Znalazłem takie skrypty jak poniżej
https://www.p-programowanie.pl/php/licznik-odwiedzin
https://reporter.pl/mysql-php-jak-wykonac-licznik-odwiedzin-strony-www-707
tylko one są ile dzisiaj wejść było
nie wiem jak zrobić licznik odwiedzin php za ostatnie 24h czyli musi zliczać dzisiaj i wczoraj chyba godzina po godzinie osobno i do mysql ale musiało by sie samo czyścic ? bo zaraz bedzie cała zapełniona baza 24hx365dni x ilość lat to wyjdzie zapchane całe
1
2
O ile nie planujesz mieć milionów wejść dziennie, to spokojnie zapisuj każde wejście, ułatwisz sobie życie. I potem SQL-em sobie zaczytaj co potrzebujesz. A jakimś cronem wywalaj raz dziennie co niepotrzebne.
2
Jak wyżej - możesz co jakiś czas puścić optymalizacje tabeli bo przy takim użyciu może się szybko fragmentować.
Jak chcesz mieć spokojną głowę o skalowanie tego rozwiązania to możesz zmniejszyć granulację - możesz na przykład trzymać tylko liczbę wizyt każdej godziny, wtedy na sztywno będziesz miał w tabeli 24 rekordy i możesz inkrementować wartość w konkretnej godzinie + zerować kolejną. Będziesz wtedy miał wizyty z ostatnich 24h +/- 60 minut. Można zwiększyć granulację na na przykład 5 minut i mieć 288 rekordów itp, idea prosta a odpadają ciągłe inserty i delete.
1
winnxan napisał(a):
nie wiem jak zrobić licznik odwiedzin php za ostatnie 24h czyli musi zliczać dzisiaj i wczoraj chyba godzina po godzinie osobno i do mysql
No to pytanie czy to mają być zawsze "ostatnie 24h", (czyli np. jak jest teraz 13:15, to czy ma zliczyć odwiedziny do 13:15 poprzedniego dnia)? Czy mają to być odwiedziny z dzisiaj, czyli np. od 13:15 do 00:00?
To drugie będzie zdecydowanie łatwiej policzyć, i ja po prostu podszedłbym do tego tak:
<?php
$dates = [];
$currentDate = date("Y-m-d");
if (\array_key_exists($currentDate, $dates)) {
$dates[$currentDate]++;
} {
$dates[$currentDate] = 1;
}
I dodatkowo możesz się też zastanowić jak zapisać zmienną $dates. Widziałem że w Twoich tutorialach proponowali bazę danych, ale moim zdaniem to jest duża komplikacja. Dużo prościej byłoby je zapisać do pliku, a następnie wczytać. Raczej nie robiłbym samodzielnego parsowania tych plików, poszedłbym w gotowe rozwiązanie.
Możesz np. je zapisać do CSV:
function saveToCsv(array $dates) {
$file = fopen('file.csv', 'w');
foreach ($dates as $date => $count) {
fputcsv($file, [$date, $count]);
}
fclose($fp);
}
function readFromCsv(): array {
$dates = [];
$file = fopen("file.csv", "r"));
while (($data = fgetcsv($file, 1000, ",")) !== false) {
[$date, $count] = $data;
$dates[$date] = $count;
}
fclose($file);
return $dates;
}
Jeśli nie, to możesz zapisać je jako JSON do pliku, korzystając z file_put_contents('file.json', json_encode($dates)) oraz json_decode(file_get_contentets('file.json'),true).
winnxan napisał(a):
ale musiało by sie samo czyścic ? bo zaraz bedzie cała zapełniona baza 24hx365dni x ilość lat to wyjdzie zapchane całe
Bardzo fajnie że próbujesz przewidzieć potencjalne problemy z Twoim rozwiązaniem, możesz się o nich zastanawiać do woli! 
Ale jednak nie rozwiązuj problemów których jeszcze nie masz, nawet jeśli są to problemy które chciałbyś mieć w przyszłości. Jeśli tak się zdarzy że zapcha Ci się baza, wtedy pomyślimy jak to naprawić.
1
chodzi o to pierwsze czyli od 13:15 do 13:15 ale nie musi byc z taka dokładnoscią może byc co do godziny bez minut
0
winnxan napisał(a):
chodzi o to pierwsze czyli od 13:15 do 13:15 ale nie musi byc z taka dokładnoscią może byc co do godziny bez minut
No to zacznij od zapisania daty, godziny i minuty (albo może nawet po prostu timestamp). Każdy taki timestamp to będą 4B, dajmy 10tys. wyświetleń, to jest ledwo 40kB.
A następnie po prostu policz ile jest takich wystąpień od zadanego timestampu do innego. Możesz również usuwać wszystkie stare wyświetlenia, jeśli ich nie potrzebujesz.
- Możesz zapisać wszystkie czasy do pliku, następnie wczytać go, policzyć czasy sprzed 24h.
- Albo faktycznie możesz postawić bazę, każde wyświetlenie to osobny insert, a następnie zrobić
select where timestamp > now() - '24 hours'::interval;.
Faktycznie z bazą to konkretne zadanie byłoby łatwiejsze; ale baza dostarcza sama z siebie komplikacje (połączenie, dane logowania, host, nazwa bazy, tworzenie tabel, migracje, etc.). Ewentualnie możesz skorzystać z SQLite, jest wbudowany driver w PHP pod to, to byłoby trochę prostsze niż MySQL, i miałbyś to wpliku. Może to jest dobra opcja? Przewaga SQLite jest taka że nie potrzebujesz servera MySQL pod to. Jednak z SQLIte nadal musisz pamiętać żeby stworzyć odpowiednią tabelę z odpowiendimi kolumnami, więc finalnego kodu zdecydowanie będzie więcej.
Z plikami będzie prościej pod tym względem że możesz skorzystać po prostu z file_get_contents()/file_put_contents(), tylko wtedy należy przelecieć pętelką i policzyć które timestamp są przed a które po tym umówionym czasie.
0
Fajne to rozwiążanie z sql lite co mówisz nie wiedziałem że nie trzeba łączyć sież baza ,że jest taka opcja.
Jednak teraz myśle że może po prostu zrobie wyświetlę liczbe wejść wczoraj i dzisiaj.
Tutaj mam funkcje że dzisiaj ile wejść i co musiałbym np. o 23:59 zrobić skrypt że on kopiuje z tego pliku wartość i wkleja do np. liczwczoraj.txt ?
