Kolejny etap za mną. Dodałem obsługę natywnych binarek kompilowanych z kodu C++. Zaimplementowałem jednakowy generator liczb pseudolosowych na każdej obsługiwanej platformie (JVM, OpenCL, native).
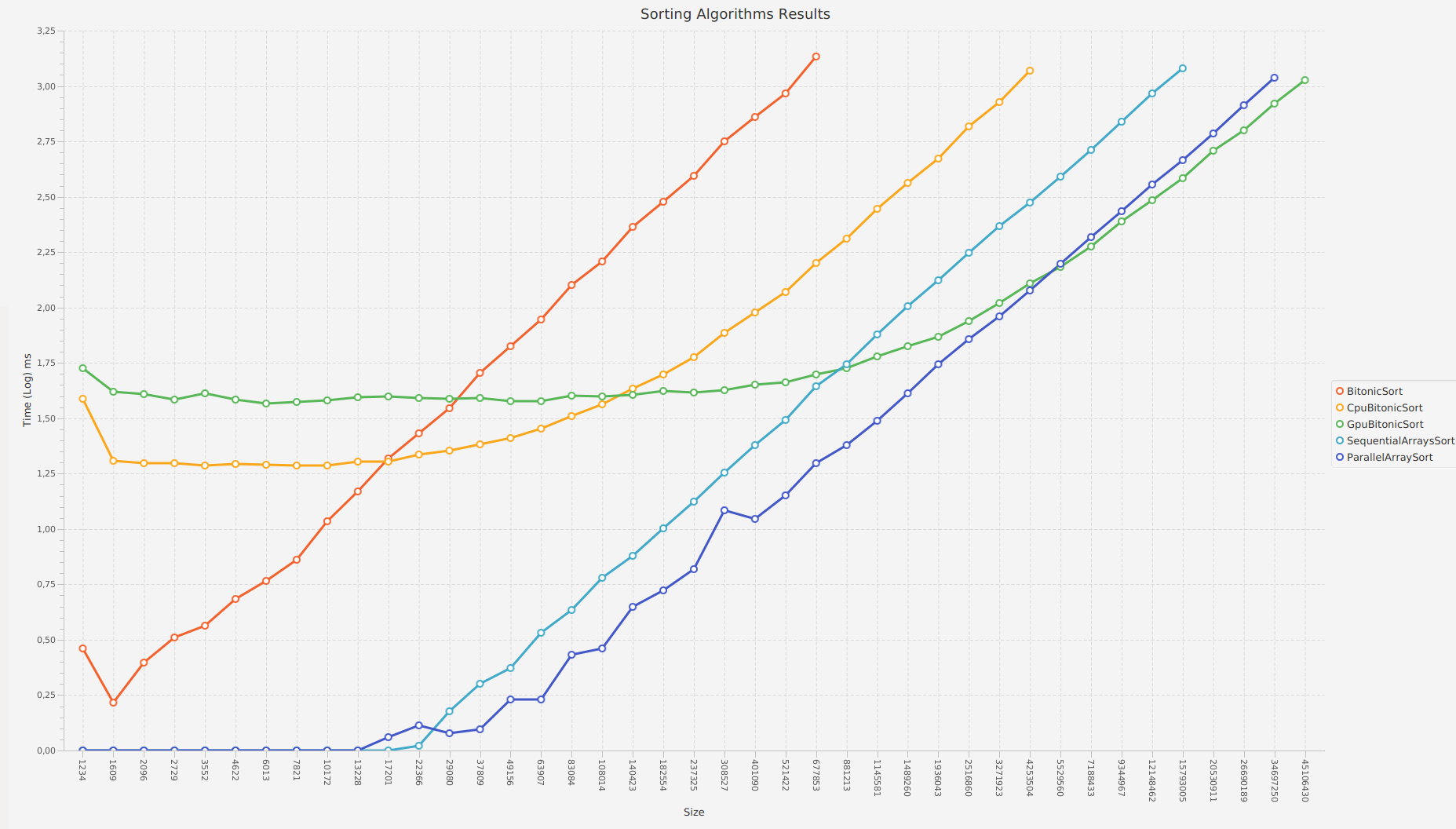
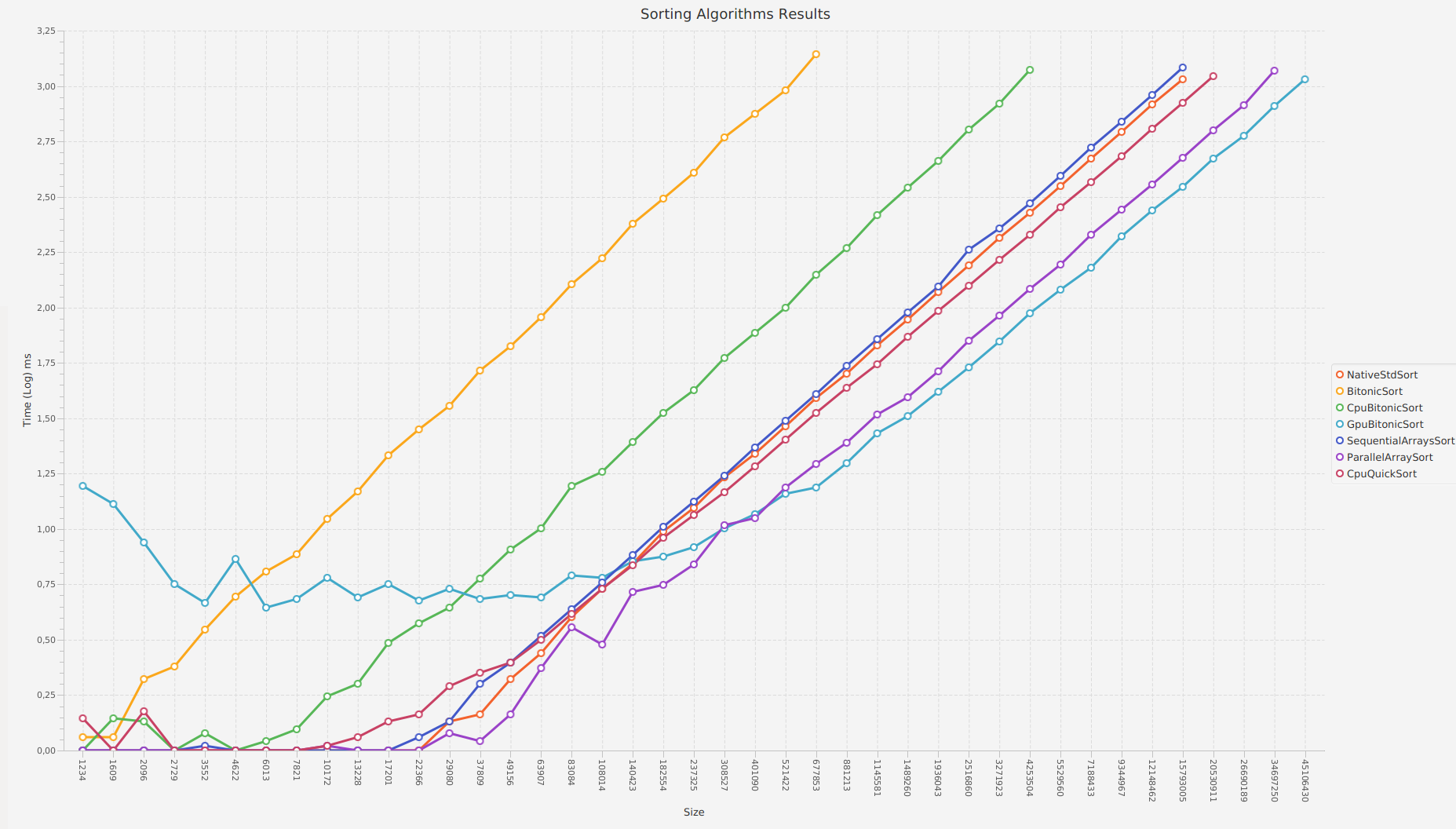
Wyniki benchmarka (dla danego rozmiaru wygenerowane tablica wejściowa zawiera te same losowe wartości dla każdego typu testu):
Kopiuj
Size: 1234
Sort name: NativeStdSort, time: 0.0 ms
Sort name: BitonicSort, time: 1.1 ms
Sort name: CpuBitonicSort, time: 0.85 ms
Sort name: GpuBitonicSort, time: 4.15 ms
Sort name: SequentialArraysSort, time: 0.05 ms
Sort name: ParallelArraySort, time: 0.05 ms
Sort name: CpuQuickSort, time: 0.7 ms
Size: 1609
Sort name: NativeStdSort, time: 0.0 ms
Sort name: BitonicSort, time: 1.05 ms
Sort name: CpuBitonicSort, time: 0.75 ms
Sort name: GpuBitonicSort, time: 3.6 ms
Sort name: SequentialArraysSort, time: 0.1 ms
Sort name: ParallelArraySort, time: 0.1 ms
Sort name: CpuQuickSort, time: 0.75 ms
Size: 2096
Sort name: NativeStdSort, time: 0.0 ms
Sort name: BitonicSort, time: 2.4 ms
Sort name: CpuBitonicSort, time: 0.55 ms
Sort name: GpuBitonicSort, time: 3.4 ms
Sort name: SequentialArraysSort, time: 0.15 ms
Sort name: ParallelArraySort, time: 0.1 ms
Sort name: CpuQuickSort, time: 0.8 ms
Size: 2729
Sort name: NativeStdSort, time: 0.0 ms
Sort name: BitonicSort, time: 2.3 ms
Sort name: CpuBitonicSort, time: 0.55 ms
Sort name: GpuBitonicSort, time: 3.5 ms
Sort name: SequentialArraysSort, time: 0.1 ms
Sort name: ParallelArraySort, time: 0.15 ms
Sort name: CpuQuickSort, time: 0.65 ms
Size: 3552
Sort name: NativeStdSort, time: 0.0 ms
Sort name: BitonicSort, time: 3.2 ms
Sort name: CpuBitonicSort, time: 0.9 ms
Sort name: GpuBitonicSort, time: 3.8 ms
Sort name: SequentialArraysSort, time: 0.25 ms
Sort name: ParallelArraySort, time: 0.25 ms
Sort name: CpuQuickSort, time: 0.75 ms
Size: 4622
Sort name: NativeStdSort, time: 0.0 ms
Sort name: BitonicSort, time: 4.4 ms
