Na początek złożoność maszyny stanów. Jeżeli masz 30 możliwych stanów i 400 możliwych przejść pomiędzy tymi stanami, wynika to z wymagań biznesowych, to tak czy inaczej jakoś tę złożoność musisz zakodować. Możesz to zrobić albo za pomocą 30 klas reprezentujących stany, w których znajdzie się łącznie 400 metod, albo pojedynczej klasy reprezentującej stateful object (np. ten wniosek urlopowy), 30 wartości enuma + 400 definicji [initial state, event, result state]. Kodu mniej - więcej tyle samo.
Absolutnie nie.
400 metod będzie w jednej klasie zamiast w 30 (ergo klasa będzie miała pewnie tysiące linii kodu), różnica będzie taka, że zamiast zwracać obiekt stanu, będą zwracały void i ustawiały stan wewnętrzny obiektu.
Do tego każda z tych metod będzie musiała najpierw sprawdzić, czy będzie mogła być wywołana w danym stanie obiektu. Nawet jeśli to będzie tylko jeden if, to będzie to 400 zbędnych ifów.
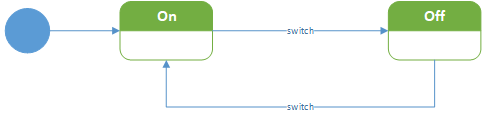
Maksymalnie prosty diagram stanów jakiegoś wyłącznika:
Już pisałem, przy prostych sytuacjach, to nie ma znaczenia - za to rozrasta się kosmicznie w miarę przybywania stanów.
Na warstwie persystencji też nie jest łatwo, bo zakładając tabela na klasę, musisz przeszukać 2 tabele zamiast jednej.
Po pierwsze nie muszę mieć żadnych tabel, po drugie bez problemu mogę trzymać dane w jednej tabeli.
Jeśli kotlinowe ormy są tak upośledzone, że nie potrafią mapować, to trzeba wybrać inny język.
Wady tego rozwiązania, to moim zdaniem:
Konieczność sprawdzania typu obiektu i w zależności od wyniku wywoływanie jakiejś metody.
Odczytywanie stanu (np. złożony, zatwierdzony, anulowany) z typu obiektu. Albo będzie tu jakaś metoda stateName():String, albo maper jadący po refleksji.
Wystarczy wczytać stan z bazy, i utworzyć obiekt reprezentujący konkretny stan za pomocą metody z danej klasy.
Cała definicja FSM musi być w kodzie, a wiadomo, że w przypadku procesu biznesowego będzie się zmieniać. Biznes albo zatrudni jakąś nową Anetkę w HR i trzeba będzie wprowadzić nowy stan, żeby miała co robić, albo chociaż zmieni nazwę jakiegoś stanu, żeby sprawiać wrażenie progresu. Przy mapowaniu procesu biznesowego na FSM idealnie by było wyciągnąć FSM z kodu do konfiguracji aplikacji.
No będzie, albo nie będzie. Jeśli zakładasz, że będzie, to w ogóle trzeba użyć jakiegoś istniejącego rozwiązania do workflowów, a nie bawić się samemu.
O budowie własnego frameworka do workflowów nie było póki co mowy w wątku.
Cała definicja diagramu stanów jest w jednym, no może 3 miejscach (lista stanów, lista zdarzeń, lista dopuszczalnych tranzycji)
No i masz ogromną konfigurację gdzieś tam, a jak patrzysz w kod klasy, to nie wiesz, co po czym może nastąpić.
Idea jest taka, że na każdym stanie możesz wykonać każdą akcję. Zwyczajnie tam gdzie jest ona nielegalna nic się nie stanie.
Tylko, żeby nic się nie stało, najpierw trzeba włożyć wysiłek w zaimplementowanie walidacji stanu, i zabezpieczenie przed tym, żeby aplikacja się wywaliła.
To, że nic się nie stanie, nie jest za darmo.
Bo pobierając wniosek o zadanym id nie wiesz w jakim on jest stanie.
Oczywiście, że wiem, przecież to jest zapisane w bazie.
No prosty use case - manager wyświetla sobie listę wszystkich wniosków podległych mu pracowników. Te wnioski są w różnych stanach. Część jest złożonych, część zatwierdzonych itd. Klika jakiś wniosek do zatwierdzenia. Pobieranie jeszcze raz tego wniosku z bazy, ale tym razem jako klasę specyficzną dla jego stanu jest moim zdaniem mocno bez sensu.
W czym problem?
Klasa modelu służącego do wyświetlenia danych w liście dla managera, będzie miała wyliczane na podstawie stanu propertisy czy tam metody typu: CanBeCanceled, CanBeApproved, itd.
Po stronie kodu można ten mechanizm implementować rozmaicie. Jednym ze sposobów jest użycie różnych (pod)typów dla rozróżnienia stanu. Jeżeli stan jest przechowywany w programie jako typ obiektu, to żeby go odczytać, trzeba odczytać ten typ.
Tutaj wchodzą moje fobie z Java. Niektóre inne języki mają to rozwiązane lepiej, ale w Java taki kod:
Kopiuj
PrivateType object = findObject(.....)
if(object instance of WniosekDoZatwierdzenia){
WniosekDoZatwierdzenia wniosek = (WniosekDoZatwierdzenia) object;
wniosek.zatwierdz();
}
Podpali kompilator w linii z rzutowaniem i zacznie latać uchnecked cast warning. Może nie tragedia, ale nie lubię.
Z całym szacunkiem, ale ten kod, to jakieś badziewie jest.
Jedynym momentem, w którym trzeba sprawdzać typ obiektu jest moment zapisu - żeby wiedzieć jak ustawić w rekordzie/dokumencie bazodanowym wartość stanu dokumentu.
Po wczytaniu z warstwy danych obiekt ma te metody, które ma, i innych nie można na nim wywołać. Kompilator jest szczęśliwy (i programista też).
Załóżmy, że chcesz dodać menu kontekstowe z możliwymi akcjami. W jaki sposób to zrobisz? Refleksja i sprawdzanie czy jakaś metoda istnieje? Można, ale sporo energii psu w d....ę.
Ale co ma menu kontekstowe do logiki przepływu? Obiekty w menu kontekstowym, to nie są obiekty logiki biznesowej.
Z drugiej strony linijka testu wywołująca tę walidację rozwiązuje problem runtime, czyli nie jest tak tragicznie.
Jest tragicznie, bo rośnie niemalże wykładniczo, i po jakimś czasie nikt z godnością nie chce takiego badziewia utrzymywać.









{kind=link}
{kind=link}
{kind=link}
Pobieranie jeszcze raz tego wniosku z bazy, ale tym razem jako klasę specyficzną dla jego stanu jest moim zdaniem mocno bez sensu.. Bo to zabrzmiało jakby oddzielny model do wyświetlenia i oddzielny model do zapisu był czymś bez sensu, a to przecież standard w aplikacjach z bardziej skomplikowaną domeną.