<?php
//ob_start();
if(!$_COOKIE['naszastrona']=="1")
{
$plik="licz.txt";
//odczytujemy aktualną wartość z pliku
$file=fopen($plik, "r");
flock($file, 1);
$liczba=fgets($file, 16);
flock($file, 3);
fclose($file);
$liczba++; //zwiększamy o 1
//zapisujemy nową wartość licznika
$file=fopen($plik, "w");
flock($file, 2);
fwrite($file, $liczba++);
flock($file, 3);
fclose($file);
setcookie("naszastrona","1");
//ob_end_flush();
}
?>
0
albo wgl. można by importować z analytics ale nie wiem czy jest taka opcja
0
winnxan napisał(a):
albo wgl. można by importować z analytics ale nie wiem czy jest taka opcja
Zależy na czym Ci zależy.
Jeśli mówiąc "analytics" masz na myśli Google Tag Manager i Google Analytics, to takie dane można spreparować; np. Adblock blokuje GTM.
Liczenie wyświetleń jako ilość rządań do serwera wydaje się bardziej rzetelne, ale sprawia że musisz trzymać te wyświetlenia na serwerze. Coś za coś.
1
Jeszce jedna kwestia, która chyba nie padła: tak właściwie, to co chcesz sprawdzać?
Czy po prostu wyświetlenia, czy unikalne wejścia?
Jeśli strona ma podstrony - każde wyświetlenie ma nabijać licznik?
Jak ta sama osoba wejdzie kilka razy - chcesz każde wejście zliczyć, czy uznać, że ten pacjent już był dzisiaj policzony?
Jeśli wejdę na stronę i przytrzymam klawisz F5, to po kilku minutach będziesz miał tysiące wyświetleń nabite - czy nie byłoby warto się przed czymś takim obronić/zabezpieczyć?
W pozostałych tematach - już to padło, ale i tak napiszę:
- nie baw się w pliki tekstowe, SQLite jest lepszą opcją
- SQLite a nie jakiś "prawdziwy" SQL, gdzie musisz postawić silnik. Do tego, co potrzebujesz SQLite wystarczy z wielkim zapasem
- nie martw się o rozmiar bazy, musiałbyś mieć więcej wejść niż PornHub, żeby to było realnym problemem i kwestią do rozważania
- zbieraj adresy IP osób wchodzących (plus może jakieś dodatkowe dane typu User Agent) - albo żeby zliczać tylko unikalne wejścia, albo żeby się zabezpieczyć przed sztucznym nabijaniem przez np. ciągłe odświeżanie strony
- co w przypadku dociągania treści/wyświetlania podstron - one też odpalą licznik?
- Co do zbierania adresów IP - tutaj trochę zahaczamy o tematy RODO i pokrewne. Aczkolwiek - nie wiem jaka to strona, czy komercyjna czy hobbystyczna, jaki ma zasięg itp, więc ciężko coś więcej powiedzieć.
0
to moze po prostu pociagnac to z awstats
1.zrobiłem na razie w txt i mi nie działa spróbuje w sql teraz
2. nie wiedziałem ze adblock blokuje analytics tez wejścia
3. w tym pierwszym linku co podałem gość napisał już zabezpieczenie cookie przed odświeżaniem chodzi o unikalne wyśw. plus podstrony tylko nie wiem czy to działa to zabezpieczenie na tą jedną strone czy to cookie działa juz na wszystke strony na 24h czy ileś
0
winnxan napisał(a):
1.zrobiłem na razie w txt i mi nie działa spróbuje w sql teraz
3. w tym pierwszym linku co podałem gość napisał już zabezpieczenie cookie przed odświeżaniem chodzi o unikalne wyśw. plus podstrony tylko nie wiem czy to działa to zabezpieczenie na tą jedną strone czy to cookie działa juz na wszystke strony na 24h czy ileś
Cookies da się ręcznie ustawić z poziomu przeglądarki, czyli ktoś mógłby ciągle robić zerowanie cookies i twój serwer by ciągle myślał, że to nowy użytkownik.
Sqllite ma dużo algorytmów, które mega przyspieszają wyszukiwanie i odnajdywanie twoich danych, których jakbyś byle jak zrobił by miały bardzo kiepską złożoność obliczeniową i byś tylko procesor marnował.
Robi to za ciebie baza danych plikowa, ale jest bardzo wydajna.
Riddle i Cerrato ci dobrze podpowiedzieli.
Musisz też te ip weryfikować czy fingerprint czyli agent przeglądarki jakieś dodatkowe opcje jak rozdzielczość czy inne, to też da się oszukać więc same ip możesz teoretycznie sprawdzić.
I jak już ktoś raz odwiedził w miesiącu twój serwer z tym ip, to uznajesz jako jeden użytkownik, jedna odwiedzina strony, czyli zależy jakb bardzo w angielskim sloganie squashujesz dane, to więcej masz pracy, jak co godzinę to musisz sprawdzić czy w danej godzinie już te ip się nie odwiedzało, jak w miesiącu to też w całym miesiącu musisz sprawdzić, sqllite czy inne sql bazy danych, jak źle nie użyjesz to za ciebie zrobią jakieś drzewiaste struktury, które pozwolą ci 1mld danych przeszukać tylko w 30 zapytaniach do bazy.
Więc tam od wewnętrznej strony internalsów są bardzo dobrze algorytmicznie zrobione te bazy do optymalnego szukania danych i ich gromadzenia, dalej człowiek może sporo błędów popełnić przez co będą gorzej działały, da się też to debugować i optymalizować, więc jest specjalizacja od baz danych, tam się da dużo dobrze zrobić jak się umie.
1
1.zrobiłem na razie w txt i mi nie działa spróbuje w sql teraz
Skoro nie działa i nie wiesz, dlaczego - jest duża szansa, że po przejściu na SQL też nie będzie działać. Problem może leżeć gdzieś zupełnie indziej, niż podejrzewasz. Radziłbym najpierw jednak naprawić to, co masz. Bo jeśli coś nie działa to fajnie jest zrozumieć swój błąd, ma to dużą wartość edukacyjną.
