Mam pytanie na które nie mogę znaleźć odpowiedzi, mianowicie jak obciążające dla procesorów jest "przepinanie" się z wykonywania wątku na inny wątek. Aby zostać dobrze zrozumianym postaram się przybliżyć problem podając przykład(procesor 1 rdzeniowy), jest aplikacja a i aplikacja b. Aplikacja a posiada 10000 wątków(wątki powołane są na początku, tzn. nie kaskadowo podczas działania programu), każdy wątek wykonuje operacje dodania jedynki do statycznej zmiennej i rozpoczyna działanie kolejnego wątku. Aplikacja b ma jedynie 1 wątek i wartości dodaje w pętli aż zmienna osiągnie wartość 10000. Zakładam, że aplikacja b wykona się szybciej bo procesor nie będzie przepinał się z wątku na wątek(proszę o pominięcie obciążenia wynikającego z powoływania samych wątków w programie itd., tylko obciązenie wynikające z "przepięcia"). Jak dużym wysiłkiem jest operacja którą opisałem?
- Rejestracja:prawie 8 lat
- Ostatnio:prawie 5 lat
- Postów:25

- Rejestracja:prawie 20 lat
- Ostatnio:około 3 godziny
Problem jest złożony, bo jest wiele czynników wpływających na koszt przełączania kontekstu (ang. "context switch" i tego szukaj w google). Przełączenie kontekstu wiąże się np z koniecznością przeładowania danych, bo często poprzedni wątek wrzuca sobie do pamięci podręcznej L1, L2, L3, itd dane, które obecnemu wątkowi są niepotrzebne, a wyrzucił te które są potrzebne.
Przykładowe wyniki są np tutaj: http://www.cs.rochester.edu/u/cli/research/switch.pdf
W rzeczywistości nie tworzy się setek wątków, no chyba że korzystamy z blokującego I/O i działamy na setkach plików jednocześnie - takich sytuacji najlepiej unikać, bo tutaj jest ryzyko że sumaryczna wielkość stosów dla wszystkich wątków spowoduje zapchanie pamięci. Zamiast tworzenia setek wątków tworzy się pulę tylu wątków ile jest logicznych rdzeni procesora, a potem wrzuca się do tej puli wątków zadania.
W twoim przykładzie nawet gdyby tworzenie i przełączanie wątku miały zerowy narzut to i tak wersja wielowątkowa byłaby wolniejsza. Dzieje się tak dlatego, że współdzielony mutowalny stan musi być jakoś synchronizowany między wątkami. Tutaj można by użyć atomic integerów i w ten sposób uniknąć monitorów, ale i tak będzie spowolnienie w stosunku do jednego wątku. Inkrementacja atomic integera polega na operacji compare-and-swap. Jeśli wiele wątków jednocześnie zmodyfikuje atomic integera to tylko jednemu operacja się powiedzie za pierwszym razem, a reszta będzie musiała ponawiać operację, aż do skutku. Bez użycia atomic integerów czy innej metody synchronizacji współdzielonego mutowalnego stanu dostaniesz złe wyniki będące następstwem https://en.wikipedia.org/wiki/Race_condition
Aby uzyskać jak największe przyspieszenie z wielowątkowości trzeba przerobić algorytm tak, by wątki jak największą część czasu pracowały na oddzielnych danych - bez synchronizacji między sobą. Sprawdź np: https://en.wikipedia.org/wiki/Amdahl%27s_law

- Rejestracja:ponad 10 lat
- Ostatnio:prawie 2 lata
- Postów:2500
Zależy od procesora, systemu, architektury. W tym teoretycznym przykładzie koszt będzie wielokrotnie większy niż właściwa operacja, bo sama operacja jest trywialna, a zmiana kontekstu to co najmniej zapisanie/wczytanie rejestrów, bieżącej instrukcji itd. Wpisz w google'a thread context switch overhead i popatrz na 10 pierwszych linków.

- Rejestracja:około 21 lat
- Ostatnio:prawie 3 lata
- Lokalizacja:Space: the final frontier
- Postów:26433
Wątki są generalnie dość "lekkie" i współdzielą dość sporo między sobą, w tym sekcje kodu i pamięć. W efekcie narzut będzie dość niewielki, bo możliwe że nawet cache będzie tu działać poprawnie i mimo context switcha wątku dostęp do danych i do instrukcji poleci z cache.
