stryku
Wpisy stryku na mikroblogu

Prezent @Aryman1983 ośmielił mnie do pochwalenia się swoim kubkiem. Jestem z niego dumny tym bardziej, że narzeczona sama go dla mnie namalowała, no i ma smaczek ze świata C++. Kto ogarnął? (: #pozdrodlakumatychc++owcow


@Azarien: odnośnie ssania i size(), dokładnie :) Kubek jest trochę przestarzały bo MSVC od jakiegoś czasu wspiera: https://devblogs.microsoft.com/cppblog/two-phase-name-lookup-support-comes-to-msvc/
@Silv: dodam jeszcze, że jak chcesz się w to bardziej zagłębiać, to poczytaj o aggregate initialization
#cmakesl
(dla tych co nie wiedzą: staram się napisać nowy język skryptowy dla CMake)
Na wstępie chciałbym przeprosić za duży gif, no ale taki wyszedł. Jeżeli ktoś woli, to jest też filmik na YT:
tl;dr
Po raz pierwszy, CMakeSL jest w stanie zbudować sam siebie (bez testów) (:
To, co widzicie na gifie/filmie to:
0. Zbudowałem CMake ze zintegrowanym CMakeSL. Startujemy w katalogu z zainstalowanymi binarkami CMake.
- Klonujemy mastera CMakeSL z githuba.
- W repo CMakeSL obok skryptów
CMakeLists.txtsą skryptyCMakeLists.cmslnapisane w tym moim śmiesznym języku. - Używamy binarki CMake, zbudowanej ze wsparciem wykonywania CMakeSL, do zbudowania ściągniętego repo CMakeSL.
- Instalujemy zbudowanego CMakeSL i jego example.
- Używamy zbudowanej binarki CMakeSL do odpalenia hello worlda.
Powiem tak. CMakeSL jest dość prostym projektem, w kontekście budowania. Jest tam parę libek, instalowanie trzech binarek i odpalanie pythonowego skryptu generującego trochę kodu. Niemniej, jaram się dość mocno, bo projekt zaczyna umieć robić to, do czego został stworzony.
Przy tego typu projektach, moment, gdy program zaczyna opitalać sam siebie, jest dość satysfakcjonujący (:
Rzeczy, na które chciałbym zwrócić uwagę, a nie są oczywiste na pierwszy rzut oka:
optiony przekazane z linii poleceń są kompatybilne i ze starym CMake, i z CMakeSL, np.-DCMAKESL_WITH_TOOLS=ON- zaimplementowany został odpowiednik
add_custom_command, użyty do odpalania pythonowego skryptu. Tu można go zobaczyć w akcji - podział na pliki,
import/export: Skrypt, który jest potem importowany w wielu miejscach - na koniec to, na czym mi od początku zależało - działanie C++owych tooli (które nie potrzebują znać semantyki kodu) od ręki. Wszystkie skrypty
CMakeLists.cmslsą sformatowaneclang-formatem, z użyciem tego samego pliku.clang-format, który jest używany do formatowania kodu C++ w projekcie. Działają nawet rzeczy typu //clang-format: off. Jedynym mankamentem jest to, że poimportnastępna linia jest źle wcięta, ale jest to spowodowane tym, że chciałem używać tej samej wersjiclang-formata, której używa CMake - 6.0. Myślę, że tam importy po prostu nie są jeszcze wspierane.

