Cześć!
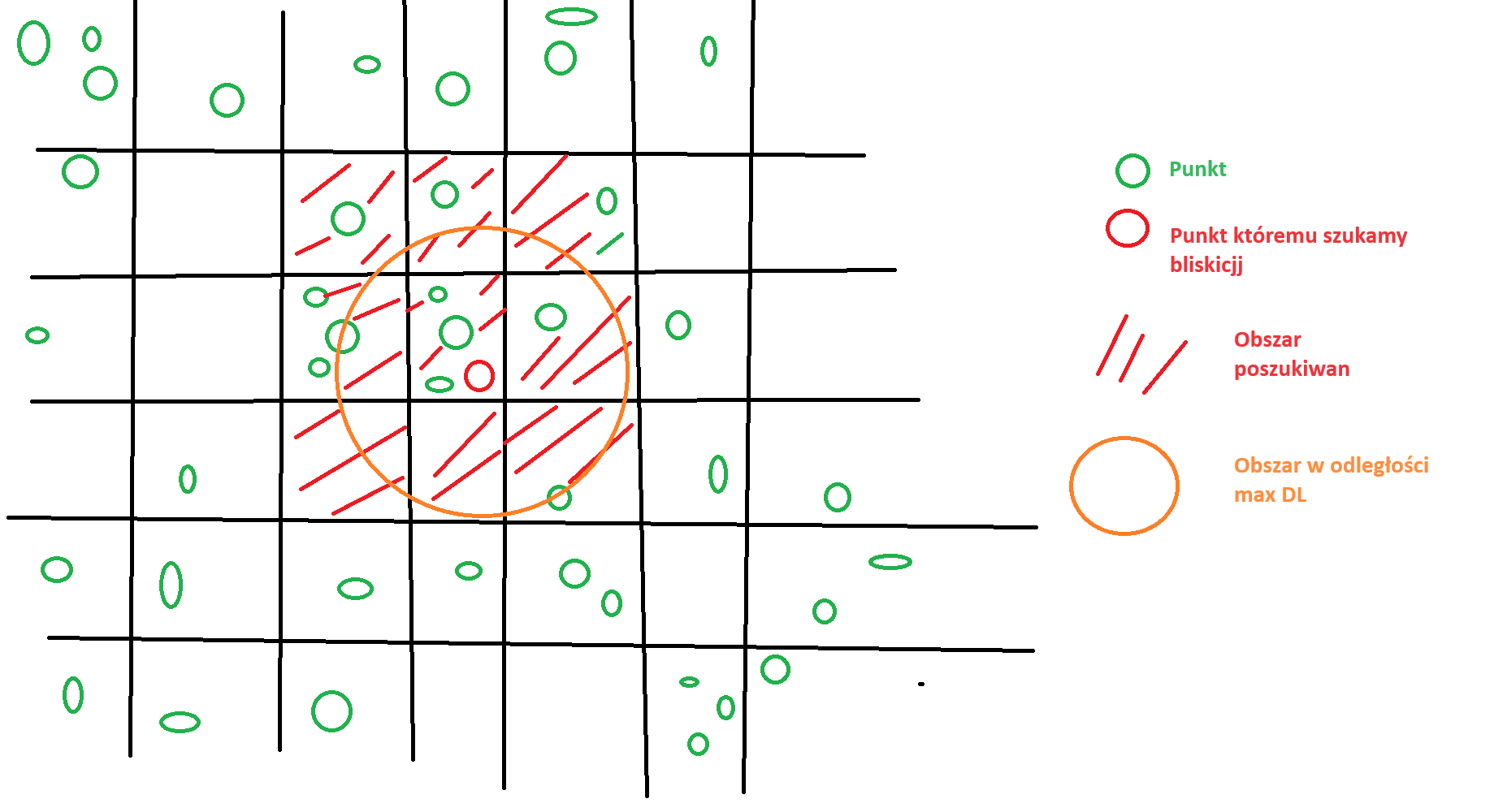
Ostatnimi czasy szkolę się z programowania w lispie (a konkretniej w jego odmianie AutoCAD), wydaje mi się że już osiągnąłem jakiś w miarę poziom. Pracuje obecnie nad czymś ciekawym (przynajmniej dla mnie :D) tj zaznaczam serię punktów w programie, i on znajduje 2 najbliższe punkty w zbiorze i jeżeli ich odległość nie przekracza podanej wartości dmax to tworzy koło z 3 punktów.
Generalnie kod działa dlatego w dziale nietuzinkowe tematy :D. I tak się zacząłem zastanawiać nad optymalnym podejściem do tego zagadnienia.
Jak widać niżej, obecnie mam podwójnego loopa punkt do punktu, z drobną optymalizacją. Jak punkt znaleziony to usuwa się z inner loopa.
I teraz się zastanawiam czy nie powinienem np podzielić jakoś zbioru punktów (screen niżej) np na połowę żeby nie loopować po wszystkich dla danego punktu. Tylko dzielenie tego na pół to też jakiś loop do wykonania :D
Jako że jestem geodetą to dużo mam takiej pracy na punktach z dużymi zbiorami danych.
Jakieś książki, posty, strony kanały na YT które polecacie do zabrania się za takie problemy?
(progn
(setq loopPtLst PtLst)
(foreach pt0 PtLst
(if (member pt0 loopPtLst)
(progn
(setq sortedDistLst (bc:CalcDist2D loopPtLst pt0 )) ;;subfunc
(if (and (< (cdr (nth 0 sortedDistLst)) dmax) (< (cdr (nth 1 sortedDistLst)) dmax ))
(progn
(setq pt1 (car(nth 0 sortedDistLst)))
(setq pt2 (car(nth 1 sortedDistLst)))
(setq loopPtLst (vl-remove pt0 loopPtLst))
(setq loopPtLst (vl-remove pt1 loopPtLst))
(setq loopPtLst (vl-remove pt2 loopPtLst))
)
)
(setq circPtR (bc:CalcCircle pt0 pt1 pt2))
(entmake (bc:makeCircle (car circPtR) (cdr circPtR)))
);progn if
);if
);foreach
);progn
;*******************************************************************************
; FUNCTION: bc:CalcDist2D
; DESCRIPTION: Calculate the 2D distance between selected point and listpoints. If distance is different than 0 point coordinates and distance is added to cons list.
; PARAMETERS: ptLst searchPt
; RETURNS: A list representing points coordinates and distances
;*******************************************************************************
(defun bc:CalcDist2D (ptLst searchPt / distlst distSpPt)
(setq seratchPtXY (list (nth 0 searchPt) (nth 1 searchPT) 0))
(setq distlst nil)
(foreach PtX ptLst
(setq PtXY (list (nth 0 PtX) (nth 1 PtX) 0))
(if (and (/= (setq distSpPt (distance PtXY seratchPtXY))0) (< distSpPt dmax))
(progn
(setq distlst (cons (cons PtX distSpPt) distlst))
)
)
)
(setq distlst (vl-sort distlst (function (lambda (a b) (< (cdr a) (cdr b))))))
distlst ; Return the list of distances
)


 na samym civilu kiedyś pracowaliśmy w firmie w której obecnie pracuje ale z tego samego powodu zrezygnowaliśmy i pracujemy teraz na zmiennikach typu ZWCad czy Brisccad :D
na samym civilu kiedyś pracowaliśmy w firmie w której obecnie pracuje ale z tego samego powodu zrezygnowaliśmy i pracujemy teraz na zmiennikach typu ZWCad czy Brisccad :D trzeba było z pracy wyjść żeby mozg zaczal pracować.
trzeba było z pracy wyjść żeby mozg zaczal pracować.