raczej:
class B{ B() { this.c = new C(); this.d = new D(); } }
class A{ A() { this.b = new B(); } }



raczej:
class B{ B() { this.c = new C(); this.d = new D(); } }
class A{ A() { this.b = new B(); } }

W życiu bym nie przypuszczał że tyle osób nie może uwierzyć że dependency injection można stosować ręcznie i zaśmiecanie kodu @Inject nie jest jedyną alternatywą dla umieszczania new w każdym konstruktorze.
http://di-in-scala.github.io/#manual

@caer: trzeba przyznać, że w Scali jest dużo łatwiej i kiedy piszę w Javie czasem mi brakuje lazy val,(i o zgrozo implicitów).
(Btw. zupełnie nie używam MacWire - nie widzę sensu - a Adam zawsze zgarnia ode mnie hejta za niego w jak się spotkamy :-) )
Ale nadal wolę napisać dwie trzy linijki więcej niż wprowadzać magię. (Przy czym jeszcze 13 lat temu w javie bez generyków - nie było wyjścia, magia dawała więcej korzyści niż szkód - od czasu jednak Java 8, kiedy można wreszcie normalnie np. "dekorować" - szala jest już zdecydowanie w druga stronę ).
Jak sobie poradzić z tymi zależnościami i testami już kiedyś zrobiłem historię na githubie:
https://github.com/javaFunAgain/magic_service_story/tree/70_CLEANING
(można branchami zacząć od początku:
https://github.com/javaFunAgain/magic_service_story/tree/10_BEGIN)

Shalom napisał(a):
Jakoś dziwnym trafem jedyne problemy z systemem po refaktoringu i z dopasowaniem testów widzę w systemach grubo korzystających z JavaEE lub Spring
@jarekr000000 nic w tym dziwnego, bo to są pewnie zwyczajnie duze systemy. W kodzie na 200 linijek w Haskellu tego problemu nie będzie, nie dlatego ze Haskell taki dobry tylko ze złożoność problemu mniejsza. Takie podejście że
wstrzykiwanie jest złejest równie krókowzroczne co podejścienew jest złe;)
Właśnie.
Zrobić refactoring w małym projekcie jest stosunkowo prosto.
Ale w projekcie składającym się z kilkudziesięciu bibliotek to już zabawa na 2 tygodnie.
Należy jednak mierzyć siły na zamiary.
Jeżeli robimy program z założenia mały, albo który nie będzie rozwijany i z danej klasy będzie korzystać tylko jeden programista, można pominąć interfacey.
W innym przypadku należy tworzyć interfacey.
Dzięki temu można zrównoleglić pracę - jeden programista robi implementację interfacu, a drugi już robi funkcjonalność korzystającą z tego interfacu.

Ja jestem tuż po wycince Google Guice'a z projektu i zastąpienia go zwykłym ręcznym DI. Zamiast tworzyć jakieś moduły, providery, pierdoły mam sobie klaskę typu:
package something.wiring
object ProductionModule {
private val dependency6 = new Dependency6()
private val dependency4 = new Dependency4()
private val dependency5 = new Dependency5(dependency6)
private val dependency1 = new Dependency1(dependency4, dependency5, dependency6)
private val dependency2 = new Dependency2(dependency4)
private val dependency3 = new Dependency3(dependency5)
val application = new Appilcation(dependency1, dependency2, dependency3)
}
Cały graf w jednym miejscu. Jak na razie graf w przerobianym przeze mnie mikroserwisie jest malutki, ale nawet jakby się rozrósł do dużych rozmiarów to można go ostatecznie podzielić na klasy względem semantyki, czyli np zrobić OrdersModule, UsersModule, etc Ale to jest ostateczność, bo jeśli graf powiązań jest zbyt duży jak na jedną klasę to prawdopodobnie oznacza to, że nie mamy już mikroserwisu, a coś co zdąża w stronę kobyły.
Brak kontenera DI oznacza łatwe i wygodne testowanie. Nie trzeba robić cudów typu tworzenie ekstra modułu i łączenia go z modułami produkcyjnymi za pomocą metod 'override' po to by nie duplikować całej masy boilerplate'u z modułów Guice'owych. W testach mam osobną hierarchię zależności w budowniczym. Np:
package tests.infrastructure.wiring
object ApplicationBuilder {
def build(parameter1: Boolean, parameter2: Type1, parameter3: Option[Type2]): Application = {
val dependency6 = new Dependency6Test()
val dependency5 = new Dependency5(dependency6)
val dependency1 = if (parameter1) new Dependency1VariantA(dependency5) else new Dependency1VariantB(new Dependency4())
val dependency2 = new Dependency2Test(parameter2, dependency6)
val dependency3 = new Dependency3Test(parameter3, dependency5)
new Application(dependency1, dependency2, dependency3)
}
}
To jest oczywiście do testów integracyjnych, bo dla jednostkowych nie trzeba składać całej aplikacji.