Sort name: CpuBitonicSort, time: 1.0 ms
Sort name: GpuBitonicSort, time: 3.65 ms
Sort name: SequentialArraysSort, time: 0.25 ms
Sort name: ParallelArraySort, time: 0.25 ms
Sort name: CpuQuickSort, time: 0.65 ms
Size: 6013
Sort name: NativeStdSort, time: 0.0 ms
Sort name: BitonicSort, time: 5.8 ms
Sort name: CpuBitonicSort, time: 1.2 ms
Sort name: GpuBitonicSort, time: 4.35 ms
Sort name: SequentialArraysSort, time: 0.3 ms
Sort name: ParallelArraySort, time: 0.3 ms
Sort name: CpuQuickSort, time: 0.8 ms
Size: 7821
Sort name: NativeStdSort, time: 0.05 ms
Sort name: BitonicSort, time: 7.05 ms
Sort name: CpuBitonicSort, time: 1.3 ms
Sort name: GpuBitonicSort, time: 4.0 ms
Sort name: SequentialArraysSort, time: 0.5 ms
Sort name: ParallelArraySort, time: 0.4 ms
Sort name: CpuQuickSort, time: 0.95 ms
Size: 10172
Sort name: NativeStdSort, time: 0.0 ms
Sort name: BitonicSort, time: 10.6 ms
Sort name: CpuBitonicSort, time: 1.9 ms
Sort name: GpuBitonicSort, time: 3.8 ms
Sort name: SequentialArraysSort, time: 0.7 ms
Sort name: ParallelArraySort, time: 0.45 ms
Sort name: CpuQuickSort, time: 1.15 ms
Size: 13228
Sort name: NativeStdSort, time: 0.0 ms
Sort name: BitonicSort, time: 14.05 ms
Sort name: CpuBitonicSort, time: 2.3 ms
Sort name: GpuBitonicSort, time: 4.15 ms
Sort name: SequentialArraysSort, time: 0.65 ms
Sort name: ParallelArraySort, time: 0.65 ms
Sort name: CpuQuickSort, time: 1.15 ms
Size: 17201
Sort name: NativeStdSort, time: 0.6 ms
Sort name: BitonicSort, time: 20.05 ms
Sort name: CpuBitonicSort, time: 2.95 ms
Sort name: GpuBitonicSort, time: 4.3 ms
Sort name: SequentialArraysSort, time: 1.0 ms
Sort name: ParallelArraySort, time: 0.7 ms
Sort name: CpuQuickSort, time: 1.3 ms
Size: 22366
Sort name: NativeStdSort, time: 1.0 ms
Sort name: BitonicSort, time: 26.0 ms
Sort name: CpuBitonicSort, time: 3.1 ms
Sort name: GpuBitonicSort, time: 4.0 ms
Sort name: SequentialArraysSort, time: 1.15 ms
Sort name: ParallelArraySort, time: 0.55 ms
