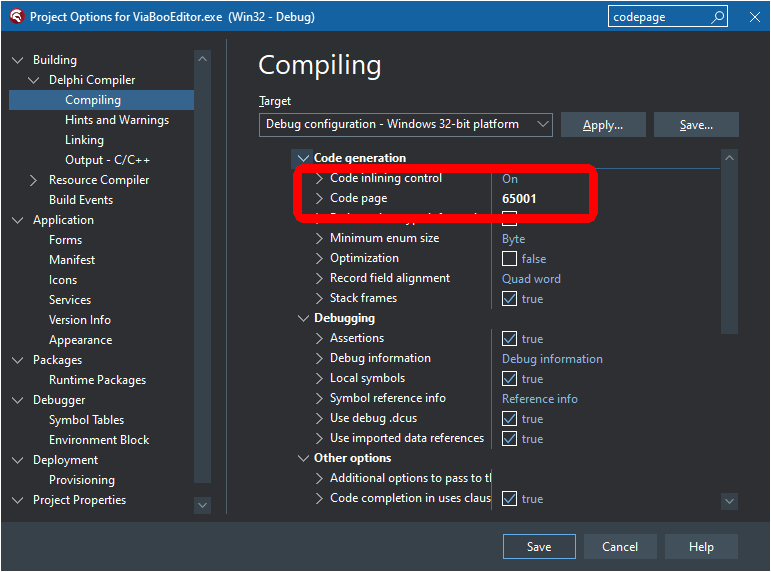
Mam plik tekstowy w którym po otwarciu w Notepadzie widzę polskie i czeskie litery.
Plik to zwykły plik txt.
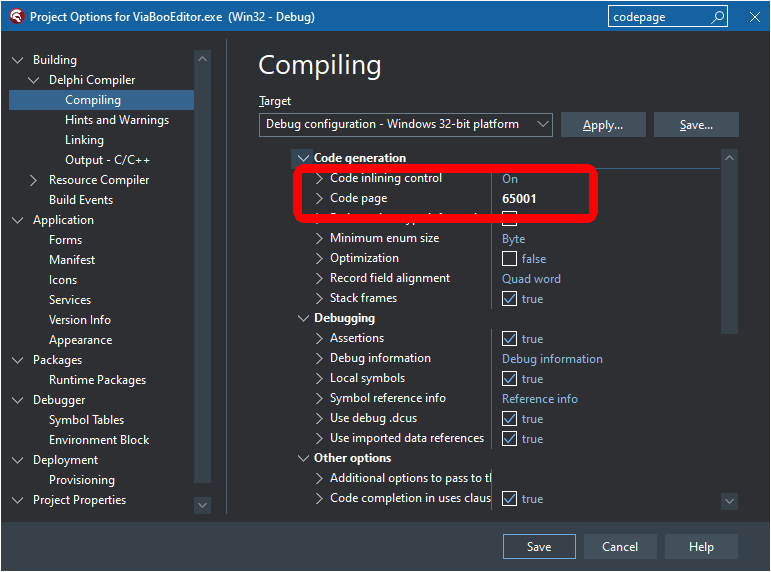
Niestety po załadowaniu do Memo zamiast czeskich i polskich znaków widzę krzaczki (zamiast jednego znaku - dwa dziwne znaki).
Co ciekawe po zapisaniu zawartości Memo do pliku poprzez Memo.Lines.SaveToFile
i otwarciu pliku w Notepadzie znowu wodzę litery polskie i czeskie.
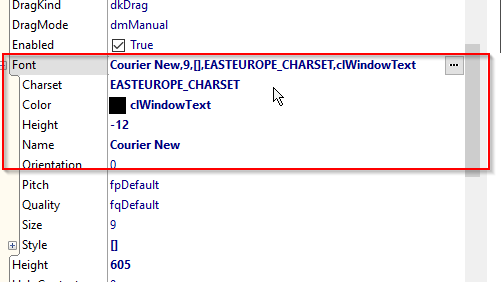
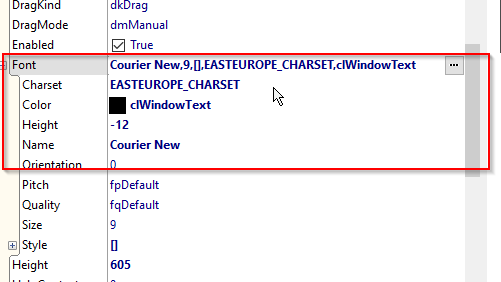
Czcionka w notatniku i Memo ta sama.
Gdzie szukać przyczyny?
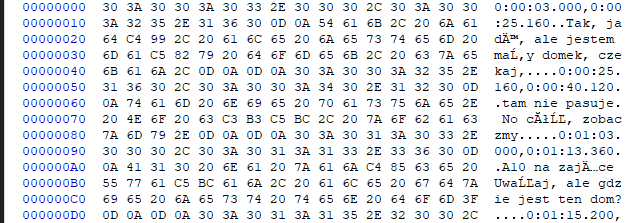
Sprawdziłem jeszcze plik w HexEdytorze i tam fakycznie widać, że każda olska litera kodowana jest na dwóch bajtach.
Wygląda to jak na obrazku i właśnie tak mi to pokazuje Memo. Jak temu zaradzic?
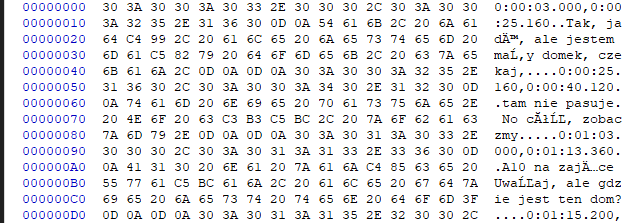
- screenshot-20220725213458.png (26 KB) - ściągnięć: 38



{kind=link}
{kind=link}
{kind=link}
katakrowakatakrowa