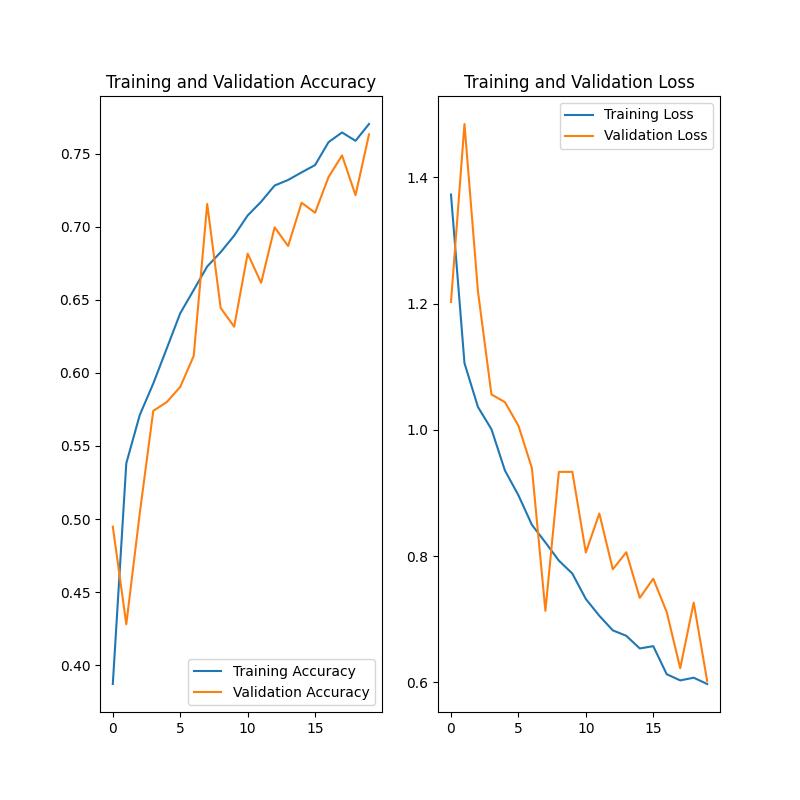
Posiadam wytrenowaną sieć neuronową która w zbiorze danych testowych pokazuje że potrafi dokonać przewidywania z 70% skutecznością spośród 5 klas.
W każdym folderze znajduje się 5 klas: ['car', 'cat', 'chicken', 'dog', 'horse']
Trening: 5x2000 zdjęć
Walidacja 5x500
i test na koniec 5x50
img_height, img_width = 150, 150
batch_size_train = 100
batch_size_validation = 50
batch_size_test = 10
epochs = 10
train_ds = tf.keras.utils.image_dataset_from_directory(
"train",
image_size=(img_height, img_width),
batch_size=batch_size_train
)
val_ds = tf.keras.utils.image_dataset_from_directory(
"validation",
image_size=(img_height, img_width),
batch_size=batch_size_validation
)
test_ds = tf.keras.utils.image_dataset_from_directory(
"test",
image_size=(img_height, img_width),
batch_size=batch_size_validation
)
model = tf.keras.Sequential(
[
tf.keras.layers.Rescaling(1. / 255),
tf.keras.layers.RandomFlip("horizontal", input_shape=(img_height, img_width, 3)),
tf.keras.layers.RandomRotation(0.3),
tf.keras.layers.RandomZoom(0.3),
tf.keras.layers.Conv2D(16, 3, activation="relu"),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation="relu"),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, activation="relu"),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(128, 3, activation="relu"),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax')
]
)
model.compile(
optimizer="adam",
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy']
)
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
model.evaluate(test_ds)
Problem w tym że po zapisaniu modelu i skonwertowania go do .TFLITE
model.save(foldername + '/' + 'myModel.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open(foldername + "/model.tflite", 'wb') as f:
f.write(tflite_model)
Jak wykonam jakieś przewidywania i podaje przykładowe obrazki (nawet bezpośrednio z trenignu), ale należące bezpośrednio do klas to wyniki zazwyczaj są zbliżone do tych samych
I w większym przypadku wskazują na jedną klasę, natomiast reszta jest z zbliżonym prawdopodobieństwem
Jest mniej więcej tak na klasy: [15% 40% 15% 15% 15%]
Ktoś wie z czego może to wynikać ? Jak temu zaradzić ? Albo gdzie jest błąd w procesie uczenia że zawsze wskazuje na te same klasy
Był bym wdzięczny za pomoc
- gif.jpg (46 KB) - ściągnięć: 5

{kind=link}