Sort name: CpuQuickSort, time: 1.35 ms
Size: 29080
Sort name: NativeStdSort, time: 1.3 ms
Sort name: BitonicSort, time: 34.2 ms
Sort name: CpuBitonicSort, time: 4.55 ms
Sort name: GpuBitonicSort, time: 3.9 ms
Sort name: SequentialArraysSort, time: 1.6 ms
Sort name: ParallelArraySort, time: 0.8 ms
Sort name: CpuQuickSort, time: 1.9 ms
Size: 37809
Sort name: NativeStdSort, time: 1.65 ms
Sort name: BitonicSort, time: 49.25 ms
Sort name: CpuBitonicSort, time: 6.05 ms
Sort name: GpuBitonicSort, time: 4.7 ms
Sort name: SequentialArraysSort, time: 2.0 ms
Sort name: ParallelArraySort, time: 1.15 ms
Sort name: CpuQuickSort, time: 2.2 ms
Size: 49156
Sort name: NativeStdSort, time: 2.4 ms
Sort name: BitonicSort, time: 64.25 ms
Sort name: CpuBitonicSort, time: 8.1 ms
Sort name: GpuBitonicSort, time: 4.25 ms
Sort name: SequentialArraysSort, time: 2.7 ms
Sort name: ParallelArraySort, time: 1.65 ms
Sort name: CpuQuickSort, time: 2.5 ms
Size: 63907
Sort name: NativeStdSort, time: 3.0 ms
Sort name: BitonicSort, time: 84.58333333333333 ms
Sort name: CpuBitonicSort, time: 9.7 ms
Sort name: GpuBitonicSort, time: 5.2 ms
Sort name: SequentialArraysSort, time: 3.55 ms
Sort name: ParallelArraySort, time: 1.95 ms
Sort name: CpuQuickSort, time: 3.25 ms
Size: 83084
Sort name: NativeStdSort, time: 5.0 ms
Sort name: BitonicSort, time: 121.66666666666667 ms
Sort name: CpuBitonicSort, time: 13.55 ms
Sort name: GpuBitonicSort, time: 5.1 ms
Sort name: SequentialArraysSort, time: 4.55 ms
Sort name: ParallelArraySort, time: 2.45 ms
Sort name: CpuQuickSort, time: 4.15 ms
Size: 108014
Sort name: NativeStdSort, time: 6.15 ms
Sort name: BitonicSort, time: 159.71428571428572 ms
Sort name: CpuBitonicSort, time: 17.5 ms
Sort name: GpuBitonicSort, time: 8.0 ms
Sort name: SequentialArraysSort, time: 5.95 ms
Sort name: ParallelArraySort, time: 3.65 ms
Sort name: CpuQuickSort, time: 5.15 ms
Size: 140423
Sort name: NativeStdSort, time: 7.8 ms
Sort name: BitonicSort, time: 229.0 ms