Nadal będzie to dużo wolniejsze niż ten jeden wątek oczywiście.
W rzeczywistości wątki często pracują na osobnych blokach pamięci i wtedy każdy context switch wymaga wymiany data cache. Dodatkowo często jeśli masz wiele wątków to robią one inne operacje więc wymaga to też wymiany instruction cache co context switch. W takiej sytuacji zaczyna sie to robić dużo cięższe.
- Rejestracja:około 9 lat
- Ostatnio:około 2 lata
Co do lekkości wątków -- w Linuxie na przykład można (szczegółów nie pamiętam teraz) ustawić sobie co dzielą wątki/procesy, a co mają osobne. W związku z tym niektóry wątki mogą być bardzo lekkie (dzielą prawie wszystko) i ich przełączanie będzie szybkie. Ale oczywiście wolniejsze niż nieprzełączanie. Na drugim krańcu mamy procesy czyli wątki ciężkie, które wszystko co się da mają osobne...

Kompletne bzdury opowiadasz - jak głupie dziecko!
Zwłaszcza to:
Aby zostać dobrze zrozumianym postaram się przybliżyć problem podając przykład(procesor 1 rdzeniowy), jest aplikacja a i aplikacja b. Aplikacja a posiada 10000 wątków(wątki powołane są na początku, tzn. nie kaskadowo podczas działania programu), każdy wątek wykonuje operacje dodania jedynki do statycznej zmiennej i rozpoczyna działanie kolejnego wątku.
Tworzenie wątków być może jest nieco bardziej czasochłonne od ich uruchamiania,
niemniej każda z tych operacji to grube setki instrukcji/operacji procesora;
a dodawanie to zaledwie jedna instrukcja - 1 takt!
Ale i to mało!
Przy używaniu - współdzieleniu jednej zmiennej przez wiele wątków,
musiałbyś bookować dostęp do tej zmiennej - to tzw. critical section w tej terminologii,
inaczej otrzymałbyś prędzej coś w stylu rosyjskiej ruletki, zamiast dodawania.
- Rejestracja:prawie 8 lat
- Ostatnio:prawie 5 lat
- Postów:25
bjjjjjjjjjjjj napisał(a):
Kompletne bzdury opowiadasz - jak głupie dziecko!
Zwłaszcza to:
Aby zostać dobrze zrozumianym postaram się przybliżyć problem podając przykład(procesor 1 rdzeniowy), jest aplikacja a i aplikacja b. Aplikacja a posiada 10000 wątków(wątki powołane są na początku, tzn. nie kaskadowo podczas działania programu), każdy wątek wykonuje operacje dodania jedynki do statycznej zmiennej i rozpoczyna działanie kolejnego wątku.
Tworzenie wątków być może jest nieco bardziej czasochłonne od ich uruchamiania,
niemniej każda z tych operacji to grube setki instrukcji/operacji procesora;
a dodawanie to zaledwie jedna instrukcja - 1 takt!Ale i to mało!
Przy używaniu - współdzieleniu jednej zmiennej przez wiele wątków,
musiałbyś bookować dostęp do tej zmiennej - to tzw. critical section w tej terminologii,
inaczej otrzymałbyś prędzej coś w stylu rosyjskiej ruletki, zamiast dodawania.
Chyba czegoś nie zrozumiałeś, ja tutaj nie wygłaszam żadnej tezy tylko pytam jak to wygląda. Nawet jeśli przykład nie jest najlepszy to obrazuje to co miałem na myśli.

- Rejestracja:ponad 19 lat
- Ostatnio:ponad 6 lat
Chyba czegoś nie zrozumiałeś, ja tutaj nie wygłaszam żadnej tezy tylko pytam jak to wygląda. Nawet jeśli przykład nie jest najlepszy to obrazuje to co miałem na myśli.