- w tym pierwszym linku co podałem gość napisał już zabezpieczenie cookie przed odświeżaniem chodzi o unikalne wyśw. plus podstrony tylko nie wiem czy to działa to zabezpieczenie na tą jedną strone czy to cookie działa juz na wszystke strony na 24h czy ileś
Cookiesy są po stronie klienta, więc takie średnie to zabezpieczenie. Odpalisz w trybie prywatnym, albo wyczyścisz pamięć przeglądarki i ciasteczka znikną. Oczywiście - rozumiem, że licznik wyświetleń jakiejś średnio-istotnej stronki (wybacz szczerość) nie jest czymś kluczowym, nad czym trzeba spędzić 2 miesiące pracy, ale skoro taki licznik chcesz mieć, to znaczy, że jest on dla Ciebie istotny. Więc wolę zaznaczyć, że bazowanie na ciasteczkach jest trochę ryzykowne/mało wiarygodne.
0
To sql lite robic czy mysql ? bo jak pisał .GodOfCode.sql lite moge narobić błedów i zuzyje dużo zasobów serwera jezeli dobrze zrozumiałem.
1
winnxan napisał(a):
To sql lite robic czy mysql ? bo jak pisał .GodOfCode.sql lite moge narobić błedów i zuzyje dużo zasobów serwera jezeli dobrze zrozumiałem.
Zarówno zrobienie tego na plikach (CSV lub JSON) oraz baza SQLite będą dobrym wyjściem, oba mają swoje wady i zalety. MySQL/Postgres to niepotrzebna kobyła.
0
ok dzieki a w tej wersji txt może chmody zle ustawiłem licz.txt znacie kod na chmoda własciwego bo tam read write musi
1
w tej wersji txt może chmody zle ustawiłem licz.txt znacie kod na chmoda własciwego bo tam read write musi
Jeśli skrypt nie miał prawa do zapisu w określonym miejscu, to jest duża szansa, że tak samo się stanie, jak będziesz chciał skorzystać z SQLIte. Zauważ, że przy "prawdziwym" SQL stawiasz gdzieś serwer/silnik, a potem aplikacje się do niego łączą. A SQLite, od strony technicznej, trzyma bazę w 1 pliku, który to plik sobie gdzieś musisz mieć zapisany. Z punktu widzenia programisty - używasz tego tak samo, jak każdego innego SQL'a, ale technicznie to jest plik na dysku, na którym swoje operacje wykonuje silnik SQLite. Także ponawiam to, co mówiłem wcześniej - jeśli wersja TXT Ci nie działała, zanim skoczysz na kolejny temat, zrozum co się działo i czemu nie udało Ci się tego odpalić. A dopiero potem rób zmiany.
3
Riddle napisał(a):
I dodatkowo możesz się też zastanowić jak zapisać zmienną
$dates. Widziałem że w Twoich tutorialach proponowali bazę danych, ale moim zdaniem to jest duża komplikacja. Dużo prościej byłoby je zapisać do pliku, a następnie wczytać. Raczej nie robiłbym samodzielnego parsowania tych plików, poszedłbym w gotowe rozwiązanie.Możesz np. je zapisać do CSV:
function saveToCsv(array $dates) { $file = fopen('file.csv', 'w'); foreach ($dates as $date => $count) { fputcsv($file, [$date, $count]); } fclose($fp); } function readFromCsv(): array { $dates = []; $file = fopen("file.csv", "r")); while (($data = fgetcsv($file, 1000, ",")) !== false) { [$date, $count] = $data; $dates[$date] = $count; } fclose($file); return $dates; }Jeśli nie, to możesz zapisać je jako JSON do pliku, korzystając z
file_put_contents('file.json', json_encode($dates))orazjson_decode(file_get_contentets('file.json'),true).
Jestem zaskoczony że taka rada wychodzi od kogoś z takim doświadczeniem.
Zrobienie tego poprawnie na plikach jest cholernie trudne, pliki przy dużym obciążeniu będą się blokowały, musisz obsłużyć błędy IO, brak miejsca na dysku, współbieżność, atomowość odczytu i zapisu, itp. Przykładowo przy zapisie plik jest chwilowo przycinany do zera i próba jednoczesnego odczytania z innego wątku spowoduje że licznik się zresetuje lub odczyta tylko część danych. Kod powyżej prawdopodobnie wywali się jak tylko przytrzymasz F5 w przeglądarce. flock to minimum co jest potrzebne. Dodatkowo pliki będą się inaczej zachowywać pod windowsem a inaczej pod linuksem co utrudnia testowanie i development jeśli ktoś używa windowsa.
Poza tym to rozwiązanie się zupełnie nie skaluje, resetuje się przy konteneryzacji, wymaga odpowiedniej konfiguracji (wcześniej wspomniane chmody).
Baza danych adresuje wszystkie te problemy i jest praktycznie zerowym narzutem bo łączenie z lokalną bazą danych po pipie zajmuje praktycznie tyle co otworzenie pliku a może być nawet szybsze bo operacje mogą zadziać się w pamięci bez zrzucania fizycznie na dysk przy każdym odświeżeniu. Tak czy inaczej to mikrooptymalizacja którą bym się zupełnie nie przejmował, tym bardziej że prawdopodobnie i tak musisz się połączyć z bazą danych w innej części aplikacji.
1
obscurity napisał(a):
Jestem zaskoczony że taka rada wychodzi od kogoś z takim doświadczeniem.
Zrobienie tego poprawnie na plikach jest cholernie trudne, pliki przy dużym obciążeniu będą się blokowały, musisz obsłużyć błędy IO, brak miejsca na dysku, współbieżność, atomowość odczytu i zapisu, itp. Przykładowo przy zapisie plik jest chwilowo przycinany do zera i próba jednoczesnego odczytania z innego wątku spowoduje że licznik się zresetuje lub odczyta tylko część danych. Kod powyżej prawdopodobnie wywali się jak tylko przytrzymasz F5 w przeglądarce.flockto minimum co jest potrzebne. Dodatkowo pliki będą się inaczej zachowywać pod windowsem a inaczej pod linuksem co utrudnia testowanie i development jeśli ktoś używa windowsa.
Poza tym to rozwiązanie się zupełnie nie skaluje, resetuje się przy konteneryzacji, wymaga odpowiedniej konfiguracji (wcześniej wspomniane chmody).
Baza danych adresuje wszystkie te problemy i jest praktycznie zerowym narzutem bo łączenie z lokalną bazą danych po pipie zajmuje praktycznie tyle co otworzenie pliku a może być nawet szybsze bo operacje mogą zadziać się w pamięci bez zrzucania fizycznie na dysk przy każdym odświeżeniu. Tak czy inaczej to mikrooptymalizacja którą bym się zupełnie nie przejmował, tym bardziej że prawdopodobnie i tak musisz się połączyć z bazą danych w innej części aplikacji.