Rozwiązanie bez Guice jest czytelniejsze, zwięźlejsze i od razu widać co od czego zależy i od razu też widać czy graf zależności ma sens czy może jest skopany. Ta ostatnia cecha jest bardzo ważna, bo wrzucając adnotacje @Inject gdzie się da można zrobić tak katastrofalne hierarchie zależności, że ciężko jest potem prześledzić ich graf.
Jest prawie pełne DI, tzn konstruktory robią tylko i wyłącznie zapisywanie parametrów do prywatnych pól. Wyjątkiem są może jakieś pojedyncze aktory, które w celu inicjalizacji np wysyłają gdzieś tam wiadomość.
PS:
Nikt tu nie mówi o usunięciu wstrzykiwania. Ani ja, ani @jarekr000000. Kontener DI absolutnie nie jest potrzebny do wstrzykiwania. Kontenery DI jedyne co robią to magicznie składają graf powiązań. W ręcznym DI graf jest explicite, ale DI dalej jest. Różnica między DI, a brakiem DI jest naprawdę prosta i niezwiązana z żadną biblioteką.
Wersja klaski z brakiem DI:
class A {
private val dependency1 = new Dependency1()
private val dependency2 = new Dependency2()
private val dependency3 = new Dependency3()
// tu jakiś kod, który korzysta z powyższych zależności
}
Wersja klaski z ręcznym DI:
class A(dependency1: Dependency1, dependency2: Dependency2, dependency3: Dependency3) {
// tu jakiś kod, który korzysta z powyższych zależności
}
object A extends A(Dependency1, Dependency2, Dependency3) // globalny singleton z ustawionymi zależnościami
Globalny singleton to nie jest dobra sprawa, ale to tylko pokazowo. Lepszym rozwiązaniem jest stworzenie ProductionModule, który centralizuje graf zależności, tak jak podałem na początku posta.
PS2:
Niektórym wydaje się, że główną zaletą kontenera DI jest to, że nie musimy używać słówka new. No sorry, jeśli new tak bardzo was razi w oczy to możecie sobie zrobić alias na Class.newInstance, który nie ma słówka new. W DI chodzi o testowalność. W DI konstruktor nic nie robi, ma wszystko podane na tacy i po zapisie parametrów konstruktora w obiekcie (czyli te sławetne this.cośTam = cośTam) ten obiekt jest gotowy do działania. Dzięki temu mogę tworzyć dowolne ilości instancji takiej klasy i mam pewność, że konstruktor np nie zacznie dobijać się do bazy czy wysyłać emaili. Zależności oczywiście trzeba stworzyć słówkiem new albo refleksją czy innym badziewiem (albo podać nulla jeśli wiemy że w danym scenariuszu testowym dana zależność nie będzie używana), ale ważne żeby robić to poza konstruktorami. Tyle.
DI (zarówno ręczne jak i te przez kontener DI) zwiększa testowalność, gdyż w testach testujemy metody, a nie konstruktory. Nie mogę przetestować metody bez odpalania konstruktora, więc zależy mi na tym, by konstruktor robił jak najmniej. W DI konstruktor tylko przepisuje pola, a więc nic się nie może sypnąć i działa to bardzo szybko, w sam raz się więc nadaje do testów jednostkowych.
Wibowit napisał(a):
Niektórym wydaje się, że główną zaletą kontenera DI jest to, że nie musimy używać słówka
new. No sorry, jeślinewtak bardzo was razi w oczy to możecie sobie zrobić alias na Class.newInstance, który nie ma słówkanew. W DI chodzi o testowalność.
Nieprawda.
W DI chodzi o to, aby tworzyć obiekty nie znając ich klasy. A jedynie inteface.
W "Twoim ręcznym DI" to nie jest DI, tylko przekazywanie obiektów przez konstruktor.
Jak za taką pomocą stworzysz nowy obiekt zgodny z interfejsem "IMojInterfejs" ?
W DI po to opieramy się na kontenerze i tworzeniu za jego pomocą obiektów o danym interfejsie, aby móc skompilować bibliotekę i zmieniać klasy implementujące bez rekompilacji biblioteki.