Sort name: CpuBitonicSort, time: 24.45 ms
Sort name: GpuBitonicSort, time: 6.55 ms
Sort name: SequentialArraysSort, time: 7.85 ms
Sort name: ParallelArraySort, time: 4.4 ms
Sort name: CpuQuickSort, time: 6.65 ms
Size: 182554
Sort name: NativeStdSort, time: 9.35 ms
Sort name: BitonicSort, time: 300.75 ms
Sort name: CpuBitonicSort, time: 32.2 ms
Sort name: GpuBitonicSort, time: 7.25 ms
Sort name: SequentialArraysSort, time: 10.3 ms
Sort name: ParallelArraySort, time: 5.95 ms
Sort name: CpuQuickSort, time: 8.35 ms
Size: 237325
Sort name: NativeStdSort, time: 12.55 ms
Sort name: BitonicSort, time: 387.3333333333333 ms
Sort name: CpuBitonicSort, time: 41.9 ms
Sort name: GpuBitonicSort, time: 9.25 ms
Sort name: SequentialArraysSort, time: 13.55 ms
Sort name: ParallelArraySort, time: 7.1 ms
Sort name: CpuQuickSort, time: 10.1 ms
Size: 308527
Sort name: NativeStdSort, time: 17.0 ms
Sort name: BitonicSort, time: 555.0 ms
Sort name: CpuBitonicSort, time: 58.27777777777778 ms
Sort name: GpuBitonicSort, time: 9.5 ms
Sort name: SequentialArraysSort, time: 17.9 ms
Sort name: ParallelArraySort, time: 8.55 ms
Sort name: CpuQuickSort, time: 14.5 ms
Size: 401090
Sort name: NativeStdSort, time: 21.55 ms
Sort name: BitonicSort, time: 737.5 ms
Sort name: CpuBitonicSort, time: 76.14285714285714 ms
Sort name: GpuBitonicSort, time: 12.0 ms
Sort name: SequentialArraysSort, time: 23.95 ms
Sort name: ParallelArraySort, time: 11.8 ms
Sort name: CpuQuickSort, time: 18.15 ms
Size: 521422
Sort name: NativeStdSort, time: 28.6 ms
Sort name: BitonicSort, time: 958.0 ms
Sort name: CpuBitonicSort, time: 99.45454545454545 ms
Sort name: GpuBitonicSort, time: 11.5 ms
Sort name: SequentialArraysSort, time: 31.6 ms
Sort name: ParallelArraySort, time: 14.8 ms
Sort name: CpuQuickSort, time: 24.35 ms
Size: 677853
Sort name: NativeStdSort, time: 38.8 ms
Sort name: BitonicSort, time: 1371.0 ms
Sort name: CpuBitonicSort, time: 137.875 ms
Sort name: GpuBitonicSort, time: 16.2 ms