Widzę w Twoich postach na forum od bardzo dawna taką postawę: "zróbmy coś od razu, za pierwszym razem".
Tymczasem moim zdaniem to jest bardzo słabe podejście. Ja preferuję zacząć od czegoś najprostszego, co ma szansę zadziałać - w tym wypadku pliki. Masz rację mówiąc o obciążeniu, wydajności, IO, miejscu, etc. to są problemy które mogą wystąpić, możliwe że nawet jest duża szansa że wystąpią - ale należy te problemy rozwiązać wtedy kiedy (jeśli) wystąpią, a nie od razu. Jeśli wystąpią od razu, to i tak wyjdzie na Twoje - naprawimy je od razu odpowiednim rozwiązaniem. Jeśli nie wystąpią - lepiej dla nas, nie musimy poświęcać czasu i uwagi na to. Jeśli wystąpią później - też w niczym to nie przeszkadza.
@obscurity Myślę że możesz mieć przekonanie, że jeśli na początku podejmie się jakąś decyzję (np. o tym żeby zapisywać dane w plikach), to już potem nie można jej zmienić (np. na bazę), dobrze rozumiem? Często tak jest w legacy systemach, kiedy raz się coś doda, to potem wyplenić jest to bardzo ciężko. Ale jeśli zbuduje się ten software tak, że zostawi się sobie furtkę do przyszłej zmiany, to jest to bardzo opłacalne.
To co ja polecam autorowi postu @winnxan, to jak to zrobić w miarę prosto i szybko. Czyli albo pliki (jeśli woli) albo SQLite (jeśli woli to). Nie widzę nic złego w takiej radzie. Jeśli masz rację, i faktycznie @winnxan natrafi na jeden z problemów które opisałeś, wtedy będziemy mieli konkretny use-case i będziemy mogli znaleźc odpowiednie rozwiązanie tego problemu.
Dodatkowo mamy też kolejny aspekt - tego że @winnxan się dopiero uczy, więc możliwe że to będzie nawet lepiej dla niego jeśli natrafi na problem ze wspólbieżnością lub obsługą IO. Będzie to dla niego szansa żeby się czegoś nauczyć. Jeśli damy mu narzędzie które wszystko ogarnie dla niego, takiej okazji nie ma. Taka nauka może być cenniejsza niż wytworzenie od razu niezawodnej aplikacji.
4
Riddle napisał(a):
Widzę w Twoich postach na forum od bardzo dawna taką postawę: "zróbmy coś od razu, za pierwszym razem".
Tak, jeśli jestem w stanie przewidzieć przyszłe problemy lub mam doświadczenie z przeszłości że takie problemy wystąpiły (a w tym przypadku mam) to wolę zrobić coś raz a dobrze.
Riddle napisał(a):
Tymczasem moim zdaniem to jest bardzo słabe podejście. Ja preferuję zacząć od czegoś najprostszego, co ma szansę zadziałać - w tym wypadku pliki.
Moim zdaniem bazy danych są prostsze i rozwiązują tu wszystkie możliwe problemy nie wprowadzając nowych. Kod jest krótszy, prostszy, czytelniejszy, ma jedynie minimalnie większy próg wejścia ale czas poświęcony na naukę szybko się zwraca. Całą komplikację przejmują na siebie twórcy silników baz danych - bazy danych z założenia mają być prostsze niż pliki. To wręcz narzędzie upraszczające trzymanie danych w plikach.
Riddle napisał(a):
to są problemy które mogą wystąpić, możliwe że nawet jest duża szansa że wystąpią - ale należy te problemy rozwiązać wtedy kiedy (jeśli) wystąpią, a nie od razu.
Bardzo ciekawe podejście, podejrzewam że crowdstrike ma podobne.
Ja mam wrażenie że za bardzo do siebie wziąłeś problem przedwczesnej optymalizacji, YAGNI i rozszerzyłeś to na przewczesne zapobieganie błędom.
Mnie natomiast uczono i uczulano że poprawianie błędów na produkcji kosztuje kilkadziesiąt razy więcej niż w fazie planowania
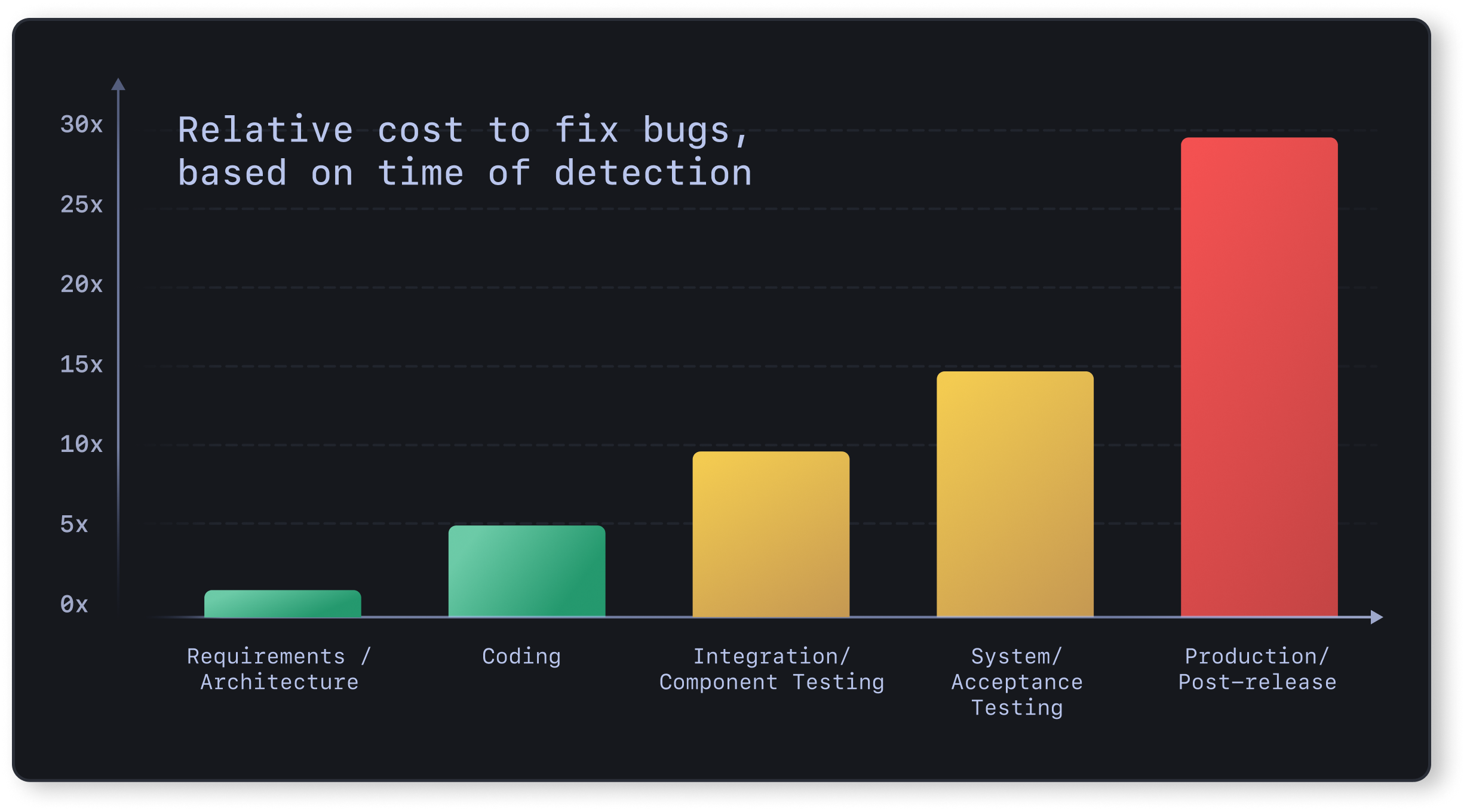
W przedwczesnej optymalizacji też nie chodzi o to że mając do wyboru dwa algorytmy o złożoności log n i n^2 wybierasz ten gorszy dopóki nie potrzebujesz tego lepszego. Natomiast z moich obserwacji większość osób tak właśnie postępuje.