#cmakesl
Żeby wpis miał sens muszę dać trochę abstraktu.
Dla tych co nie wiedzą: starm się napisać nowy język skryptowy dla CMake: github.com/stryku/cmakesl
Pracę podzieliłem na kilka większych etapów:
- [DONE] Wypuszczenia PoCa, pokazującego, że da się wpiąć ten język w codebase CMake.
- Znalezienie jakiegoś niedużego projektu w C++, korzystającego z CMake i przerobienie CMakeLists.txt'ów na CMakeLists.cmsl, napisanych w moim języku. Następnie rozwinięcie samego języka, żeby obsługiwał koncepty/syntax tam zawarty. Ostatnim etapem będzie integracja nowych ficzerów CMakeSL z samym CMake.
- Ostatnim etapem będzie przepisanie CMakeLists.txt'ów LLVM + Clang na mój język i tak jak wyżej -> rozwinięcie języka i integracja z CMake.
Aktualnie CMakeSL zbliża się do bycia feature-complete dla drugiego etapu. Doszło do niego sporo rzeczy i tu zaczyna się sedno tego wpisu.
Bardzo lubię Compiler Explorera. Jest to chyba najszybszy sposób, żeby sprawdzić co C++ odwala w niektórych sytuacjach.
Pomyślałem, że czegoś takiego brakuje w CMake, a skoro źródła CE są dostępne na licencji pozwalającej go sobie wziąć, pozmieniać i wypuścić coś swojego, to czemu by nie zrobić CMakeSL Explorera?
git clone i w 2h nahakowałem support dla CMakeSL. Próbkę możecie zobaczyć w gifie (:
Wiadomo, że CE jest głównie po to, żeby podglądać asma, a CMakeSL oczywiście nie jest kompilowalny do binarek. W CMakeSL Explorerze chciałbym dać możliwość budowania sobie drzewka CMakeLists.cmsl'ów. Jak w normalnym projekcie - masz główny folder projektu, gdzie masz główne CMakeLists. Dajesz add_subdirectory itp. Zamiast asma, wypluwałbym:
- oczywiście błędy
- jak wszystko się powiedzie, jakie targety CMake wyprodukował, wartości zmiennych, może flow jakim CMakeSL szedł itp.
Możliwości jest dużo. Myślę, że takie coś byłoby pomocne przy pracy z CMake.
No i postawiłbym to na jakimś VPSie, żeby był normalnie dostępny.
Co myślicie? Ma sens? Nie ma?


Myślę, że jak najbardziej ma - podręczne kompilatory online już niejednokrotnie ułatwiły mi wyizolowanie problemu np. do konkretnej wersji kompilatora, przełączników itd.
(... jest to kontynuacja poprzedniego wpisu)
Czyyyyli cały wpis wygląda tak (te czerwone bajty):

Ok, dodaliśmy nowe entry do tablicy. To co teraz zrobimy, to zaznaczymy, że jest jedna sekcja więcej. Zrobimy to, wpisując nową wartość w COFF Headerze, w memberze NumberOfSections. Offset tego membera wynosi 206. Jak pamiętamy, wcześniej było tam 5. Zmieniamy na 6.

Uff. To teraz mamy już prawilny wpis w tablicy sekcji, z naszą nowiuteńką sekcją. Jedyne co nam zostało, to wrzucenie faktycznych 'danych' sekcji do pliku. Danych w cudzysłowie, bo na tym etapie wrzucimy tam po prostu śmieci. Idziemy na koniec pliku i wpisujemy 4KB o wartości 'AB' (bo czemu nie?).

No i git. Tyle. Odpalmy execa, żeby się upewnić, że nic nie napsuliśmy.

Wszystko bangla, możemy koń...
A jednak zonk.
Ale jak to? Przecież nie zmienialiśmy kodu. Nie zmienialiśmy istniejących sekcji, ani nic. Co się stało?
Okazuje się, że jest jeszcze coś, o co musimy zadbać. PE Optional Header ma takie dwa niewinne membery. SizeOfCode i SizeOfImage. Jak się domyślacie, SizeOfCode mówi ile (sumując wszystkie sekcje z kodem) bajtów kodu jest w pliku. SizeOfImage jest sumą rozmiarów sekcji, z uwzględnieniem membera SectionAlignment. Czyli nawet jeżeli sekcja zajmuje jeden bajt, obliczając SizeOfImage, musimy ten jeden bajt zalignować do SectionAlignment, który u nas wynosi 0x1000.
SizeOfCodesiedzi pod offsetem228, zmieniamy z0x00000200na0x00001200bo nasza sekcja z kodem zajmuje0x1000.SizeOfImagejest pod280. Zmienamy z0x00006000na0x00007000.

Ej, a co z memberem
SizeOfHeaders? Zmieniałeś przecież headery, DODAWAŁEŚ nowe dane, zmieniłeś rozmiar tablicy sekcji. Czemu tego membera nie zmieniłeś?
Bardzo dobre pytanie! W tym wypadku uratował nas inny member: FileAlignment. Wynosi on 0x200, i okazało się, że po dodaniu wpisu do tablicy, nie wyszliśmy za alignment, więc nie trzeba było SizeOfHeaders zmieniać.
Kontynuując, zapisujemy i pyk, zobaczymy czy teraz działa.