Obawiam się że ty nie rozumiesz podstaw logiki, że takie idiotycznie problemy rozważasz... i do tego publicznie. :)
Problem postawiony przez autora może nie został czytelnie sformułowany, ale jak najbardziej jest zasadne stawianie takich pytań.
Odpowiedź jest niestety dość skomplikowana.
Samo przełączenie kontekstu kosztuje zwykle tyle co syscall + troszkę pracy kernela nad tym aby zapisać stan wątku, zmodyfikować jego status (np. informację dlaczego wątek musi być wywłaszczony), znaleźć inny wątek do wykonania, załadować i przywrócić kontrolę do nowego wątku. To wyjdzie znacznie więcej niż proste dodawanie, ale myślę, że w kilku tysiącach cykli powinno się zamknąć.
To jednak nie jest najgorsze.
Większym problemem jest cache - nowy wątek zapewne wywali z cache procesora dane poprzedniego wątku. Sam za to będzie pracował na początku na zimnym cache, tj. spodziewaj się dużo nietrafień w cache, zwłaszcza jeśli drugi wątek operuje w obrębie innego kodu. Jeden cache miss to znowu setki jak nie tysiące cykli oczekiwania, aczkolwiek to się nie dodaje tak wprost, CPU potrafi przewidywać dostępy i ładować do cache zawczasu. Tak czy inaczej - tuż po przełączeniu wątek będzie pracował wolniej.
Teraz, jeżeli wątki nawzajem nie posiadają żadnej zależności, to OS będzie przełączał się między nimi na tyle często, aby sprawiać wrażenie równoczesności, ale na tyle rzadko aby nie powodowało to dużego narzutu. Zwykle kilkadziesiąt razy do tysiąca razy na sekundę. Wtedy sumaryczny koszt przełączania będzie niewielki, bo te kilkadziesiąt tysięcy taktów procesora zmarnowanych w wyniku przełączenia będzie niczym wobec milionów taktów dostępnych pomiędzy przełączaniem (zakładam, że procesor pracuje z częstotliwością rzędu GHz).
Dużo większy problem się pojawia, jeśli wątek zależy od innego wątku i musi się co chwilę zatrzymywać. Np. próbuje wejść w sekcję krytyczną albo blokująco czytać dane z socketa, który nie ma jeszcze danych. Wtedy wątek ręcznie wymusza przełączenie - tzn. wywołuje syscall odpowiedzialny za np. czytanie z socketa, a OS widzi że nie ma danych i usypia wątek do czasu jak dane się w buforze pojawią. Jeśli np. co tysiąc taktów będzie przełączanie kontekstu, bo wątek chodzi w ciasnej pętli, która ma w środku takiego "blockera", to wtedy się okaże, że większość czasu CPU spędza wykonując kod kernela przełączający wątki lub czekając na pamięć. W takiej sytuacji odpalenie większej liczby wątków nie zwiększy wydajności programu, a ją zmniejszy.
No i jest jeszcze jedna rzecz, niezwiązana z przełączaniem kontekstu:
każdy wątek wykonuje operacje dodania jedynki do statycznej zmiennej
Nie rób tak nigdy. Z dwóch powodów:
- nie da to rezultatów, których oczekujesz - wyniki będą niepoprawne, bo dodawanie to "odczyt + dodawanie w rejestrach + zapis". Dwa wątki mogą odczytać tę samą wartość równocześnie i dodać do niej jeden - w ten sposób licznik będzie wskazywał mniej niż powinien.
- zabije to wydajność na procesorach wielordzeniowych - dodawanie jest szybkie, ale zapis do tej samej linii cache przez dwa rdzenie to wydajnościowa masakra. Ponieważ cache w x86/amd64 jest koherentny, każdy zapis unieważnia linie cache w cache L1/L2 innych rdzeni. Zanim zapis będzie możliwy, linia cache musi być "czysta", więc musi być najpierw zassana z L3 aby można ją było zmodyfikować. Nie jest to tak duży koszt jak przełączenie kontekstu, ale porównaj sobie:
- operacja dodawania intów: zwykle mniej niż takt (tzn. można nawet zrobić 4 w jednym; na różnych potokach, abstrahując tu na razie od SSE/AVX).