1
A ja mam teraz mieszane uczucia.
Z jednej strony rozumiem @Riddle i postawę, że jak się zaczną problemy to będziemy je wyjaśniać i naprawiać. Nie ma co się martwić na zapas (YAGNI, premature optimization czy nazwijcie to jak chcecie) i rozwiązywać problemów, które nie istnieją i być może się nigdy nie pojawią. Poza tym - licznik wejść nie jest kluczowym elementem strony (w odróżnieniu od np. systemu logowania), a sama strona raczej jakoś bardzo popularna ani wartościowa nie będzie.
Z drugiej strony - rzeczywiście, operowanie na pliku tekstowym jest czymś, co może (jak słusznie wykazał @obscurity ) się wywalić na przynajmniej kilku płaszczyznach/w kilku wariantach. Także rozumiem też podejście, żeby uniknąć takich prowizorek i zrobić to chociażby w oparciu o SQLite, które eliminuje 90% (jak nie więcej) ewentualnych problemów, które mogą się pojawić przy pliku TXT.
Jeśli wystąpią od razu, to i tak wyjdzie na Twoje - naprawimy je od razu odpowiednim rozwiązaniem
[...]
jeśli zbuduje się ten software tak, że zostawi się sobie furtkę do przyszłej zmiany
Tutaj porada w kierunku @winnxan - zrób jakąś abstrakcję na żródło danych. Jak w kodzie będziesz chciał gdzieś się odwołać do licznika, to nie rób tego bezpośrednio, czyli coś w stylu
function DodajWejścieNaStronę() {
$baza = polaczZbaza();
$licznik = $baza.odczytajLicznik();
inc($licznik);
$baza.zapiszLicznik($licznik);
$baza.zamknij();
}
Tylko ukryj szczegóły implementacyjne w jakimś mechanizmie/obiekcie/jakichś funkcjach pomocniczych, obudowujących komunikacje z bazą/plikiem. W ten sposób ewentualna przesiadka z plików TXT na SQLite, albo z SQLite na "prawdziwego" SQL przejdzie (z punktu widzenia kodu ogarniającego logikę biznesową) bezproblemowo. W momencie zmiany stanu licznika wywołasz (dokładnie tak samo, jak przed zmianą) funkcję ZwiekszLicznik() i nie będzie Cię interesować, jak technicznie ona to ogarnie. I, zamiast poprawiać kod w X miejscach, poprawisz tylko w jednym miejscu (czyli w ciele tej funkcji, bo tam jedynie jest komunikacja z bazą), a cała pozostała część aplikacji nawet nie będzie wiedziała, że jakakolwiek zmiana pod spodem miała miejsce.
0
obscurity napisał(a):
Moim zdaniem bazy danych są prostsze i rozwiązują tu wszystkie możliwe problemy nie wprowadzając nowych. Kod jest krótszy, prostszy, czytelniejszy, ma jedynie minimalnie większy próg wejścia ale czas poświęcony na naukę szybko się zwraca. Całą komplikację przejmują na siebie twórcy silników baz danych - bazy danych z założenia mają być prostsze niż pliki. To wręcz narzędzie upraszczające trzymanie danych w plikach.
Jak już umiesz obsługiwać bazy danych, faktycznie to jest łatwiejsze, więc tu się nawet mogę zgodzić.
Ale jak nie umiesz (tak jak sie spodziewam że @winnxan mógł jeszcze z nimi nie pracować), to może to być dużo trudniejsze. Trzeba znać sposób pracy z bazą: tabele, migracje, scheme'a, nazwę bazy, connection stringi, trzeba się nauczyć API do bazy, czyli w PHP albo PDO albo funkcje sqlite_; dochodzi cała nomeklatura związana za bazami: transakcje, indeksy, typy pól.
Jeśli nie pracowałes nigdy z bazami danych, to wcale to nie jest prostsze, przynajmniej nie na początku, dlatego zaproponowałem OP dwie opcje. Postaraj się wejść w jego buty.
obscurity napisał(a):
Riddle napisał(a):
Widzę w Twoich postach na forum od bardzo dawna taką postawę: "zróbmy coś od razu, za pierwszym razem".
Tak, jeśli jestem w stanie przewidzieć przyszłe problemy to wolę zrobić coś raz a dobrze.
Też wolałbym zrobić "raz a dobrze", gdybym miał taką opcję - ale tworząc software często nie mamy takiej opcji. Często trzeba się uczyć, poznawać nowe rzeczy, wychodzą nowe case'y, nowe requirementy, rzeczy których nie przewidzieliśmy, nowe przypadki.