Oraz bez żadnego refaktoringu biblioteki.
Dzięki temu możemy wykorzystać bibliotekę w wielu projektach, używających, "wstrzykujących" kompletnie odmienne implementacje.
Nieprawda.
W DI chodzi o to, aby tworzyć obiekty nie znając ich klasy. A jedynie inteface.
W "Twoim ręcznym DI" to nie jest DI, tylko przekazywanie obiektów przez konstruktor.
Jak za taką pomocą stworzysz nowy obiekt zgodny z interfejsem "IMojInterfejs" ?
Bajeczki. Tego w ogóle nie ma w definicji wstrzykiwania zależności.
Definicja wstrzykiwania zależności z polskiej Wikipedii:
Wstrzykiwanie zależności (ang. Dependency Injection, DI) – wzorzec projektowy i wzorzec architektury oprogramowania polegający na usuwaniu bezpośrednich zależności pomiędzy komponentami na rzecz architektury typu plug-in. Polega na przekazywaniu gotowych, utworzonych instancji obiektów udostępniających swoje metody i właściwości obiektom, które z nich korzystają (np. jako parametry konstruktora). Stanowi alternatywę do podejścia, gdzie obiekty tworzą instancję obiektów, z których korzystają np. we własnym konstruktorze.
Definicja z angielskiej:
In software engineering, dependency injection is a technique whereby one object supplies the dependencies of another object. A dependency is an object that can be used (a service). An injection is the passing of a dependency to a dependent object (a client) that would use it. The service is made part of the client's state.[1] Passing the service to the client, rather than allowing a client to build or find the service, is the fundamental requirement of the pattern.
This fundamental requirement means that using values (services) produced within the class from new or static methods is prohibited. The class should accept values passed in from outside.
Nigdzie nie ma mowy o jakichś interfejsach i implementacjach. To nie jest żaden wymóg. Nie jest to też niewykonalne w ręcznym DI. Mogę przecież zrobić:
trait JakiśIntefejs
class JakaśImplementacja extends JakiśInterfejs
class TworzonyObiekt(zależność: JakiśInterfejs) // tutaj, powiedzmy sobie, nie znam JakiejśImplementacji i operuję na JakimśInterfejsie
object ProductionModule {
private val tworzonyObiekt = new TworzonyObiekt(new JakaśImplementacja) // hej, TworzonyObiekt oczekiwał intefejsu, a podałem mu implementację, hurra
}
W powyższym przykładzie ProductionModule jest odpowiednikiem bindingów z kontenerów DI, bo przecież kontenerowi DI i tak trzeba powiedzieć jaką klasę wcisnąć w miejsce danego interfejsu.
Wibowit napisał(a):
Bajeczki. Tego w ogóle nie ma w definicji wstrzykiwania zależności.
Definicja wstrzykiwania zależności z polskiej Wikipedii:
A tu?:
Polega na przekazywaniu gotowych, utworzonych instancji obiektów udostępniających swoje metody i właściwości obiektom, które z nich korzystają (np. jako parametry konstruktora).
kontener DI właśnie tworzy obiekt i go przekazuje obiektom, które z nich korzystają.
Nie na konstruktorach się możliwości kończą.
Za pomocą DI da się utworzyć w metodzie np. listę miliona obiektów o danym interfejsie.
W "ręcznym DI" hmmm....możesz stworzyć fabrykę obiektów implementujących interface.
Ale przy zmianie klasy, musisz zmienić fabrykę.
Tak idąc do przodu dochodzimy do....własnego kontenera DI.
Po co to robić skoro już jest ? :)
Klasa nie musi implementować intefejsu, by udostępniać swoje metody i właściwości obiektom. Skąd ci to przyszło do głowy?
Nie na konstruktorach się możliwości kończą.
Za pomocą DI da się utworzyć w metodzie np. listę miliona obiektów o danym interfejsie.W "ręcznym DI" hmmm....możesz stworzyć fabrykę obiektów implementujących interface.
Ale przy zmianie klasy, musisz zmienić fabrykę.
Tak idąc do przodu dochodzimy do....własnego kontenera DI.
Po co to robić skoro już jest ? :)
W Google Guice za to muszę robić mutlibindy i przy zmianie klasy zmieniać wszystkie multibindy. Czyli roboty tyle samo, albo nawet więcej bo tych bindingów do Guice to trzeba szukać po całym projekcie.

