Przepraszam bardzo za kłopot, już się poprawiam, przepraszam z całego serca.
Kopiuj
import re
import requests
import shapefile
import pandas as pd
shapefile_path = 'C:/Users/ja/PYTHON SPYDER/Python praca/shapefiles/PL1992_5000_025'
wms_request_base_url = 'https://mapy.geoportal.gov.pl/wss/service/PZGIK/ORTO/WMS/SkorowidzeWgAktualnosci'
wms_request_parameters = {
'SERVICE': 'WMS',
'request': 'GetFeatureInfo',
'version': '1.3.0',
'layers': 'SkorowidzeOrtofotomapyStarsze,SkorowidzeOrtofotomapy2018,SkorowidzeOrtofotomapy2019,SkorowidzeOrtofotomapy2020',
'styles': '',
'crs': 'EPSG:2180',
'width': 1000,
'height': 1000,
'format': 'image/png',
'transparent': 'true',
'query_layers': 'SkorowidzeOrtofotomapyStarsze,SkorowidzeOrtofotomapy2018,SkorowidzeOrtofotomapy2019,SkorowidzeOrtofotomapy2020',
'i': 1,
'j': 1,
'INFO_FORMAT': 'text/html'
}
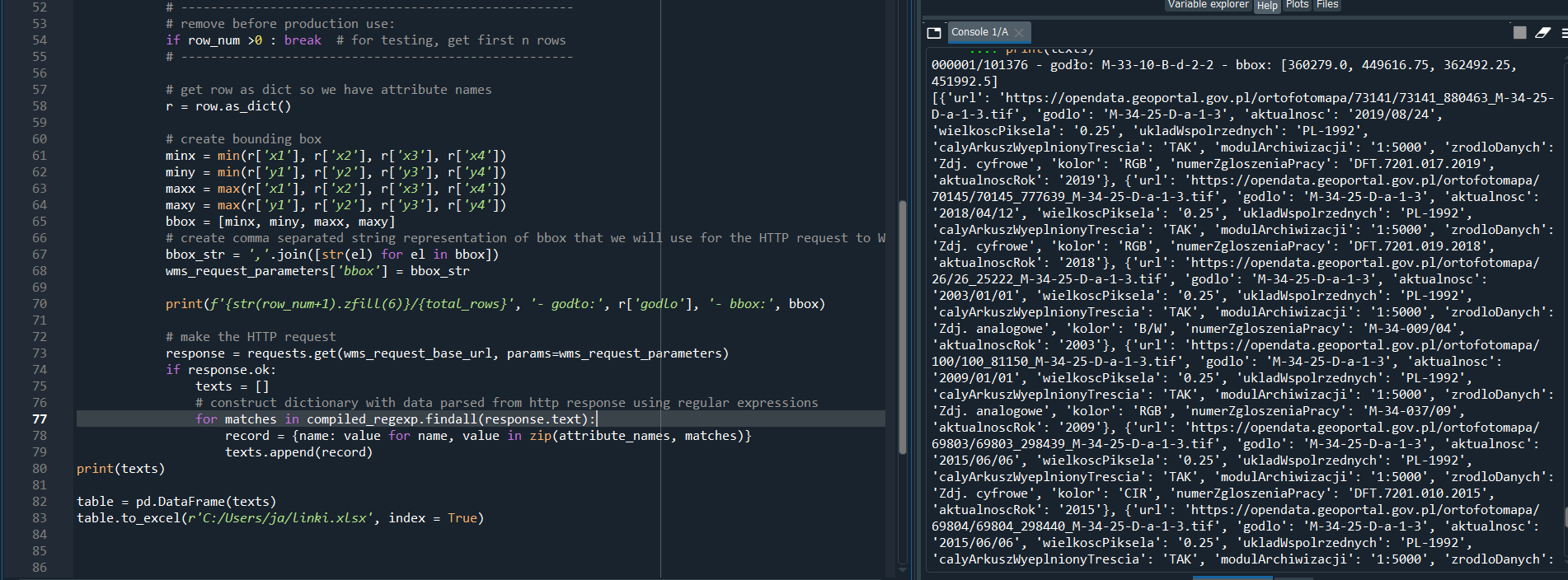
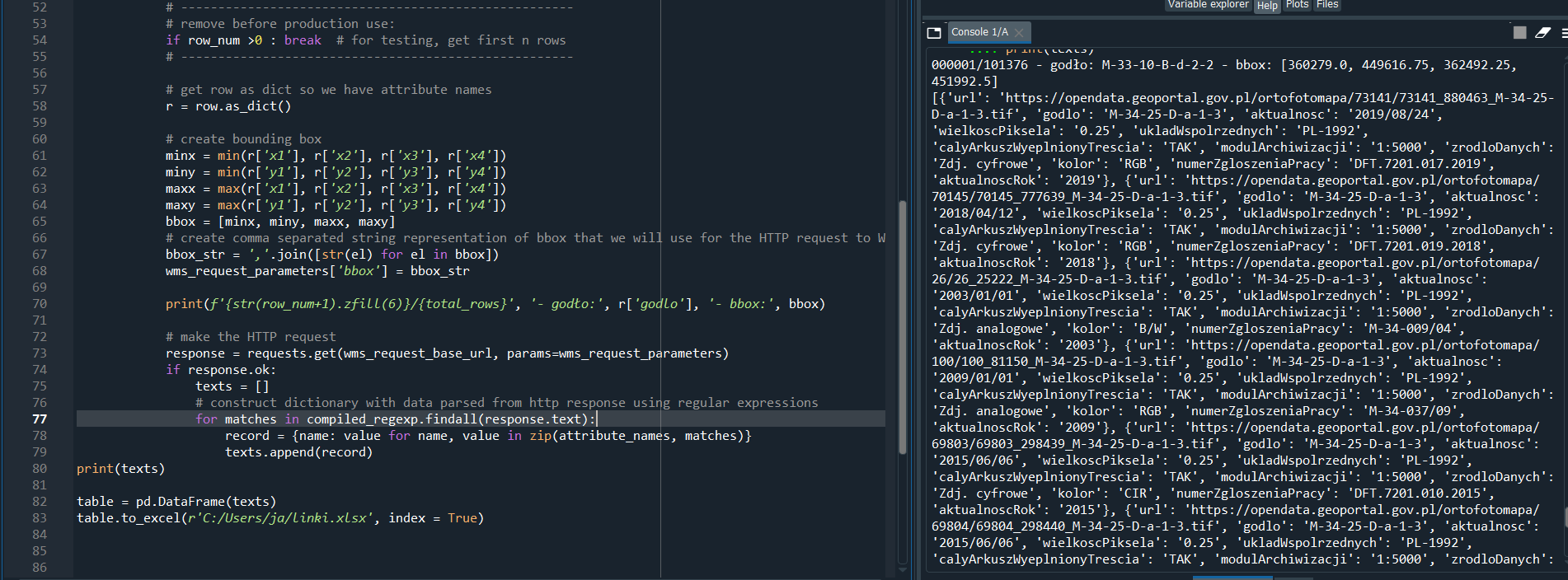
regexp = '{url:"(.+)",godlo:"(.+)", aktualnosc:"(.+)", wielkoscPiksela:"(.+)", ukladWspolrzednych:"(.+)", calyArkuszWyeplnionyTrescia:"(.+)", modulArchiwizacji:"(.+)", zrodloDanych:"(.+)", kolor:"(.+)", numerZgloszeniaPracy:"(.+)", aktualnoscRok:"(.+)"}'
