Mamy serwis A i serwis B komunikujące się restem. Serwis A zleca coś do B po czym B odpowiada 201/202 następnie a kończy transakcję i po pewnym
czasie B wraca z callbackiem do A, że zrobił co miał zrobić. Pytanie co w przypadku gdy B zrobi callback szybciej niż A zakończy transakcję (wtedy callback nie zostanie poprawnie obsłużony i pewnie będzie 404 bo A jeszcze nie dokończył transakcji i np. nie zapisał orderu)?
Powinniśmy się na coś takiego zabezpieczać? Wiem, że jest outbox pattern itd. ale załóżmy, że wszystko jest restem i nie bieżemy pod uwagę tego patternu.
- Rejestracja:około 11 lat
- Ostatnio:około miesiąc
- Lokalizacja:Gdańsk
0

- Rejestracja:około 21 lat
- Ostatnio:prawie 3 lata
- Lokalizacja:Space: the final frontier
- Postów:26433
2
Zlecaj akcje w B dopiero kiedy A jest w stanie obsłużyć callback? Tym bardziej że co jak transakcja w A się wywali i request do B w ogóle nie powinien był pójść bo teraz masz niespójny stan, w A operacja sie wycofała w B nie.
edytowany 1x, ostatnio: Shalom

- Rejestracja:ponad 6 lat
- Ostatnio:11 dni
- Lokalizacja:Silesia/Marki
- Postów:5505
2
Nie pamiętam już sytuacji ale kiedyś w zespole przekonaliśmy się że robienie strzału do innego serwisu w transakcji to nie jest dobry pomysł. Ogólnie jeśli chcesz żeby twoja baza danych wytrzymała duże obciążenie to transakcje powinny być maksymalnie krótkie. A strzały do innych mikroserwisów mogą zająć dużo czasu
Jak chcesz coś pobrać z serwisu B to pobierz to przed transakcją. Jak chcesz powiedzieć że A zapisał to zrób to po transakcji. Oczywiście jest pytanie co jak A padnie i nie poinformuje B. Wszystko zależy jak ważna to jest informacja. czy B pyta się sa co jakiś czas.
Jak się B nie pyta i to jest ważna informacja to możliwe że ta informacja powinna trafić na jakąś kolejkę lub inną dedykowaną usługę do powiadamiania
edytowany 4x, ostatnio: cerrato

- Rejestracja:około 11 lat
- Ostatnio:około miesiąc
- Lokalizacja:Gdańsk
0
@Skoq: właśnie o to chodzi, że nie mam kontroli nad serwisem B i tych serwisów może być wiele (wiele integratorów)
i nie chce im narzucać tego jak mają implementować chociaż api każdy z nich będzie wystawiał takie samo. Jeden integrator
np. może przetworzyć w ciągu 5min i zrobić callback jak tak zaimplementuje a drugi licząc w ms jeżeli jest bardzo szybki.
- Rejestracja:ponad 6 lat
- Ostatnio:11 dni
- Lokalizacja:Silesia/Marki
- Postów:5505
1
lookacode1 napisał(a):
W sumie to nie jest relacyjna baza danych tylko mongo i na końcu jest save do bazy:
- A -> B
- A got response
- A save
No to ja nie rozumie w czym problem. W Scali było by to np (Zakłądając ze wszystko zwraca Future'y)
for {
response <- clientB.call
result <- repo.save(response)
} yield result
lub
clientB.call.flatMap { response =>
repo.save(response)
}
Jak używasz mongo to pewnie piszesz w JS i trzeba zamienienić flatMap na then.
Daj przykładowy kod bo tak z opisu słowno muzycznego nie rozumiem gdzie jest problem
- Rejestracja:około 11 lat
- Ostatnio:około miesiąc
- Lokalizacja:Gdańsk
0
@KamilAdam: Ok ale co jak np. baza będzie obciążona w związku z tym save potrwa trochę dłużej
i callback od B przyjdzie szybciej i baza nie jest "gotowa" na jego obsłużenie bo jeszcze nie ma tam danych,
które powinny być?
Jak używasz mongo to pewnie piszesz w JS
Niee to java jest aż tak mi nie odbiło xd
edytowany 1x, ostatnio: lukascode