Profit (:
Następne wpisy będą jak się przygotuję na następne spotkanie w pracy, na którym mam mówić. Zostańcie stuńczykowani.


Disclaimer
Mało wiem o RE. Jeżeli palnąłem jakieś głupstwo, dajcie znać.
RE fun 1
No siema. Zawsze ciągnęło mnie do inżynierii wstecznej. Zawsze jednak mówiłem sobie '... Teraz to ja nie mam czasu. Zawalony jestem, ale za miesiąc, to ooo panie. Tak wejdę w RE, że nie będzie wiedziała co się dzieje...'. No i z miesiąca na miesiąc czas mijał, a RE z chusteczką czekała na moje przybycie.
Jakiś czas temu powiedziałem, że tak byś nie może. Nie samym C++ człowiek żyje. Wiedziałem, że muszę mieć jakąś motywację do uczenia, a najlepiej jakbym uczył się też od innych, więc w pracy zebrałem paru chętnych i zacząłem cotygodniowe spotkania o RE. Każdy, kto chce brać udział, musi co jakiś czas coś pokazać - dzięki temu nikt nie będzie zawalony przygotowaniami, bo każdy pokazuje coś, co około 5 tygodni, a jednocześnie będziemy uczyć się od siebie nawzajem. No win-win.
Ale ja nie o tym. Znaczy o tym, ale nie chciałem tylko przedstawić konceptu. Pomyślałem, że będę wrzucał tutaj skrócone (nooo, wyszedł trochę mało skrócony) wpisy o tym, co przedstawiam na spotkaniach. Może kogoś zainteresuje/zainspiruje. Zapraszam.
Abstrakt
Wysokopoziomowo co chcę pokazać w mojej serii spotkań, to format windowsowych plików Portable Executable (PE). Na początek 32-bitowa wersja.
Założenie jest takie: przygotować prosty program (jakiś hello world) i skompilować go do execa. Wrzucić tego execa do hex edytora i z palca tu coś pozmieniać, tam coś dodać, w taki sposób, żeby 'wstrzyknąć' jakiś własny kod, np. taki co przed wypisaniem 'Hello world!', wypisze jeszcze coś (albo wykopie bitcoina, zobaczymy co prostsze). Myślę, że przez taką zabawę, można całkiem fajnie ogarnąć podstawy formatu PE i jak to wszystko tam działa.
Rozłożyłem mój temat na parę spotkań, bo się w jedną godzinę nie wyrobię. Ten wpis przedstawi pierwsze ze spotkań.
Kod programu
Żeby (na ile to możliwe) zminimalizować boilerplate, którym kompilator zanieczyści nam execa, zdecydowałem się na hello worlda w asmie. Cały kod wygląda tak:
include C:\masm32\include\masm32rt.inc
.data
MESSAGE db "Hello world!", 0
MESSAGE_LENGTH equ $ - MESSAGE
.data?
BytesWriten dd ?
.code
start:
push STD_OUTPUT_HANDLE
call GetStdHandle
push NULL
push offset BytesWriten
mov ebx, MESSAGE_LENGTH
push ebx
push offset MESSAGE
push eax
call WriteConsole
push 0
call ExitProcess
end start
Czyli prosto. Pobieramy uchwyt do konsoli, piszemy coś tam i wychodzimy z procesu. Skompilowane to zostało VS 2017, x86, w trybie Release.
Plan na ten wpis
W tym wpisie przedstawię strukturę pliku PE. (Nie)stety nie całą, tylko rzeczy istotne z punktu tego co będziemy robić. To, co dziś zrobimy, to dodamy do pliku nową sekcję z kodem, starając się przy tym nie zaburzyć prawidłowego działania dotychczasowego programu.
Lecimy
(Bezwstydnie kradnę rzeczy z arta z wikibooks, którego gorąco polecam!)
Plik PE jest bardzo prosty. Wygląda on tak:
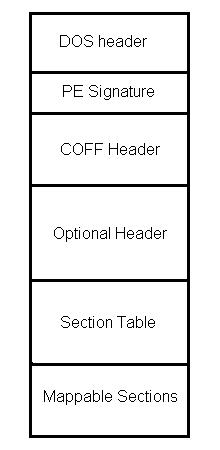
Czyli tak, na samym początku mamy DOS header. Można go przedstawić jako strukturę z C:
struct DOS_Header
{
char signature[2] = { 'M', 'Z' };
short lastsize;
short nblocks;
short nreloc;
short hdrsize;
short minalloc;
short maxalloc;
void *ss;
void *sp;
short checksum;
void *ip;
void *cs;
short relocpos;
short noverlay;
short reserved1[4];
short oem_id;
short oem_info;
short reserved2[10];
long e_lfanew; // Offset w pliku, pod którym znajdziemy 'PE Signature'
}
(Zanim przejdziemy dalej - analizujemy plik 32-bitowy. We wszystkich przedstawionych strukturach, char zajmuje 1 bajt, short 2, a long 4. Będzie to ważne, gdy będziemy obliczać offsety memberów w pliku, pobierać ich wartości itp. Warto, również wspomnieć, że wszystkie wartości w pliku są w little-endian)
Jedyne co nas z tej struktury interesuje, to wartość membera e_lfanew. Jest to offset, pod którym znajdziemy sygnaturę PE. Member ten leży pod offsetem 60 (normlenie 60, NIE hexadecymalnie) od początku pliku i zajmuje 4 bajty.
No to wrzucamy execa to HxD i zaczynamy zabawę.