compiled_regexp = re.compile(regexp, re.IGNORECASE)
attribute_names = [
'url',
'godlo',
'aktualnosc',
'wielkoscPiksela',
'ukladWspolrzednych',
'calyArkuszWyeplnionyTrescia',
'modulArchiwizacji',
'zrodloDanych',
'kolor',
'numerZgloszeniaPracy',
'aktualnoscRok'
]
if __name__ == '__main__':
with shapefile.Reader(shapefile_path) as shp:
total_rows = shp.numRecords
for row_num, row in enumerate(shp.iterRecords()):
if row_num >5 : break
r = row.as_dict()
minx = min(r['x1'], r['x2'], r['x3'], r['x4'])
miny = min(r['y1'], r['y2'], r['y3'], r['y4'])
maxx = max(r['x1'], r['x2'], r['x3'], r['x4'])
maxy = max(r['y1'], r['y2'], r['y3'], r['y4'])
bbox = [minx, miny, maxx, maxy]
bbox_str = ','.join([str(el) for el in bbox])
wms_request_parameters['bbox'] = bbox_str
print(f'{str(row_num+1).zfill(6)}/{total_rows}', '- godło:', r['godlo'], '- bbox:', bbox)
new_text = []
response = requests.get(wms_request_base_url, params=wms_request_parameters)
if response.ok:
for matches in compiled_regexp.findall(response.text):
record = {name: value for name, value in zip(attribute_names, matches)}
new_text.append(record)
print(new_text)





{kind=link}
{kind=link}