@Robakowy, chyba brakuje Ci wiedzy na ten temat ale sie wypowiadasz. Jesli chcesz cwiczyc erystyke to proponuje dzial flame.
Polecam przeczytac w calosci:
https://en.m.wikipedia.org/wiki/Inversion_of_control

Tak idąc do przodu dochodzimy do....własnego kontenera DI.
Po co to robić skoro już jest ?
Ponieważ kontenery DI czasami dodają za dużo od siebie i masz problem. Przykładem mogą być AOPy ze springa, które w pewnych przypadkach działają zbyt magicznie.
W DI chodzi o to, aby tworzyć obiekty nie znając ich klasy. A jedynie inteface.
Duże uproszczenie. Kontener DI i tak musi mieć odpowiednią konfigurację wraz z definicjami co na co się mapuje.

@Koziołek nie zgodzę sie. Kontener musi finalnie wiedzieć co utworzyć, ale to nie znaczy ze trzeba pisać jakieś żmudne konfiguracje. Przykład z życia wzięty gdzie użycie kontenera IoC upraszcza sprawę i ułatwia życie:
Mamy system z którego można wystartować sobie różne pluginy. Jest zestaw pewnych pluginów do "inżynierii wstecznej" z których każdy działa wg dokładnie tej samej logiki, która jest objęta ładnym template method. Oczywiście ta logika ma pewne kroki uzależnione od konkretnego pluginu (bo inaczej reversuje sie kod X a inaczej kod Y). Moglibyśmy sobie w każdym z pluginów ręcznie towrzyć ten nasz "GenericReverseLogic" i wrzucać do niego np. konstruktorem obiekty odpowiedzialne za realizacje konkretnych kroków algorytmu. Tylko ze w takim razie w każdym pluginie powtarzalibyśmy dokładnie ten sam schemat z tworzeniem X obiektów i ustawianiem ich.
Alternatywnie możemy GenericReverseLogic oznaczyć jako jakiś @Named i analogicznie każdy z tych zależnych obiektów realizujących konkretne kroki i po prostu je wstrzykiwać. Zalety? Startujac plugin X kontener może automatycznie wykryć w classpath co należy utworzyć i poskłada nam to do kupy. Nie ma potrzeby pisać konfigurację wraz z definicjami co na co się mapuje., nie ma potrzeby powtarzać prawie identycznego kodu N razy (zmieniając tylko nazwy konkretnych klas).
Nie będę też juz wspominał o tym, ze przy okazji używamy kontenera też do wykrywania listy dostępnyc pluginów i do ich startowania ;] Nie potrzeba niczego ręcznie aktualizować kiedy dodajesz nowy plugin, bo zwyczajnie system przy uruchomieniu będzie widział wszystkie implementacje IPlugin.
@Wibowit ciekawi mnie jak chciałbyś podobne rzeczy zrobić bez użycia kontenera IoC i jednocześnie bez implementowania własnego bieda-IoC za pomocą jakiejś refleksji i czarnej magii / bez konieczości kopiowania identycznego kodu X razy.
@Shalom: ale ten efekt masz bez typowego kontenera DI, ale z użyciem SPI.
@Shalom ... jaka refleksja? przecież @Wibowit w Scali pisze i tam tej runtimowej biedy się coraz mniej używa.
Po drugie już kilka razy pisał jak to robi - w innym wątku. I nie ma tam żadnego bieda kontenera - nie potrzeba.
Bzdura. Sorry. Zapedziłem się - piszesz o pluginach. I Racja - jak bym miał runtimowe zależności użyłbym kontenera np. typu spring.
(W jednym projekcie używamy do tego OSGi, które jest nawet gorsze miejscami od Springa (classloader hell) - ale "pluginowość" załatwia).
A tekst na górze zostawiam - jako nauczkę dla siebie: czytaj posty Shaloma dokładnie nawet z rana.
konieczny. Zawsze można go zastąpić czymś innym.czyści, bez kontenera.
@Shalom:
Primo - rzadko kiedy pisze się programy, które mają wtyczki. Wtyczki to generalnie egzotyka, a w webówce to już w ogóle. Stąd przypadek jest mocno teoretyczny dla typowego programisty.
Secundo - najczęściej używanym przeze mnie programem, który używa wtyczek jest IntelliJ IDEA i ty też go chętnie używasz. IntelliJ jest też otwartoźródłowy, więc łatwiej będzie zajrzeć i stwierdzić jak coś rozwiązać. Wobec tego porozmawiajmy o nim, no chyba, że jest jakiś inny program do którego obaj mamy dostęp i nie musimy się domyślać jak działa, bo możemy odpalić i przejrzeć kod.
