
Mam do napisania program do kompresji plików algorytmem LZ78 https://pl.wikipedia.org/wiki/LZ78 no i napisałem takie oto 2 funkcje:
void compress(const string& filein, const string& fileout) {
map<string, int> dict; int n = 1; string c{ "" }, result{}, content{}, line{}, przec{ "," };
dict[""] = 0;
ofstream wyj(fileout, ios::out);
ifstream inp(filein, ios::in);
if (!inp.good()) {
cout << "Something wrong";
return;
}
while (getline(inp, line)) {
for (string::iterator it = line.begin(); it != line.end(); ++it) {
if (!dict.count(c + *it)) {
if (c == "") {
content = *it;
result += "(0" + przec + content + ")";
dict.insert({ content, n });
}
else {
content = *it;
string x = to_string(dict[c]);
result += '(' + x + przec + content + ')';
dict.insert({ c + content,n });
c = "";
}
n++;
}
else {
c += *it;
if (it == line.end() - 1) {
//string x(c); //string x(1, *it);
result+='(' + to_string(dict[c]) + przec + ')'; //dict[x]
c = "";
}
}
}
wyj << result;
result = "";
wyj << endl;
}
inp.close();
wyj.close();
}
void decompress(const string& filein, const string& fileout) {
map<int, string> dict; int n = 1; string result{}, temp{}, line{};
dict[0] = "";
const std::regex reg(R"((\d+),(.{1}))");
std::pair<int, char> com{};
ofstream wyj(fileout);
ifstream inp(filein, ios::in);
if (!inp.good()) {
cout << "Something wrong"; return;
}
while (getline(inp, line)) {
for (std::smatch sm; std::regex_search(line, sm, reg); line = sm.suffix()) {
com = { std::stoi(sm.str(1)), sm.str(2)[0] };
if (com.first == 0) {
dict[n] = com.second;
result += com.second;
n++;
}
else if (com.second == ')') {
result += dict[com.first];
}
else {
auto search = dict.find(com.first);
temp += search->second + com.second;
result += temp;
dict[n] = temp;
temp = "";
n++;
}
}
wyj << result;
wyj << endl;
result = "";
}
inp.close();
wyj.close();
}
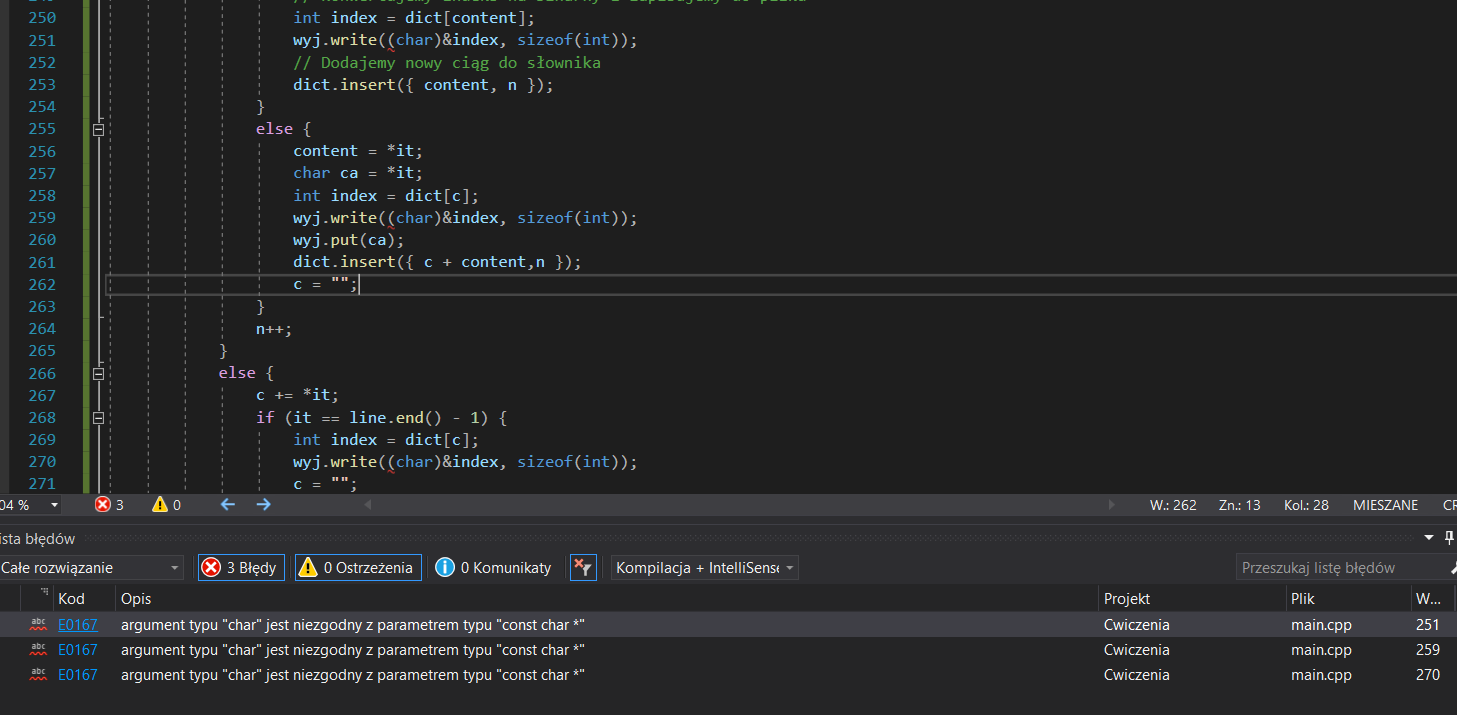
W sumie to działa dla tekstu, ale czy dałoby się nie zapisywać wartości w nawiasach (żeby niepotrzebnie nie zapisywać do pliku), żeby dało się odróżnić np. jak jest (1432,1) (indeks do słownika 1432 a znak '1') i do pliku móc zapisać 14321 odróżniając część 1432 i '1'. Wiem, że też da się jakoś kompresować zdjęcia, próbowałem otwierać przy pomocy ios::binary, ale chyba musiałbym przerobić program. Zastanawiam czy do czytania tych dziwnych znaczków ze zdjęcia nie potrzeba jakiegoś innego typu danych niż char/string?



{kind=link}