chciałbym się podpytać, jak u was w projektach wygląda sprawa modularyzacji. Ja za każdym razem mam tak, że otwieram kod mikroserwisu, widzę pakiet typu "controllers" posiadający 40 plików, katalog "model" posiadający ponad 200 plików, wszystko publiczne, wszystko gada ze wszystkim.
Staramy się podążać za clean architecture:
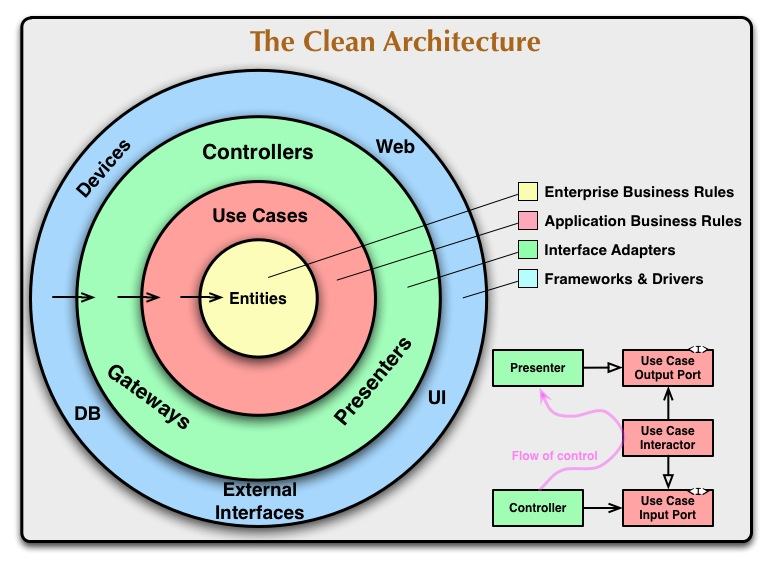
Na poziomie organizacji kodu wygląda to tak, że każdy nasz mikroserwis posiada "moduły" (foldery/jednostki kompilacji/przestrzenie nazw, de facto warstwy aplikacji):
- Domain (encje);
- Application (implementacje UseCasów, czyli klasy obsługujące commandy z naszego command dispatchera oraz interfejsy repozytoriów, klientów zewnętrznych API, itp.);
- Infrastructure (implementacje powyższych, klasy pomocnicze);
- Web (kontrolery);
- Consumer (konsument kafki)
- Producer (producent kafki)
W każdym module oczywiście są stosowane modyfikatory dostępu, i publiczne jest to, czego pozostałe moduły używają, a nie wszystko. Problem z widocznością w testach rozwiązujemy przez InternalsVisibleTo.
Przepływ jest taki: request HTTP/event kafki -> UseCase -> a ten już robi, co trzeba, np. z repozytorium wczytuje encje, potem wywołuje jakieś zewnętrzne API, potem zapisuje zaktualizowaną encję (co może wyprodukować jakiś wyjściowy event kafki).
Taka struktura aplikacji jest narzucona w szablonie, więc jak ktoś kliknie tworzenie nowej aplikacji w backstage, to dostanie to wszystko za darmo - musi tylko pobrać nowe repozytorium na kompa.
Oczywiście zdarzają się tacy, którzy z tym walczą, bo im "taki podział jest niepotrzebny", bo "mają tylko jeden endpoint", i łączą sobie wszystkie warstwy w jedną, tyle że potem ani wsparcia od nas nie maja, Security się czepia, no i jak dostaną słabą ocenę na backstage, to i ich osobisty Engineering Manager zacznie zadawać pytania.
Tak więc rebeliantów coraz mniej.
Naszło mnie takie przemyślenie, że odkąd zaczęło być jakieś parcie na mikroserwisy to ludzie przestali się przejmować jego podziałem na moduły, bo przecież mikroserwis sam w sobie ma reprezentować jeden bounded context.
Bynajmniej, spaghetti było zawsze. Dopiero w firmach, w których są mikroserwisy zauważam dbanie o utrzymywalność kodu i ogólnie o dobre praktyki.
Są event stormingi, które mają odkrywać bounded contexty w aplikacji, ale w praktyce nie widziałem, żeby ktoś to stosował. Bo jakby to miało działać? Pewnego dnia miałby przyjść do nas architekt i powiedzieć: "no słuchajcie, za duży ten serwis, to sobie zrobimy event storming i go podzielimy"?
Być może tak, ale metoda wrzucania wszystkiego do jednego worka, a potem ewentualnego wydzielania wydaje mi się szalenie nieefektywna. Prawdopodobnie lepiej byłoby, gdyby przed implementacją jakiegoś ficzera zastanowić się, do którego mikroserwisu on pasuje, a jeśli do żadnego, to utworzyć nowy.
W projektach, w których pracowałem to zazwyczaj serwisy osiągały takie rozmiary, że nie dało się już tego podzielić i sensownie z tym pracować, więc przepisywano na kilka mniejszych serwisów. Stąd też moje pytanie czy to ja mam takiego pecha i trafiam do takich projektów, gdzie nigdy nie ma sensownego podziału czy to po prostu standard w naszej branży i nikt się tym nie przejmuje?
Może niekoniecznie masz pecha, co zawsze wybierasz złe branże albo złe typy firm.
Pomijając dyskusję czy 40 plików z logiką to "mikro", burdel jest takim smutnym branżowym standardem. Podział na moduły nie jest trudny jeżeli zaczyna się od poznania problemu, zaprojektowania rozwiązania i dopiero się to rozwiązanie implementuje. Tylko w rzeczywistości ten naturalny wydawałoby się porządek rzadko kiedy jest stosowany. Implementacja zaczyna się od razu, projektowanie w najlepszym razie jest robione w trakcie implementacji, a jak już jest zrobione, to rozpoznawana jest domena. Wtedy, już w warunkach zbliżających się terminów dostosowuje się implementację, żeby robiła coś innego, niż wydawało się że ma robić i powstaje burdel.
Standardy są jak idole - każdy ma takich, na jakich zasługuje. :-)











{kind=link}
przy dużym monolicie ktoś w koncu kiedyś powie "dość"- w sensie powie i co dalej? prędzej będzie żądanie o dopisanie testów niż o zmianę architektury monolitu.