Chciałbym to zrobić równolegle tylko problem pojawia się podczas współdzielenia transakcji.
Dlaczego równolegle? Co zyskujesz kosztem złożoności rozwiązania?
Poprawnie byłoby zbudować logikę, które obsługuje wykonanie Twojego workflow i mieć mechanizm, który jest w stanie wyszukać instancje workflow, które padły i wznowić ich wykonanie.
Zamiast
Kopiuj
activity1.execute();
activity2.execute();
coś w stylu
Kopiuj
MyBusinessProcess process = MyBusinessProcess(activity1,activity2);
process.execute();
Gdzie ten MyBusinessProcess zamyka maszyną stanową/workflowem, który jest w stanie "kontynuować wykonanie procesu zgodnie z logiką, której potrzebujesz" (trzeba to sobie oprogramować, można wykorzystać istniejące frameworki).
Kolejna sprawa, to piszesz, że równolegle... ale co z przeplotami wykonania? Piszesz o abstrakcyjnych tabelach A,B,C, ale gdyby C nie było w jakiś sposób związane z przetwarzaniem A,B to chyba problemu by nie było? Czy robi Ci różnicę kolejność w jakiej zadania rozpoczną pracę i w jakiej zakończą pracę i jaki będzie stan (zawartość) tabel A,B,C w określonym punkcie czasu?
np. możesz mieć takie przeploty (| - momenty rozpoczęcia/zakończenie zadania, - - wykonanie zadania)
Kopiuj
Task #1: |------------------------|
Task #2: |------------------------|
Task #1: |------------------------|
Task #2: |---------------------|
Task #1: |------------------------|
Task #2: |-------------------|
...
Przeplot#1 - Task#1 i #2 zaczynają i kończą się dokładnie w tym samym czasie (mało prawdopodobne ale mocno zależne od tego "jak i gdzie mierzymy czas")
Przeplot#2 - Task#1 zaczyna się wcześniej niż 2, ale kończą w tym samym momencie
Przeplot#3 - Task#2 zaczyna się później niż task#1, ale kończy wcześniej niż Task#1
...
"Dlaczego równolegle? Co zyskujesz kosztem złożoności rozwiązania? "
Tylko po to żeby przyspieszyć proces.
"(trzeba to sobie oprogramować, można wykorzystać istniejące frameworki). "
Masz jakieś fajne na myśli ? Mi z tego co kojarzę jest Spring Batch tylko nie wiem czy to nie jest armata do muchy.
"> Kolejna sprawa, to piszesz, że równolegle... ale co z przeplotami wykonania? Piszesz o abstrakcyjnych tabelach A,B,C, ale gdyby C nie było w jakiś sposób związane z przetwarzaniem A,B to chyba problemu by nie było? Czy robi Ci różnicę kolejność w jakiej zadania rozpoczną pracę i w jakiej zakończą pracę i jaki będzie stan (zawartość) tabel A,B,C w określonym punkcie czasu?"
C jako tako nie jest powiązane z A i B w sensie jeśli chodzi o kalkulacje czy coś natomiast nie może być takiej sytuacji że A i B się przekalkuluje a C wyskoczy gdzieś error i nie przekopiuje.
C również może się zacząć później i skończyć wcześniej nie ma to wpływu.
Przez to myślałem nad jakąś transakcją ale może dobrym pomysłem by było "ala proces" to ogarnąć.

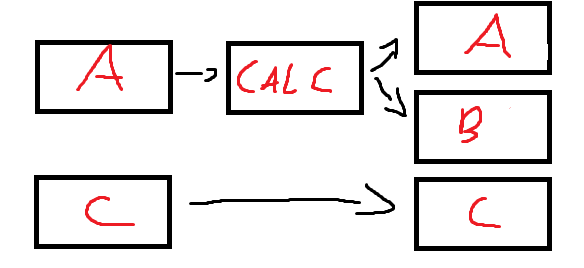
 Mamy 2 tabelki z danymi (A i B)
Mamy 2 tabelki z danymi (A i B)