Mamy system z którego można wystartować sobie różne pluginy. Jest zestaw pewnych pluginów do "inżynierii wstecznej" z których każdy działa wg dokładnie tej samej logiki, która jest objęta ładnym template method. Oczywiście ta logika ma pewne kroki uzależnione od konkretnego pluginu (bo inaczej reversuje sie kod X a inaczej kod Y). Moglibyśmy sobie w każdym z pluginów ręcznie towrzyć ten nasz "GenericReverseLogic" i wrzucać do niego np. konstruktorem obiekty odpowiedzialne za realizacje konkretnych kroków algorytmu. Tylko ze w takim razie w każdym pluginie powtarzalibyśmy dokładnie ten sam schemat z tworzeniem X obiektów i ustawianiem ich.
Alternatywnie możemy GenericReverseLogic oznaczyć jako jakiś @named i analogicznie każdy z tych zależnych obiektów realizujących konkretne kroki i po prostu je wstrzykiwać.
Nie widzę specjalnie sensu w tym co piszesz. Wtyczka może mieć intefejs np:
class Wtyczka {
def działaj(intellij: IntelliJ): Unit
}
I tym sposobem mamy dostęp do wszystkiego co oferuje IDE. Jeśli bardzo chcemy to możemy sobie dopisać klaskę (fasadę), która ma tylko jeden parametr intellij i serię metod, które delegują do potrzebnych nam funkcjonalności.
Zalety? Startujac plugin X kontener może automatycznie wykryć w classpath co należy utworzyć i poskłada nam to do kupy. Nie ma potrzeby pisać konfigurację wraz z definicjami co na co się mapuje., nie ma potrzeby powtarzać prawie identycznego kodu N razy (zmieniając tylko nazwy konkretnych klas).
Generalnie to co potrzebujemy przy wtyczkach to znajdowanie JARów. Myślę, że taki IntelliJ taką mapkę JARów gdzieś musi mieć, bo:
Musi gdzieś być mapka zawierająca co najmniej: (nazwa jara) -> (status). Każdy JAR jest też ładowany w osobnym classloaderze, więc nie można sobie po prostu ustawić jako classpath całego folderu. Trzeba iterować po JARach explicite. Ładowanie w osobnych classloaderach pozwala korzystać wtyczkom z niekompatybilnych wersji bibliotek. Myślę, że to podstawowa sprawa - gdyby tak nie było to mielibyśmy classpath hell.
Mechanizm wtyczek w IntelliJu daje też możliwość rozszerzania funcjonalności jednej wtyczki przez drugą wtyczkę. Żeby to zrobić to (z tego co zrozumiałem z super szybkiej i bardzo pobieżnej analizy dokumentacji) to trzeba explicite podać z jakiej wtyczki się korzysta (a więc musi to być jakiś konkretny namiar, a nie coś automatycznie wstrzyknięte), a rozszerzana wtyczka musi mieć extension points.
Czy da się to zaimplementować za pomocą Google Guice? Pewnie się da, ale trzeba się nawyginać i zostajemy z masą niepotrzebnych hacków. Google Guice nie wygląda mi na bibliotekę stworzoną z myślą o implementowaniu mechanizmu wtyczek.
PS:
Poza tym wtyczka może chcieć się zainicjalizować. Jeśli wyszukamy ją automatycznie to nie będziemy wiedzieć gdzie są jej dane. Musimy gdzieś trzymać też mapkę: (nazwa jara) -> (dane wtyczki).
Musi gdzieś być mapka zawierająca co najmniej: (nazwa jara) -> (status). Każdy JAR jest też ładowany w osobnym classloaderze, więc nie można sobie po prostu ustawić jako classpath całego folderu. Trzeba iterować po JARach explicite. Ładowanie w osobnych classloaderach pozwala korzystać wtyczkom z niekompatybilnych wersji bibliotek. Myślę, że to podstawowa sprawa - gdyby tak nie było to mielibyśmy classpath hell.
Tak przy okazji z tymi osobnymi classloaderami też kłopot - mam przykład OSGi, który to jest piękny w teorii, każdy jar w osobnym CL, wyspecyfikowane jawne publiczne API. Niestety w praktyce zamienia się classpath hell na classloader hell.
(oczywiście niby tylko, gdy jakaś bilbioteka, której używamy brzydko się bawi z classloaderami. W praktyce zaskakująco dużo bibliotek to robi - > część zupełnie niepotrzebnie).