Więc w 95% przypadków przewidzenie wszystkiego za wczasu zwyczajnie jest niemożliwe. Trzeba mieć rozeznanie - co faktycznie teraz muszę zrobić, a czego jeszcze nie muszę, żeby zachować jakość. Jeśli ja robię np. operacje na bazie danych, to użyję od razu prepared statements zamiast sklejania stringów (bo wiem że obronę przed sqlinjection muszę zrobić od razu), ale nie dodam jeszcze transakcji, jeśli nie mam use-case'u pod nie. Dodam je, jak będę miał faktyczny requirement. Bo albo requirement przyjdzie (i tak czy tak będe musiał to dodać, i wtedy nic nie trace, a mogę zyskac, bo będzie to późniejszy etap projektu, i będę o nim wiedział więcej), albo nie przyjdzie, i wtedy oszczędzę czas i będę miał prostszy program z mniejszą ilością kodu i założeń.
Wydaje mi sie że wychodzisz z założenia że podczas życia projektu nie uczysz się czegoś nowego, i na początku projektu wiesz tyle ile na końcu. Gdyby tak było to masz rację - i warto zrobić wszystko od razu. Ale moim zdaniem tak nie jest. Choćbyś miał 20 lat doświadczenia, to i tak jak robisz nowy projekt, to podczas jego trwania uczysz się nowych rzeczy, zdobywasz nową wiedzą, na końcu projektu wiesz więcej niż na początku, wiec decyzje warto odroczyć w czasie, a problemy rozwiązywać kiedy wystąpią, a nie wcześniej.
Riddle napisał(a):
Bardzo ciekawe podejście, podejrzewam że crowdstrike ma podobne.
Czym innym jest nie zabezpieczanie się przed czymś co znasz (i wiesz na 100% że musisz mieć); a czym innym jest programowanie na przyszłość (i zgadywanie potencjalnych problemów których jeszcze nie masz).
0
Ale jak nie umiesz (tak jak sie spodziewam że @winnxan mógł jeszcze z nimi nie pracować), to może to być dużo trudniejsze. Trzeba znać sposób pracy z bazą: tabele, migracje, scheme'a, nazwę bazy, connection stringi, trzeba się nauczyć API do bazy, czyli w PHP albo PDO albo funkcje sqlite_; dochodzi cała nomeklatura związana za bazami: transakcje, indeksy, typy pól.
No ale też nie popadajmy w paranoję - to ma być tylko baza, która trzyma licznik wyświetleń. Jedna tabela z 2-3 kolumnami, indeksy przy takiej ilości wejść, jaką zakładamy/podejrzewamy nie będą potrzebne. Samo działanie z baza w tak prostym scenariuszu sprowadza się do dosłownie 3 funkcji i 2-3 zapytań.
Także OK, rozumiem i zgadzam się, że pierwsze podejście do SQL może być trochę trudne, ale też nie przesadzajmy, nie jest to roket sajens ;)
1
Riddle napisał(a):
Czym innym jest nie zabezpieczanie się przed czymś co znasz (i wiesz na 100% że musisz mieć); a czym innym jest programowanie na przyszłość (i zgadywanie potencjalnych problemów których jeszcze nie masz).
Oni wtedy jeszcze nie znali...
Czym innym jest też zgadywanie potencjalnych problemów a czym innym ignorowanie problemów z którymi ktoś już miał styczność lub które na logikę wystąpią.
Jak wpadniesz na pomysł potecjalnego problemu to warto przetestować czy faktycznie taki scenariusz może wystąpić (w tym przypadku wystarczy lekki spam przez postmana) a nie zignorować myśl aż problem wystąpi na produkcji.
Riddle napisał(a):
Też wolałbym zrobić "raz a dobrze", gdybym miał taką opcję - ale tworząc software często nie mamy takiej opcji. Często trzeba się uczyć, poznawać nowe rzeczy, wychodzą nowe case'y, nowe requirementy, rzeczy których nie przewidzieliśmy, nowe przypadki.
Ale w tym przypadku znasz lepsze rozwiązanie a mimo to wybierasz gorsze bo może się okazać wystarczające. To nie ma dla mnie żadnego sensu.
Powtórzę się bo edytowałem post wyżej
W przedwczesnej optymalizacji też nie chodzi o to że mając do wyboru dwa algorytmy o złożoności log n i n^2 wybierasz ten gorszy dopóki nie potrzebujesz tego lepszego. Natomiast z moich obserwacji większość osób tak właśnie postępuje.
Jeśli optymalizacja nic nie kosztuje i jest jedynie prostym wyborem między dwoma rozwiązaniami z czego jedno jest wyraźnie lepsze to zawsze warto wybrać to lepsze. To nie jest przedwczesna optymalizacja jeśli wybierzemy quick sort zamiast bubble sort. Co innego jak znasz tylko "bubble sort" i musiałbyś robić research jak go przyspieszyć mimo że nie ma takiej potrzeby.
0
obscurity napisał(a):
Ale w tym przypadku znasz lepsze rozwiązanie a mimo to wybierasz gorsze bo może się okazać wystarczające. To nie ma dla mnie żadnego sensu.
Po pierwsze - nie wybieram gorsze. Zaproponowałem OP dwa rozwiązania: jedno na plikach, jedno na SQLite, i powiedziałem że może sobie wybrać które mu bardziej pasuje, to raz. Tutaj masz link do postu nawet: Licznik odwiedzin za ostatnie 24h
Po drugie, to nie jest tak że "specjalnie wybieram gorsze, bo może się okazać wystarczające". Mówisz z perspektywy człowieka który rozumie bazy danych i umie się nimi posługiwać (bazy, tabele, migracje, schema, typy pól). Dla Ciebie to jest łatwe i trywialne. Ja, gdybym budował taką aplikację za pewne też dodałbym SQLite od razu. Zrobiłbym coś co daje mi największy zysk najmniejszym kosztem. Kierowałbym się argumentami takimi jak:
- jak szybko mogę to teraz zrobić?
- jak trudne jest to do zrobienia teraz?
- czy rozwiąże to problemy które mam teraz?
- Czy bardzo niskim kosztem jestem w stanie dowieźć maksymalną jakość oprogramowania?
- Czy mogę zerowym kosztem (nie małym, tylko zerowym, powiedzmy mniej niż kilkanaście sekund mojego czasu) naprawić potencjalny problem w przyszłości? Jeśli tak, to super.