- dostęp do cache L3: 65 cykli (40 cykli, jeśli linia nie jest współdzielona).
Do zliczania operacji z wielu wątków należy stosować odpowiedni algorytm użyty np. w LongAccumulator.
BTW: tu się czai kolejna pułapka, bo modyfikowanie dwóch różnych zmiennych przez różne wątki też może powodować ww efekt spadku wydajności - wystarczy, że obie zmienne leżą tuż bok siebie w pamięci, na tej samej linii cache - pogooglaj "false sharing".
powerstat -D to przy bezczynności mam kilkutysięczne wartości w kolumnie Ctxt/s. Po włączeniu filmu na YouTube wartości skaczą do poziomu kilkudziesięciu tysięcy.
- Rejestracja:prawie 20 lat
- Ostatnio:około 3 godziny
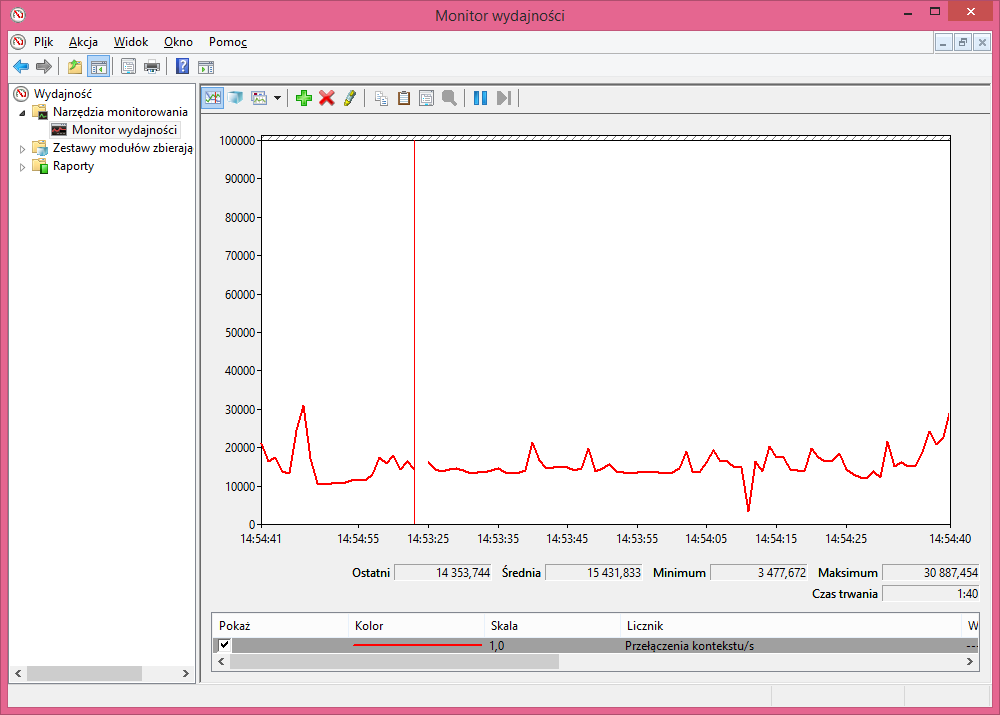
Z ciekawości sprawdziłem ile razy Windows 8.1 przełącza kontekst na sekundę. Żeby to sprawdzić trzeba wejść w Narzędzia Administracyjne, a potem Monitor Wydajności. Później trzeba przejść do wykresu (pokazane na zrzucie ekranu poniżej). Domyślnie na wykresie jest rysowany czas procesora, więc wskaźnik przełączeń kontekstu na sekundę trzeba sobie dorzucić. Efekt finalny jest taki (wyrzuciłem tutaj wskaźnik zajętości CPU):

Komputer w zasadzie nie był obciążony, miałem tylko otwarte parę stron w przeglądarkach (w tym przez jakiś czas wideo na YouTube i jeden PDF). Ponadto antywirus i trochę badziewia w zasobniku, ale sumarycznie obciążenie CPU to pojedyczne procenty.
Procesor to Core i5-4670, a więc 4-rdzeniowy (bez HT).
- ctxt_per_s.png (33 KB) - ściągnięć: 124
{kind=link}