Witam serdecznie,
przeprowadzam testy wydajności różnych algorytmów uczenia dla sieci Hopfielda. Sieć ma służyć rozpoznawaniu prostych znaków.
Zaimplementowałem już 2 metody uczenia:
Hebba, orraz pseudoinwersję,
ale mam problem: nie potrafię zaimplementować metody Oji.
Głównie dlatego, że wartości wag na początku są zerowe, więc jak mam policzyć czynnik y?
Bazuję na opisie np. tutaj:
http://wiki.eyewire.org/en/Oja%27s_rule
Czy ktoś jest w stanie mi to wyjaśnić bądź napisać pseudokod jak to ma działać?
Z góry dziękuję za jakiekolwiek wskazówki.
- Rejestracja:ponad 10 lat
- Ostatnio:8 miesięcy
- Postów:14
0
- Rejestracja:około 12 lat
- Ostatnio:około 3 lata
0
Avarentis napisał(a):
Głównie dlatego, że wartości wag na początku są zerowe, więc jak mam policzyć czynnik y?
Bazuję na opisie np. tutaj:
http://wiki.eyewire.org/en/Oja%27s_rule.
Dlaczego wagi masz na początku zerowe? Wagi dla wejść neuronu linearnego nie są zerowe.
Zakładając, że wejścia tego neuronu możesz zawrzeć w wektorze X = [x1, x2, ..., xk] i wag każdego z tych wejść W = [w1, w2, ..., wk], to poniższa formuła...

...daje w wyniku odpowiedź neuronu (na aksonie) jako sumę informacji ze wszystkich wejść X o wagach W. Nigdy, w żadnym neuronie, dla wszystkich wejść, wagi nie mogą się równać 0, bo neuron by umarł. Nawet jeżeli dla części wejść określisz wagę na 0, a nie zapewnisz modyfikacji wag tych wejść na przykład poprzez sprzężenie zwrotne, to wejścia te również zginą. Chociaż jedno z wejść musi posiadać wagę większą od zera, a reszta wejść musi mieć wagi modyfikowalne. Inaczej ich istnienie mija się z celem.
PS poza tym sam widzisz po wzorze na zmianę wagi...

Oja's rule is simply Hebb's rule with weight normalization, approximated by a Taylor series with terms of Oja2.png ignored for n>1 since η is small.
...że wszystkie wagi nie mogą być zerowe, bo w takiej sytuacji ich byt nie ma sensu. Jak ma zmienić się waga danego wejścia (poprzez przepływ informacji), skoro informacja na wszystkich wejściach ma wagę równą 0? :)
- xxx.png (1 KB) - ściągnięć: 143
- CodeCogsEqn.png (1 KB) - ściągnięć: 188
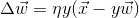{kind=link}
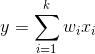{kind=link}
edytowany 2x, ostatnio: Gjorni
- Rejestracja:ponad 10 lat
- Ostatnio:8 miesięcy
- Postów:14
0
Wybacz, że tak późno, ale dopiero do tego wróciłem.
Hmm... wymyśliłem sobie więc coś takiego:
Ustalam pierwotne wagi metodą Hebba, a potem koryguję je Oji'm. Niestety otrzymuję teraz puste wyniki, jak analiza wzorca. Powód: niektóre wartości macierzy wag są tak niskie, że wchodzą w NaN...
Wiesz może co tutaj robię źle:
def matrix_preparation(input_patterns):
n = len(input_patterns)
num_neurons = len(input_patterns[0])
weights = np.zeros((num_neurons, num_neurons))
for i in range(num_neurons):
for j in range(num_neurons):
# if i == j:
# continue
for m in range(n):
weights[i, j] += input_patterns[m][i] * input_patterns[m][j]
weights /= n
return weights
def oja_training(network, input_patterns):
"""Ucz sieć metodą Oja"""
u = 0.8 # współczynnik prędkości uczenia
n = len(input_patterns)
num_neurons = network.get_weights().shape[0]
weights = matrix_preparation(input_patterns)
for i in range(num_neurons): # i do kogo wchodzi
for j in range(num_neurons): # j od kogo wychodzi
if i == j:
continue
for pattern in input_patterns:
V = 0.0
for k, signal in enumerate(pattern):
V += signal * weights[i, k]
weights[i, j] += u * V * (pattern[i] - V * weights[i, j])
A = [0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 0, 0,
0, 1, 1, 0, 1, 1, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 1, 1, 1, 1, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 1, 0,
1, 1, 0, 0, 0, 1, 1]
B = [0, 1, 1, 1, 1, 0, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 1, 1, 1, 0, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 1, 1, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0]
T = [1, 1, 1, 1, 1, 1, 1,
1, 0, 0, 1, 0, 0, 1,
0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0,
0, 0, 1, 1, 1, 0, 0]
O = [0, 0, 1, 1, 1, 0, 0,
0, 1, 0, 0, 0, 1, 0,
1, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 1,
0, 1, 0, 0, 0, 1, 0,
0, 0, 1, 1, 1, 0, 0]
M = [1, 0, 0, 0, 0, 0, 1,
1, 1, 0, 0, 0, 1, 1,
1, 0, 1, 0, 1, 0, 1,
1, 0, 0, 1, 0, 0, 1,
1, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 1]
U = [0, 1, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 1, 0,
0, 0, 1, 1, 1, 0, 0]
X = [1, 1, 0, 0, 0, 1, 1,
0, 1, 0, 0, 0, 1, 0,
0, 0, 1, 0, 1, 0, 0,
0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0,
0, 0, 1, 0, 1, 0, 0,
0, 1, 0, 0, 0, 1, 0,
1, 1, 0, 0, 0, 1, 1]
def konwert(mac):
for i in range(len(mac)):
mac[i] = mac[i] * 2 - 1
return mac
wzorce = list()
wzorce.append(konwert(A))
wzorce.append(konwert(B))
wzorce.append(konwert(O))
wzorce.append(konwert(T))
wzorce.append(konwert(M))
wzorce.append(konwert(U))
wzorce.append(konwert(X))
edytowany 2x, ostatnio: Avarentis
oja_trainingw parametrzenetwork? Bo jak zakładam, podinput_patternspodstawiaszwzorce?