Myślę że Ty miałbyś podobne. Tylko Ty dodatkowo dociągasz jeszcze jeden:
- Czy mogę dopłacić jakiś dodatkowy koszt (mały lub duży, dłuższy niż kilka minut), zeby rozwiązać potencjalny problem w przyszłości? (Bo uważasz że jeśli taki problem wystąpi, a Ty się na niego nie przygotujesz, to cena naprawienia go będzie wtedy większa).
Dobrze rozumiem? Bo moim zdaniem cena nie będzie większa, będzie podoba; lub nawet niższa. Dlatego że ja uważam że jak rozwiązujesz problem później, to masz więcej wiedzy o projekcie, i możesz go lepiej rozwiązać. Dodatkowo, jeśli ten problem nigdy nie wystąpi, to zmarnowałeś ten czas który poświęciłeś na rozwiązanie tego problemu. Uważam że ten wykres który wkleiłeś, nie wiem do końca co on oznacza, i jakimi kryteriami był mierzony, ale ja nie zaobserwowałem nigdy czegoś takiego, że jeśli zaimplementuje feature lub dodam pewną funkcjonalność później, to będzie to droższe lub trudniejsze. Tak jest w zasadzie tylko w legacy systemach gdzie jest spaghetti code.
Sytuacja w której możesz przewidzieć problemy, i rozwiązać je za wczasu występuje wtedy, kiedy wiesz o projekcie, i wiesz co będzie trzeba w nim zrobic. Moim zdaniem taka sytuacja nie występuje w programowaniu. Wyobrażam sobie że występuje tylko wtedy kiedy klepiesz kilka razy te same aplikacje, do tego stopnia że znasz je na wylot (tylko wtedy pojawia się pytanie po co pisać je kilka razy, skoro można po prostu użyć poprzedniej).
@obscurity Domyślam się, że może pracujesz w pracy przy dużym projekcie który już żyje kilka lat, i wprowadzanie do niego zmian jest kosztowne. Do tego stopnia kosztowne, że czasem bardziej Ci się opłaca zrobić dużo rzeczy za wczasu (nawet jak się okażą niepotrzebne), bo finalnie i tak to się opłaci. Rozumiem, bo ja też pracowałem w takich projektach - tylko że to jest wysoce nieoptymalne, praca w takim środowisku. To co ja zrobiłbym, gdybym się w takim znalazł, to zastanowił się - "czemu do cho*lery naprawianie problemów później jest takie kosztowne", bo wiem że nie powinno. Szukałbym przyczyny, aż bym ją znalazł, tak żebym mógł poprawić problem kiedy wystąpi, a nie gdybać.
Jest trochę prawdy w tym wykresie - jeśli mamy zbyt długi feedback loop (rzędu tygodni lub miesięcy), to faktycznie wprowadzanie zmian jest trudniejsze. Ale odpowiedzią na to nie jest "przewidź potencjalne problemy", rozwiązaniem na to jest - skróć feedback loop, tak żebyś mógł rozwiązywać tylko istniejące problemy; a przyszłe, żebyś miał na tyle swobody i szybkości i łatwości w operowaniu żebyś mógł je naprawić kiedy wystapią.
2
No nie, właśnie mam podejście takie:
- Czy mogę zerowym kosztem (nie małym, tylko zerowym, powiedzmy mniej niż kilkanaście sekund mojego czasu) naprawić potencjalny problem w przyszłości? Jeśli tak, to super.
Natomiast z tego co pisałeś wcześniej odniosłem wrażenie że masz podejście
- YOLO, jako tako i pora na csa. Jak będzie problem to się poprawi.
;)
Riddle napisał(a):
Dobrze rozumiem? Bo moim zdaniem cena nie będzie większa, będzie podoba; lub nawet niższa.
No z mojego doświadczenia jest znaaacznie większa. Często np dane w bazie już są uszkodzone i trzeba przykładowo pisać narzędzie żeby je zrekonstruować na przykład z danych audytu, albo innych tabel, lub ręcznie poprawiać, nie licząc kosztu ponownej implementacji, testowania, angażowania BA, QA, wdrożenia itp, ale nawet jeśli przykładowa poprawka to tylko dodanie indeksu na tabeli to często nie da się jej zrobić live bo jest za dużo danych, trzeba robić maintenance window, tysiąc zgód, presja czasowa żeby się wyrobić w okienku bo nie można wstrzymywać produkcji na zbyt długo itp.
Ogólnie wolę sobie tego oszczędzić w miarę możliwości.
1
obscurity napisał(a):
No nie, właśnie mam podejście takie:
- Czy mogę zerowym kosztem (nie małym, tylko zerowym, powiedzmy mniej niż kilkanaście sekund mojego czasu) naprawić potencjalny problem w przyszłości? Jeśli tak, to super.
No to ja myślałem że masz to:
Riddle napisał(a):
- Czy mogę dopłacić jakiś dodatkowy koszt (mały lub duży, dłuższy niż kilka minut), zeby rozwiązać potencjalny problem w przyszłości? (Bo uważasz że jeśli taki problem wystąpi, a Ty się na niego nie przygotujesz, to cena naprawienia go będzie wtedy większa).
Dlatego że dla OP @winnxan zrobienie SQLite nie będzie zerowym kosztem, jak nigdy z tym nie pracował. Pewnie zajmie mu to dłużej niż na plikach.
obscurity napisał(a):
Natomiast z tego co pisałeś wcześniej odniosłem wrażenie że masz podejście
- YOLO, jako tako i pora na csa. Jak będzie problem to się poprawi.
;)
No na pewno nie. Jak zobaczę że ktoś tak w zespole robi to będzie pierwszy do odstrzału. Jakość ma być najwyższa jak się da - ale ma rozwiązywać aktualne problemy. I aktualne problemy mają być rozwiązane na tip-top. Przyszłe - nie koniecznie. Dopiero wtedy kiedy wystąpią.
To co ja mówię to to - ludzie przywykli przez pracę w legacy code do tego, żeby podejmować decyzje za wczasu. Moim zdaniem to błąd, bo na początku projektu wiesz najmniej o nim. Nikt na początku projektu nie podejmie dobrych decyzji, bo nie mają dostatecznej wiedzy (chyba że mają kryształowa kulę, umieją przewidywać przyszłość, albo piszą dokładnie ten sam program któryś raz z kolei).