No dobra. Obrońcy kontenerów DI podajcie mi jakiś konkretny przykład, gdzie użycie jakiegoś kontenera DI da zauważalny zysk w dobrze zaprojektowanej aplikacji. Z moich doświadczeń wynika, że wycięcie Google Guice (a konkretnie to Scala Guice, które jest nawet zwięźlejsze) i zastąpienie go ręcznym DI przynosi wymierne zyski w postaci:
Dowód na wiarę o wyższości kontenerów DI nad ręcznym DI mnie nie przekonuje. Dodatkowo ZTCP taki Shalom popisał się nieznajomością DI pisząc, że bez kontenera DI będę musiał przepychać zależności w dół przez wiele poziomów. Hmm, gdzie? Przecież w DI zależności dostaję w konstruktorze i na tym koniec. Czekam więc na przykład, który rozjaśni sprawę. Ja podałem mnóstwo konkretnych przykładów, czyli kodu źródłowego.
Wibowit napisał(a):
No dobra. Obrońcy kontenerów DI podajcie mi jakiś konkretny przykład, gdzie użycie jakiegoś kontenera DI da zauważalny zysk w dobrze zaprojektowanej aplikacji. Z moich doświadczeń wynika, że wycięcie Google Guice (a konkretnie to Scala Guice, które jest nawet zwięźlejsze) i zastąpienie go ręcznym DI przynosi wymierne zyski w postaci:
- zmniejszonej ilości kodu i klas (np w testach mogę zrobić prostego ifa w logice budującej graf zależności zamiast żonglować modułami z bindingami),
- łatwiejszemu testowaniu,
- możliwości szybkiego przejrzenia wewnętrznych zależności między klasami, bo cały gotowy graf jest explicite w jednej klasie, a to daje:
- szybki pogląd na architekturę aplikacji,
- łatwość zauważenia popsutej hierarchii zależności - przy rozproszonym po kodzie grafie zależności nie widać od razu czy nie popełniliśmy gdzieś błędu wrzucając klasę w niewłaściwe miejsce w hierarchii,
Masz rację, że DI oprócz swoich korzyści daje też parę utrudnień.
Korzyści DI należy rozpatrywać w długim okresie.
Tworząc obiekty za pomocą DI rzeczywiście nie widzisz od ręki wszelkich zależności. Do tego celu musisz rzucić okiem na diagram encji.
Ale również dzięki temu, w wielu przypadkach nie musisz znać tych wszystkich zależności.
Traktujesz obiekt jak "black box" skupiając się na jego udostępnianej funkcjonalności, a nie na tym co jest w środku.
DI zbuduje graf zależności za Ciebie.
Przykład.
Robisz funkcjonalność wyświetlającą okno dialogowe np. do pobrania danych do logowania do bazy danych.
Instancja okna jest tworzona wewnątrz tej funkcjonalności.
Możesz na stałe wpisać w tą funkcjonalność klasę okna i tworzyć tylko to jedno okno cały czas.
Ale możesz też wykorzystać do tego celu DI i pozwolić użytkownikowi na stworzenie dowolnego, wybranego przez niego okna.
DI znacznie zwiększa możliwości wykorzystania tego samego kodu w wielu projektach.
Dowód na wiarę o wyższości kontenerów DI nad ręcznym DI mnie nie przekonuje. Dodatkowo ZTCP taki Shalom popisał się nieznajomością DI pisząc, że bez kontenera DI będę musiał przepychać zależności w dół przez wiele poziomów. Hmm, gdzie?
Shalom napisał prawdę.
Mając obiekt z 10 innymi obiektami w konstruktorze, a każdy z tych 10 obiektów ma 3 obiekty we własnym konstruktorze, musisz tworzyć 30 obiektów ręcznie.
W DI tworzysz tylko obiekt główny, a resztę utworzy za Ciebie kontener DI.
vpiotr napisał(a):
@Robakowy, chyba brakuje Ci wiedzy na ten temat ale sie wypowiadasz. Jesli chcesz cwiczyc erystyke to proponuje dzial flame.
Polecam przeczytac w calosci:
https://en.m.wikipedia.org/wiki/Inversion_of_control
Czy możesz przytoczyć swoje argumenty na poparcie swoich odczuć w powyższym zakresie ?
Masz rację, że DI oprócz swoich korzyści daje też parę utrudnień.
Korzyści DI należy rozpatrywać w długim okresie.