Jak „save” potrwa „trochę dłużej”, to blokujesz wątek serwera na wskutek czego pewnego dnia wieczorem Twój serwis padnie :)
- Rejestracja:ponad 6 lat
- Ostatnio:11 dni
- Lokalizacja:Silesia/Marki
- Postów:5505
1
@lookacode1: daj kod bo nie rozumiem o czym mówisz. W moim przypadku najpier robię call do B a dopiero jak dostanę dane to robię zapis.
callback od B przyjdzie szybciej i baza nie jest "gotowa" na jego obsłużenie bo jeszcze nie ma tam danych,
Czemu baza ma być gotowa na obsłużenie? przecież callbacka obsługuje A.
Dobra chyba rozumiem.
Mamy dwudziesty pierwszy wiek (wiem że dopiero początek, i na świecie dalej istnieją barbarzyńcy), więc zapomnij słowo calback. Skoro masz Javę to najlepiej byłoby jakbyś miał api które zwraca ci CompletableFuture, a nie jakieś prymitywne callbacki. czyli:
CompletableFuture responceFuture = clientB.call();
repo.save(someData);
responceFuture.thenApply(response -> tenCallback co potrzebuje czytać z bazy);// bogowie czemu ta metod anie może być nazwana `map`?
Teraz nie wykonasz callbacka dopóki nie zapiszesz do bazy
edytowany 4x, ostatnio: KamilAdam
to dobrze bo nie chciało mi się pisać kodu ;)
- Rejestracja:około 11 lat
- Ostatnio:około miesiąc
- Lokalizacja:Gdańsk
0
@KamilAdam: Z tym, że to dalej jest synchronicznie. A jak B będzie miało taką logikę, że przetwarza wszystkie ordery pod koniec dnia
i robi callbacki? Chodzi o to, że A zleca do B jakiś order do zrobienia i B odpowiada od razu, że ok przyjąłem przetworzę to w swoim czasie.
Wtedy A dostaję od razu odpowiedź i dopiero zapisuje to bazy (bo w response jest id od B, które musi być zapisane). I takich serwisów B spiętych z
A może być wiele i nie możemy narzucać to jak one pod spodem mają zaimplementować to api. Dlatego np. B1 jeśli zechce to może przetwarzać ordery
pod koniec dnia i robić callbacki (i tu nie ma problemu bo do bazy po stronie A już dawno dane się zapisały) a B2 może instantowo przetworzyć i może powstać
wyścig, że callback do A będzie szybszy.
edytowany 2x, ostatnio: lukascode
- Rejestracja:ponad 6 lat
- Ostatnio:11 dni
- Lokalizacja:Silesia/Marki
- Postów:5505
- Rejestracja:prawie 10 lat
- Ostatnio:około 3 godziny
- Postów:2363
0
Z tego co zrozumiałem, to kolega ma jakiś szerzy proces (wszak skądś się wzięła potrzeba zapisu w A i zainicjowania procesu w B), w ramach którego wykonywane są czynności w A i czynności w B.
Te czynności mogą się wykonywać równolegle (więc możliwe są przeploty AB i BA).
Dla ilustracji diagram. W A zaczyna się jakiś proces, który w pewnym momencie rozdziela się na 2 gałęzie , które trzeba kiedyś złączyć. Brakuje elementu kontrolującego przebieg tego procesu.
np. prostego automatu stanowego, czy "sagi" (używając nomenklatury DDD).
Bez kontroli przebiegu procesu zawsze będą jakieś techniczne problemy.
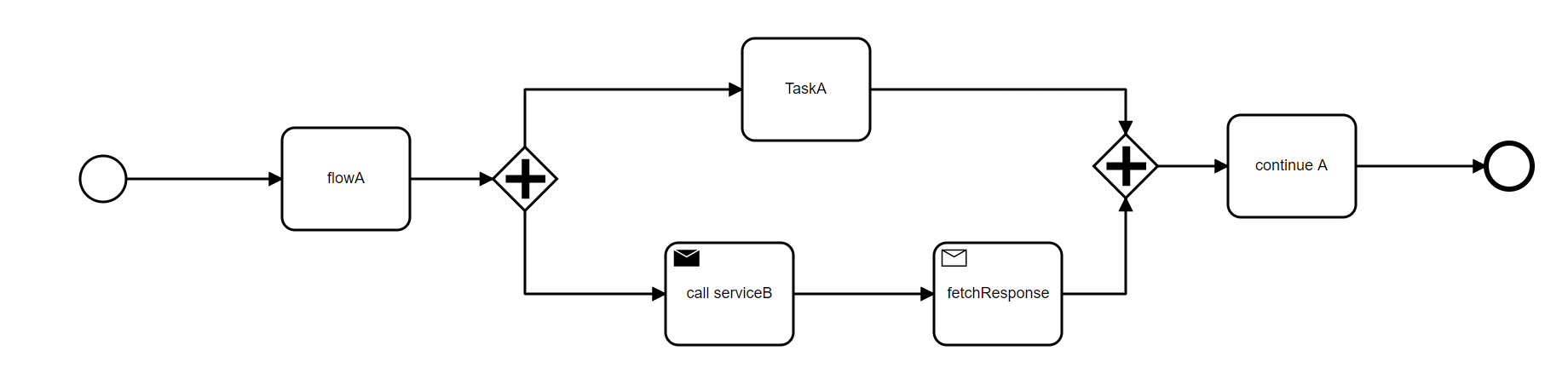
- screenshot-20220407163312.png (43 KB) - ściągnięć: 6
{kind=link}
- Rejestracja:prawie 17 lat
- Ostatnio:minuta
- Postów:1873
0
Brzmi jak „process manager” - jeżeli (4) wykona się przed (3), to odkładasz taki „request” na kolejce(*) i próbujesz wykonać później. Można to zrobić przynajmniej na 3 sposoby:
- Zadanie do przetworzenia zapisuje u siebie A w jakiejś kolejce
- A odpowiada jakimś 5xx i B ponawia po jakimś czasie (retry backoff) - czyli kolejka jest u B
- Robisz to asynchronicznie poprzez event bus, np. Kafkę - B zapisuje tam zadanie, A pobierze je, kiedy będzie gotowy
(*) - ta kolejka to w istocie może być jakaś tabelka + cron
Czy jest jakiś konkretny powód, dla którego w tym wypadku komunikacja B->A jest synchroniczna?
edytowany 4x, ostatnio: Charles_Ray
- Rejestracja:prawie 17 lat
- Ostatnio:minuta
- Postów:1873
0
lookacode1 napisał(a):
B to jest oddzielna usługa poza naszą infrastrukturą trochę jak np. korzystasz z bramki płatności to też jakiś callback dostajesz.
Nie znam całości procesu, ale w takim razie pozostaje opcja (A), co ma swoje zalety.
Jeszcze nie podoba mi się motyw z jakaś asynchroniczna transakcja - możesz rozwinąć?
- Rejestracja:około 11 lat
- Ostatnio:około miesiąc
- Lokalizacja:Gdańsk
0
Tak opcja, w której B ponawia wydaję się najprostsza więc pójdę w tym kierunku z tym, że A raczej będzie zwracać 400 Bad request z jakimś kodem not found. 5xx mi raczej nie pasuje bo to jest raczej błąd klienta, że podał jakiś identyfikator, który nie istnieje.
Asynchroniczna transakcja? Nie do końca rozumiem o co pytasz. Serwis A po prostu wykonuje strzał do B po czym zapisuje jakieś wyniki do mongo. To wszystko jest synchronicznie.
- Rejestracja:prawie 17 lat
- Ostatnio:minuta
- Postów:1873
0
To Ci się może przydać: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Retry-After
Uwaga: Generalnie „błąd klienta” to 4xx. Takich requestow nie ponawia się by default, bo to bez sensu (np. błędna autoryzacja).
Asynchroniczna transakcja? Nie do końca rozumiem o co pytasz. Serwis A po prostu wykonuje strzał do B po czym zapisuje jakieś wyniki do mongo. To wszystko jest synchronicznie.
Ale mam nadzieje, że serwis A nie czeka na ten callback z serwisu B? Co jeśli callback się nie wydarzy?
edytowany 1x, ostatnio: Charles_Ray
Niee nie czeka na callback.
- Rejestracja:około 11 lat
- Ostatnio:około miesiąc
- Lokalizacja:Gdańsk
0
A raczej będzie zwracać 400 Bad request z jakimś kodem not found. 5xx mi raczej nie pasuje bo to jest raczej błąd klienta, że podał jakiś identyfikator, który nie istnieje.
Tutaj mówiąc o błędzie klienta odniosłem się właśnie do 4xx tj. nie możemy przetworzyć callbacku bo podano jakiś id, którego A nie znalazł. Akurat w tym przypadku nawet nie wiem jak miałbym sprawdzić i rozróżnić czy nie znalazł dlatego, że po prostu nie ma czy dlatego, że A jeszcze nie zdążył przetworzyć i zapisać. Wiem, że zwykle 4xx się nie ponawia ale myślę, że dla 404 spokojnie można by było zrobić wyjątek i pewnie często tak się robi ze względu na czas propagacji pomiędzy systemami.