Odczytujemy offset. Wynosi on C8, czyli 200. Skaczemy tam i rzeczywiście widzimy, że mamy pod tym offsetem sygnaturę PE

I to jest wszystko, co się w tej części znajduje. Cztery bajty PE\0\0.
Zaraz za tą sygnaturą znajduje się następna ważna struktura, COFF Header. Wygląda ona tak:
struct COFFHeader
{
short Machine;
short NumberOfSections;
long TimeDateStamp;
long PointerToSymbolTable;
long NumberOfSymbols;
short SizeOfOptionalHeader;
short Characteristics;
}
i zajmuje 20 bajtów.
Przy bliższym kontakcie, widzimy, że jest tu jedna wartość, która na będzie interesować: NumberOfSections. Będziemy dodawać nową sekcję z kodem, więc dzięki temu memberowi, obliczymy ile jest aktualnie sekcji w pliku.
Obliczmy offset COFF Headera. Wynosi on offset_sygnatury_pe + rozmiar_sygnatury_pe, czyli 200 + 4 = 204.
Obliczmy też od razu offset i wartość membera NumberOfSections. Offset w samej strukturze COFFHeader wynosi 2, więc offset w samym pliku = 204 + 2 = 206. Zobaczmy zatem ile tych sekcji w pliku mamy:

Czyli jest ich 5. Jedziemy dalej - znajdźmy Section Table, czyli tablicę opisującą wszystkie sekcje jakie mamy w pliku. Jak ją znajdziemy, dorzucimy do tablicy naszą nową sekcję.
Żeby znaleźć tablicę sekcji, musimy znaleźć PE Optional Header (PEOH), ponieważ owa tablica leży zaraz za tym headerem. Na szczęście znalezienie go jest bardzo łatwe - znajduję się on zaraz za COFF headerem.
Obliczmy offset PEOH. Wynosi on offset_coff_headera + rozmiar_coff_headera, czyli 204 + 20 = 224. Header ten wygląda tak:
struct PEOptHeader
{
short signature;
char MajorLinkerVersion;
char MinorLinkerVersion;
long SizeOfCode;
long SizeOfInitializedData;
long SizeOfUninitializedData;
long AddressOfEntryPoint;
long BaseOfCode;
long BaseOfData;
long ImageBase;
long SectionAlignment;
long FileAlignment;
short MajorOSVersion;
short MinorOSVersion;
short MajorImageVersion;
short MinorImageVersion;
short MajorSubsystemVersion;
short MinorSubsystemVersion;
long Win32VersionValue;
long SizeOfImage;
long SizeOfHeaders;
long Checksum;
short Subsystem;
short DLLCharacteristics;
long SizeOfStackReserve;
long SizeOfStackCommit;
long SizeOfHeapReserve;
long SizeOfHeapCommit;
long LoaderFlags;
long NumberOfRvaAndSizes; // W plikach PE wynosi zawsze 16, i tego się będziemy trzymać w tym wpisie.
data_directory DataDirectory[NumberOfRvaAndSizes];
}
Struktura data_directory wygląda tak:
struct data_directory
{
long VirtualAddress;
long Size;
}
Więc rozmiar całego PEOH w naszym pliku wynosi 224.
Mając te dane, obliczmy offset, pod którym leży szukana tablica sekcji. Wynosi on offset_peoh + rozmiar_peoh, czyli 224 + 224 = 448.
Tablica sekcji, to tablica takich struktur:
struct IMAGE_SECTION_HEADER
{
char Name[IMAGE_SIZEOF_SHORT_NAME]; // IMAGE_SIZEOF_SHORT_NAME == 8 bytes
union {
long PhysicalAddress;
long VirtualSize;
} Misc;
long VirtualAddress;
long SizeOfRawData;
long PointerToRawData;
long PointerToRelocations;
long PointerToLinenumbers;
short NumberOfRelocations;
short NumberOfLinenumbers;
long Characteristics;
}
Rozmiar tej struktury wynosi 40.
Czyli tak, mamy offset, pod którym zaczyna się tablica (448), mamy rozmiar jednego wpisu w tej tablicy (40), no i mamy rozmiar tej tablicy (5). Mając to wszystko, możemy łatwo obliczyć offset, pod którym musimy wpisać nowe entry, opisujące naszą nową sekcję: 448 + 5 * 40 = 648.
Zanim zaczniemy wpisywać nowe entry, zastanówmy się, co chcemy wpisać.
Name- niech będzie.mysectMisc- jest to unia. Nas interesuje memberVirtualSize. Jest to liczba bajtów sekcji, jakie mają być załadowane do RAMu, przy ładowaniu programu. Nie zastanwiajmy się na razie nad optymalizacją, i wpiszmy, że chcielibyśmy, żeby nasza sekcja miała0x1000bajtów po załadowaniu.VirtualAddress- virtualny adres, pod jaki ma być załadowana nasza sekcja. Obliczymy go za chwilę.SizeOfRawData- liczba bajtów, które sekcja zajmuje w pliku. Bez pitolenia, damy tu0x1000. Tyle chcemy, żeby zajmowała nasza sekcja.PointerToRawData- offset naszej sekcji w pliku.PointerToRelocations,PointerToLinenumbers,NumberOfRelocations,NumberOfLinenumbers- tym się nie będziemy teraz zajmować. Wpiszemy tu same zera.Characteristics- maska bitowa opisująca naszą sekcję. My zapalimy trzy bity:0x00000020- nasza sekcja zawiera kod,0x20000000- sekcja może być wykonywana jako kod,0x40000000- sekcja może być odczytana. Czyli po zorowaniu tego wychodzi0x60000020, i to wpiszemy.
Obliczmy VirtualAddress. Przyjmiemy naiwną taktykę. Znajdziemy sekcję, która aktualnie ma największy VirtualAddress, odczytamy jej rozmiar, dodamy ten rozmiar to adresu i tak oto obliczymy VirtualAddress naszej sekcji.
Lecimy. Odczytajmy pierwszą sekcję. Jej offset w pliku jest taki: offset_tablicy_sekcji + indeks_sekcji * rozmiar_jednego_wpisu_tablicy, czyli 448 + 0 * 40 = 448.
Wygląda ona tak:

Czyli mamy wartości:
- Name -
.text\0\0\0 - Misc.VirtualSize - 0x00000038
- VirtualAddress - 0x00001000
- SizeOfRawData - 0x00000200
- PointerToRawData - 0x00000400
- PointerToRelocations - 0x00000000
- PointerToLinenumbers - 0x00000000
- NumberOfRelocations - 0x0000
- NumberOfLinenumbers - 0x0000
- Characteristics - 0x60000020
Analogicznie odczytujemy kolejne sekcje. Wychodzą takie wartości VirtualAddress i SizeOfRawData:
- .text - 0x00001000, 0x00000200
- .rdata - 0x00002000, 0x00000400
- .data - 0x00003000, 0x00000200
- .rsrc - 0x00004000, 0x00000200
- .reloc - 0x00005000, 0x00000200
Jak widać, największy VirtualAddress ma .reloc i wynosi on 0x00005000. SizeOfRawData wynosi 0x200.
Mając te dane, obliczmy VirtualAddress naszej tablicy: 0x5000 + 0x200 = 0x5200. Gotowe, tak? No właśnie nie bardzo. Obliczając VirtualAddress musimy pamiętać o jednej ważnej wartości z PE Optional Header - SectionAlignment. Jest to wartość, do jakiej mają być zalignowane sekcje po załadowaniu do RAMu. SectionAlignment jest w naszym pliku pod offsetem 256 i wynosi 0x1000, więc uwzględniając go, obliczamy, że VirtualAddress naszej sekcji wynosi nie 0x5200, ale 0x6000. I taką wartość wpiszemy to pliku.
No i została ostatnia wartość do obliczenia, zanim wpiszemy entry naszej sekcji do tablicy - PointerToRawData. Z tym będzie prościej. Jest to po prosu offset w pliku, gdzie zaczyna się nasza sekcja. Nie będziemy kombinować i wrzucimy sekcję na koniec pliku, więc offset tej sekcji, to aktualny rozmiar pliku - 0x1000.
Podsumowując, wpis naszej sekcji w tablicy będzie wyglądał tak:
- Name -
.mysect\0 - Misc.VirtualSize - 0x00001000
- VirtualAddress - 0x00006000
- SizeOfRawData - 0x00001000
- PointerToRawData - 0x00001000
- PointerToRelocations - 0x00000000
- PointerToLinenumbers - 0x00000000
- NumberOfRelocations - 0x0000
- NumberOfLinenumbers - 0x0000
- Characteristics - 0x60000020
(Reszta już jest w moim następnym wpisie...)

#chwalesie
Jakiś czas temu (w sumie to dawno) chwaliłem się tutaj moją wrzutą to libki fmt.
Ostatnio znalazłem chwilę, żeby w końcu dodać moją implementację do benchmarków, i tu wchodzi część, którą się chwalę: moja implementacja jest ~11% szybsza niż zwykłe fmt::format(), 46% niż zwykły printf itd \o/
https://github.com/fmtlib/format-benchmark/pull/11
Zaznaczę tylko, że to przy benchmarkach, które mają w libce zaimplementowane. IMHO można to mierzyć lepiej. Może kiedyś znajdę czas na wrzutę z jakimś googlebenchmark czy cuś. Tak czy siak, fmt::prepare() dobrze rokuje.

Szukaj pracy
Aktywność
+1. Znaczące białe znaki to jest jakiś żart. Zarówno w językach programowania, jak i...
Słuchajcie, jest spontaniczna akcja! Jesteśmy w trakcie zjazdu firmowego. Ludzie z p...
Słuchajcie, jest spontaniczna akcja! Jesteśmy w trakcie zjazdu firmowego. Ludzie z p...
Słuchajcie, jest spontaniczna akcja! Jesteśmy w trakcie zjazdu firmowego. Ludzie z p...
Słuchajcie, jest spontaniczna akcja! Jesteśmy w trakcie zjazdu firmowego. Ludzie z p...
Słuchajcie, jest spontaniczna akcja! Jesteśmy w trakcie zjazdu firmowego. Ludzie z p...
Słuchajcie, jest spontaniczna akcja! Jesteśmy w trakcie zjazdu firmowego. Ludzie z p...
Słuchajcie, jest spontaniczna akcja! Jesteśmy w trakcie zjazdu firmowego. Ludzie z p...
Słuchajcie, jest spontaniczna akcja! Jesteśmy w trakcie zjazdu firmowego. Ludzie z p...
Słuchajcie, jest spontaniczna akcja! Jesteśmy w trakcie zjazdu firmowego. Ludzie z p...
Historia reputacji
Uprawnienia
-
1użycie chińskich znaków w tekście
-
10używanie wspomnień użytkowników
-
50oddawanie głosów na wpisy innych
-
50publikacja URL do strony WWW w profilu
-
50dodanie URL do strony WWW w sygnaturze na forum
-
300dodawanie nowych tagów
-
1000publikacja wątków z krótkim tytułem
-
10000brak reklam banerowych oraz na mikroblogu
-
10000edycja własnych postów do 1 miesiąca od daty napisania
@Silv:
size()zwraca to co powinno. a zwraca 3 bo tablica rzeczywiście wynosi{ { 1, 2 }, { 3, 4 }, { 5, 0 } }.