Tworząc obiekty za pomocą DI rzeczywiście nie widzisz od ręki wszelkich zależności. Do tego celu musisz rzucić okiem na diagram encji.
Ale również dzięki temu, w wielu przypadkach nie musisz znać tych wszystkich zależności.
Traktujesz obiekt jak "black box" skupiając się na jego udostępnianej funkcjonalności, a nie na tym co jest w środku.
DI zbuduje graf zależności za Ciebie.
Ciekawe kiedy dotrze do ciebie różnica między ręcznym DI, a refleksyjnym DI oraz między implementowaniem DI, a brakiem DI. Ja absolutnie nie chcę wyrzucać DI, bo bardzo go lubię i przydaje się do wielu rzeczy.
Shalom napisał prawdę.
Mając obiekt z 10 innymi obiektami w konstruktorze, a każdy z tych 10 obiektów ma 3 obiekty we własnym konstruktorze, musisz tworzyć 30 obiektów ręcznie.
W DI tworzysz tylko obiekt główny, a resztę utworzy za Ciebie kontener DI.
Kompletny przykład poproszę, wraz z bindingami.
Robakowy napisał(a):
vpiotr napisał(a):
@Robakowy, chyba brakuje Ci wiedzy na ten temat ale sie wypowiadasz. Jesli chcesz cwiczyc erystyke to proponuje dzial flame.
Polecam przeczytac w calosci:
https://en.m.wikipedia.org/wiki/Inversion_of_controlCzy możesz przytoczyć swoje argumenty na poparcie swoich odczuć w powyższym zakresie ?
Tak, mogę:
Robakowy napisał(a):
Niektórym wydaje się, że główną zaletą kontenera DI jest to, że nie musimy używać słówka
new. No sorry, jeślinewtak bardzo was razi w oczy to możecie sobie zrobić alias na Class.newInstance, który nie ma słówkanew. W DI chodzi o testowalność.
(tu miałem coś napisać obraźliwego ale się powstrzymałem)
W DI chodzi także o to żebyś nie wywoływał konstruktora bo możesz nie mieć wiedzy o tym jak to zrobić, albo ktoś może chcieć to od dzisiaj robić inaczej - w jednym miejscu a nie w 30.
Nieprawda.
W DI chodzi o to, aby tworzyć obiekty nie znając ich klasy. A jedynie inteface.
Nie. Chodzi o to żeby w ogóle nie tworzyć obiektu po stronie klasy-klienta. Bo jak to zrobić może zależeć od wywołującego.
W "Twoim ręcznym DI" to nie jest DI, tylko przekazywanie obiektów przez konstruktor.