Sort name: SequentialArraysSort, time: 41.75 ms
Sort name: ParallelArraySort, time: 18.4 ms
Sort name: CpuQuickSort, time: 31.2 ms
Size: 881213
Sort name: NativeStdSort, time: 50.25 ms
Sort name: CpuBitonicSort, time: 180.66666666666666 ms
Sort name: GpuBitonicSort, time: 17.8 ms
Sort name: SequentialArraysSort, time: 55.10526315789474 ms
Sort name: ParallelArraySort, time: 23.75 ms
Sort name: CpuQuickSort, time: 40.95 ms
Size: 1145581
Sort name: NativeStdSort, time: 67.0 ms
Sort name: CpuBitonicSort, time: 248.4 ms
Sort name: GpuBitonicSort, time: 24.35 ms
Sort name: SequentialArraysSort, time: 73.57142857142857 ms
Sort name: ParallelArraySort, time: 28.8 ms
Sort name: CpuQuickSort, time: 54.31578947368421 ms
Size: 1489260
Sort name: NativeStdSort, time: 89.25 ms
Sort name: CpuBitonicSort, time: 330.0 ms
Sort name: GpuBitonicSort, time: 30.35 ms
Sort name: SequentialArraysSort, time: 96.0909090909091 ms
Sort name: ParallelArraySort, time: 36.6 ms
Sort name: CpuQuickSort, time: 71.78571428571429 ms
Size: 1936043
Sort name: NativeStdSort, time: 117.11111111111111 ms
Sort name: CpuBitonicSort, time: 437.6666666666667 ms
Sort name: GpuBitonicSort, time: 39.35 ms
Sort name: SequentialArraysSort, time: 125.75 ms
Sort name: ParallelArraySort, time: 47.05 ms
Sort name: CpuQuickSort, time: 94.72727272727273 ms
Size: 2516860
Sort name: NativeStdSort, time: 155.71428571428572 ms
Sort name: CpuBitonicSort, time: 608.5 ms
Sort name: GpuBitonicSort, time: 51.0 ms
Sort name: SequentialArraysSort, time: 182.66666666666666 ms
Sort name: ParallelArraySort, time: 63.6875 ms
Sort name: CpuQuickSort, time: 122.0 ms
Size: 3271923
Sort name: NativeStdSort, time: 207.4 ms
Sort name: CpuBitonicSort, time: 795.0 ms
Sort name: GpuBitonicSort, time: 65.0 ms
Sort name: SequentialArraysSort, time: 227.6 ms
Sort name: ParallelArraySort, time: 85.5 ms
Sort name: CpuQuickSort, time: 160.85714285714286 ms
Size: 4253504
Sort name: NativeStdSort, time: 270.0 ms
Sort name: CpuBitonicSort, time: 1095.0 ms