- Rejestracja:prawie 9 lat
- Ostatnio:ponad 2 lata
- Lokalizacja:UK
- Postów:2235
5
Widzę że dużo się tutaj dzieje. Mamy komunikację między serwisami, race conditions, HTTP requests chaining, proces asynchroniczny obejmujący więcej niż jeden serwis który nie jest koordynowany.
Właśnie do takich wyzwań powstały pewne dobre praktyki stosowane w systemach rozproszonych, i warto żebyś rozważył ich zastosowanie jeśli masz taką możliwość. Mowa przede wszystkim o zastosowaniu jakiejś kolejki i message-based communication oraz orkiestracja tego za pomocą process managera.
Ewentualnie możesz po stronie serwisu A użyć retry przy przyjmowaniu requestu od B, skoro wiesz że dane mogą nie być jeszcze dostępne. Ale to będzie jak leczenie objawów a nie przyczyny, bo- zakładając że Twój system ma więcej rozproszonych operacji- będziesz narażał się na szereg innych problemów. Podstawowym problemem jest to że jak sam piszesz masz jakąś transakcje w serwisie, a między czasie rozpoczynasz operacje w innym serwisie licząc na to że transakcja zdąży się wykonać (i zakończy się powodzeniem). To jedno z podstawowych wyzwań systemów rozproszonych, i do tego właśnie stosuje się process managers (lub sagas jeśli chcesz mieć również jakieś operacje kompensujące niepowodzenie).
edytowany 2x, ostatnio: Aventus
Shalom