Przeczytaj Wiki.
Jak za taką pomocą stworzysz nowy obiekt zgodny z interfejsem "IMojInterfejs" ?
Tak:
IMojInterfejs mojObiekt = new IMojInterfejs() {
@Override
public void jakasMetoda() {
}
};
// ... przekaż (wstrzyknij) gdzies mojObiekt
mojKlient.setMojObiekt(mojObiekt);

Odnośnie Dependency Injection to w świecie .net mam fajny wykresik, obrazujący tradeoffs (zależności) pomiędzy ręcznym wstrzykiwaniem, a używaniem kontenera, może pomoże wam w dyskusji :)
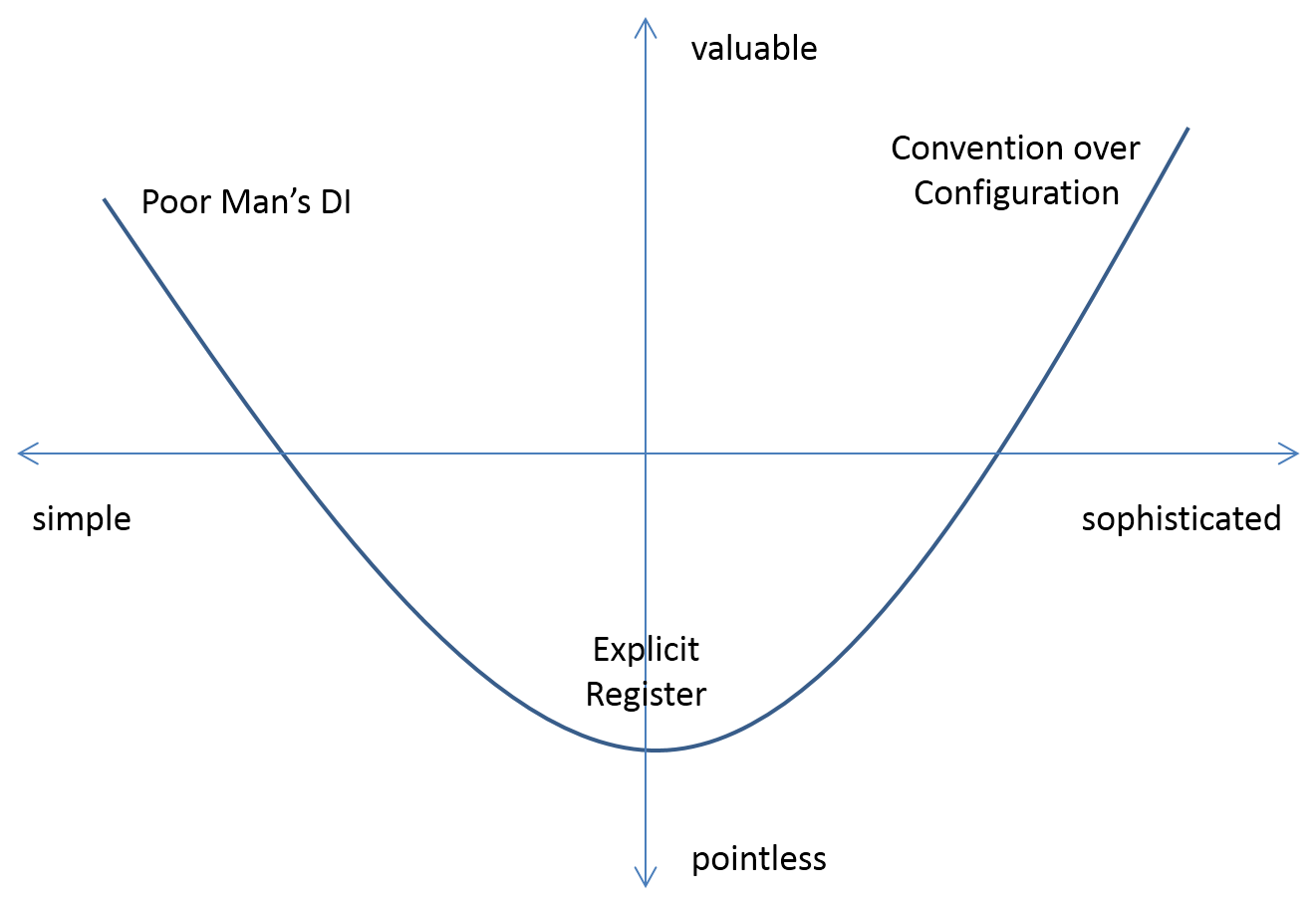
obrazek pochodzi z tekstu When to use a DI Container by Mark Seemann
Nawet się z tekstem zgadzam -tylko mam inne doświadczenia.
Wolę Poor Man's DI dokładnie z tych samych powodów, dla których wolę Javę od JavaScriptu. "Stringly typed" jest skuteczne w średnim okresie, ale w końcu się odbija czkawką.
vpiotr napisał(a):
W DI chodzi także o to żebyś nie wywoływał konstruktora bo możesz nie mieć wiedzy o tym jak to zrobić, albo ktoś może chcieć to od dzisiaj robić inaczej - w jednym miejscu a nie w 30.
sorry @vpiotr ale nie rozumiesz czym jest wstrzykiwanie
konstruktor wlasnie jest po to zebys nie mial mozliwosci zepsucia obiektu przez jego czesciowe utworzenie, przez settery jak najbardziej mozesz taki obiekt zepsuc, jak mozna nie wiedziec jak utworzyc obiekt z uzyciem konstruktora, po to wałasnie jest konstruktor zebys wiedział dokladnie jak go utworzyc.
i kolejna sprawa pojecia construktor injection a field/setter injection nadal podchodza pod DI jak najbardziej, wiec nie pisz ze w DI chodzi o nie wywoływanie konstruktora.
wstrzykiwanie przez konstruktor to tak samo DI gdzie normalnie wywołujesz konstruktor i nie musisz do tego uzywac frameworku. Tutaj nikt sie nie kłóci ze DI jest do d**y, dependency lookup jest niefajne ale DI ?
a to czy uzyjesz kontenera ktory sam zlozy za ciebie zaleznosci i wywoła za ciebie konstruktor to inna bajka, jedni lubia sami to zorbic inni przez springa/guica
kila stron o DI, a wyszło od tego czy tworzyc zawsze Interface'y :)