Sort name: GpuBitonicSort, time: 86.83333333333333 ms
Sort name: SequentialArraysSort, time: 295.75 ms
Sort name: ParallelArraySort, time: 112.11111111111111 ms
Sort name: CpuQuickSort, time: 209.6 ms
Size: 5529560
Sort name: NativeStdSort, time: 355.3333333333333 ms
Sort name: GpuBitonicSort, time: 110.7 ms
Sort name: SequentialArraysSort, time: 394.0 ms
Sort name: ParallelArraySort, time: 147.14285714285714 ms
Sort name: CpuQuickSort, time: 277.0 ms
Size: 7188433
Sort name: NativeStdSort, time: 470.6666666666667 ms
Sort name: GpuBitonicSort, time: 139.5 ms
Sort name: SequentialArraysSort, time: 525.5 ms
Sort name: ParallelArraySort, time: 193.83333333333334 ms
Sort name: CpuQuickSort, time: 363.3333333333333 ms
Size: 9344967
Sort name: NativeStdSort, time: 616.5 ms
Sort name: GpuBitonicSort, time: 191.16666666666666 ms
Sort name: SequentialArraysSort, time: 695.5 ms
Sort name: ParallelArraySort, time: 250.25 ms
Sort name: CpuQuickSort, time: 474.3333333333333 ms
Size: 12148462
Sort name: NativeStdSort, time: 821.5 ms
Sort name: GpuBitonicSort, time: 246.2 ms
Sort name: SequentialArraysSort, time: 921.5 ms
Sort name: ParallelArraySort, time: 335.6666666666667 ms
Sort name: CpuQuickSort, time: 628.5 ms
Size: 15793005
Sort name: NativeStdSort, time: 1082.0 ms
Sort name: GpuBitonicSort, time: 322.25 ms
Sort name: SequentialArraysSort, time: 1223.0 ms
Sort name: ParallelArraySort, time: 446.3333333333333 ms
Sort name: CpuQuickSort, time: 832.0 ms
Size: 20530911
Sort name: GpuBitonicSort, time: 435.0 ms
Sort name: ParallelArraySort, time: 593.0 ms
Sort name: CpuQuickSort, time: 1091.0 ms
Size: 26690189
Sort name: GpuBitonicSort, time: 558.5 ms
Sort name: ParallelArraySort, time: 761.0 ms
Size: 34697250
Sort name: GpuBitonicSort, time: 769.0 ms
Sort name: ParallelArraySort, time: 1061.0 ms
Size: 45106430
Sort name: GpuBitonicSort, time: 991.0 ms
Size: 58638364
Sort name: GpuBitonicSort, time: 1296.0 ms






{kind=link}
{kind=link}
satirev