Z tej uwagi - moim zdaniem - należy podjąć bardzo dobrej jakości decyzje, ale dopiero kiedy mamy konieczność to zrobić, i mamy jaknajwięcej wiedzy o projekcie ile możemy to zrobić. Da się to zrobić jak masz krótki feedback loop, jesteś w stanie zrobić release w kilka minut, masz bardzo dobre testy automatyczne, dobry design aplikacji, nie masz micromanagementu w pracy. Wtedy to jest optymalne. Decyzja podjęta wcześniej jest gorszej klasy (bo nie masz dostatecznego info).
Riddle napisał(a):
No z mojego doświadczenia jest znaaacznie większa. Często np dane w bazie już są uszkodzone i trzeba pisać narzędzie żeby je zrekonstruować na przykład z danych audytu, nie licząc kosztu ponownej implementacji, testowania, angażowania BA, QA, wdrożenia itp, ale nawet jeśli przykładowa poprawka to tylko dodanie indeksu na tabeli to często nie da się jej zrobić live bo jest za dużo danych, trzeba robić maintenance window, tysiąc zgód, presja czasowa żeby się wyrobić w okienku bo nie można wstrzymywać produkcji na zbyt długo itp.
Ogólnie wolę sobie tego oszczędzić w miarę możliwości.
Rozumiem to. Brzmi jak istotne przeszkody.
-
Często np dane w bazie już są uszkodzone i trzeba pisać narzędzie żeby je zrekonstruować na przykład z danych audytuCelna uwaga. Dlatego pisałem o tym, że wprowadzając "łatwiejsze rozwiązania" trzeba sobie zostawić furtke na wprowadzenie potem bardziej zaawansowanych. Jeśli wiem że pośrednie rozwiązanie sprawi że wprowadzenie potem bardziej zaawnsowanego coś zepsuje, np. uszkodzi dane w bazie, to trzeba się wtedy dwa razy zastanowić jak to zrobić. Albo je faktycznie zaimplementować od razu; albo zaimplementować rozwiązanie pośrednie, tak żeby nie uszkodzić tych danych.
Taką furtką może być np. osobny interfejs, który @cerrato proponował kilka postów wyżej. -
nie licząc kosztu ponownej implementacji, testowania, angażowania BA, QA, wdrożenia itpFaktycznie ciężko się pracuje w firmie, w której to tyle trwa. Ale w dobrym projekcie koszt implementacji, testowania, BA, QA, wdrożenie powinien być mały, nie ważne co robisz. Jeśli cały cykl zajmuje kilka godzin, lub co gorsza dni, tygodni lub miesięcy, to masz prze**ane. To powinno trwać minuty, max godziny (ale godziny to na prawdę wielkich kobyłach). -
ale nawet jeśli przykładowa poprawka to tylko dodanie indeksu na tabeli to często nie da się jej zrobić live bo jest za dużo danych, trzeba robić maintenance window. Też celna uwaga. Tyczy się furtki o której mówiłem. Jeśli dodanie ideksu jest trywialne (np. sekundy), i nie komplikuje programu, to dodaj go od razu. Ale jeśli dodanie takiej optymalizacji miałoby zająć więcej czasu, lub miałoby skomplikować kod, należy zrobić rozwiązanie które działa "na teraz", ale zostawia furtkę do bardziej zaawansowanych rozwiązań. Może tak być że zrobienie furtki zajmie więcej niż faktyczne rozwiązanie. Wtedy to nie ma sensu, i mozna zaimplementować całośc od razu. Ale często zrobienie furtki się udaje, i jest tańsze i szybsze. Dodatkowa zaleta z furtki jest taka, że jeśli zrobimy rozwiązanie później, to mamy więcej wiedzy o projekcie, i rozwiązanie które znajdziemy potem często okazuje się lepsze, niż to które wymyślilibyśmy wczesniej (mając mniejszą wiedzę). -
tysiąc zgód- again, tak nie powinno być. Jeśli jesteś programistą odpowiedzialnym za swoją pracę, to powinieneś móc wprowadzić poprawkę sam, albo zespół powinien bez zgód. Jesli pracujesz w firmie w której musisz dostawać zgody na zrobienie czegoś koniecznego, to nadal to jest przerypana praca. Najlepszej jakości software powstaje w miejscach w którym pracownikom ufa się że wykonają coś koniecznego. Jeśli aplikacja spowalnia, i konieczne jest dodanie poprawki - to powinieneś móc to zrobić bez żadnych zgód.
0
jest nowy problem bo jednak nie chce zmieniać rozszerzenia pliku index z html na php to moze rozwalic mi seo i musiałbym zmieniac całe linkowanie wewnetrzne w stronie itp
Wymyśliłem wiec że moze użyje cronjob na serwerze ktory pobiera wartość lastline (czyli ostatni zapis a awstats robi to co godzine updatuje ile weszło ludzi wiec idealnie)
Czyli byłoby otworz awstats > kopiuj lastline wartość > otwórz index.html > wklej wartość w wyznaczonym div z takim id albo class > zapisz > zamknij index.html
Proszę o odpowiedź czy coś takiego jest możliwe do zrobienia.
Jeżeli tak to może ktoś pokusi się o napisanie kodu bo tego to ja już na pewno sam nie napisze.
0
zmiana rozszerzenia nie musi oznaczać zmianę linka widocznego z zewnątrz, masz na przykład mod_rewrite w apache czy co tam się teraz używa do hostowania php
0
musiałbym zmieniac całe linkowanie wewnetrzne w stronie
Mamy 2024, a nadal phpowcy mają problemy z tworzeniem linków i wszędzie mamy brzydkie rozszerzenia .php w adresach. Spójrz na to forum - widzisz gdzieś że to pehap? :) anyway
Czyli byłoby otworz awstats > kopiuj lastline wartość > otwórz index.html > wklej wartość w wyznaczonym div z takim id albo class > zapisz > zamknij index.html
Po kiego grzyba chcesz edytować plik index.html? Nie prościej zrobić osobny plik z tym co chcesz, a w index.html (tudzież tym nieszczęsnym index.php) po prostu wczytać ten plik? Ewentualnie jak nie da rady zrobić tak prostej rzeczy, to możesz użyć <iframe/> i po prostu wciągnąć ten plik w aktualną stronę po stronie przeglądarki - to może być akceptowalne obejście.
Zarejestruj się i dołącz do największej społeczności programistów w Polsce.
Otrzymaj wsparcie, dziel się wiedzą i rozwijaj swoje umiejętności z najlepszymi.