
Plz polećcie dobre GPU nvidii do 2000 z przeznaczeniem do machine learningu
- Rejestracja:ponad 8 lat
- Ostatnio:około 4 lata
- Postów:146
1
Do jakiegokolwiek modern deep learningu minimum to bedzie 1080ti albo rtx 2080 (podobno tensorflow 2.0 smiga juz na amd ale na amdkach sie nie znam wiec nic nie polece)

rtx 2080 to jest sporo ponad 2000.

- Rejestracja:około 20 lat
- Ostatnio:około 5 godzin
1
Według tabelki RTX 2060 Super to praktycznie to samo co RTX 2070: https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units#GeForce_20_series
- Rejestracja:około 20 lat
- Ostatnio:około 5 godzin
1
Nie znam się na programach do uczenia maszynowego, ale karty GeForce RTX 20x0 różnią się przede wszystkim liczbą elementów obliczeniowych i ilością pamięci. Liczba elementów obliczeniowych wpływa na wydajność, ale raczej nie blokuje uruchamiania (no chyba, że coś tam wymaga obliczeń na żywo bez opóźnień i tylko odpowiednio silne karty sobie radzą). Ilość pamięci już prędzej może być problemem. RTX 2060 ma 6 GiB VRAMu, RTX 2060 Super aż do RTX 2080 Super mają 8 GiB VRAMu. RTX 2080 Ti ma 11 GiB pamięci. Myślę, że najrozsądniejszą opcją jest wybranie RTX 2060 Super - to najtańsza karta z Tensor cores mająca 8 GiB VRAMu.

- Rejestracja:około 8 lat
- Ostatnio:11 miesięcy
- Postów:74
1
Rozważ https://cloud.google.com/tpu/
Może osiągniesz swoje cele bez zawalania mieszkania krzemem.
Może wyjść nawet taniej, wszystko zależy od tego ile tego trenowania.
W wersji próbnej masz 300 $ do wydania.
Jak Ci się skończy użyj wersji Preemptible wtedy o połowę taniej.
edytowany 2x, ostatnio: Michał Kuliński
- Rejestracja:ponad 8 lat
- Ostatnio:około 4 lata
- Postów:146
1
Michał Kuliński napisał(a):
Rozważ https://cloud.google.com/tpu/
Może osiągniesz swoje cele bez zawalania mieszkania krzemem.
Może wyjść nawet taniej, wszystko zależy od tego ile tego trenowania.W wersji próbnej masz 300 $ do wydania.
Jak Ci się skończy użyj wersji Preemptible wtedy o połowę taniej.
Tworzenie modeli na TPU rozni sie od GPU i nie da sie testowac tych modeli lokalnie (ogolnie nic nie przetestujesz za free bo colab tpu nie dziala na nowym tensorflow)
@Edit -> od paru dni TPU juz dziala na colabie wiec cofam to co mowilem :P
edytowany 2x, ostatnio: komuher
Jak nie kijem go, to pałką:https://www.google.com/search?source=android-browser&ei=8WUnXtPNJsiSkwXR5oT4Bw&q=tensorflow+2.0.0+google+cloud&oq=tensorflow+2.0.0+google+cloid&gs_l=mobile-gws-wiz-serp.1.0.33i160.9175.24750..26279...4.1..0.1118.8168.0j2j12j4j2j1j1j1......0....1.........0i71j0j0i19j0i22i30j0i22i30i19j33i21j33i22i29i30.Mr7B7E_QaNE

- Rejestracja:około 6 lat
- Ostatnio:dzień
- Postów:160
0
Pytanie skierowanie głównie do @szweszwe i @Patryk27 . Odpowiedzieć może każdy.
Chodzi o dyskusję z komentarzy kilka postów wyżej:
@szweszwe: 2070. rozpoczyna w markdownie listę numerowaną, mającą nieco odmienne formatowanie od standardowego tekstu, która rozjeżdża się przy zbyt dużych liczbach
Nie wiedziałem o co chodzi. Mam zasadę, by o techniczne rzeczy pytać na forum w ostateczności, więc sprawdziłem w googlach wszystkie kombinacji z poniższych:
"gpu" "markdown"
"gpu" "numbered list"
"nlp" "markdown"
"nlp" "numbered list"
"deep learning" "markdown"
"deep learning" "numbered list"
Dla każdego zapytania sprawdziłem wszystkie rezultaty z pierwszej strony.
Niestety nie znalazłem nic, co wiązałoby listę numerowaną w markdownie z gpu computingiem.
Mógłby ktoś z Was powiedzieć o co chodzi?
Chodzi o https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet i dotyczy liczby 2070 nie gpu :P
2070. Lol, a ja myślałem, że chodzi o kartę RTX2070 i że "rozjeżdzają się" na niej wartości :) i że to jakaś "wada fabryczna", skoro post dotyczył tylko jej.

- Rejestracja:około 6 lat
- Ostatnio:dzień
- Postów:160
0
komuher napisał:
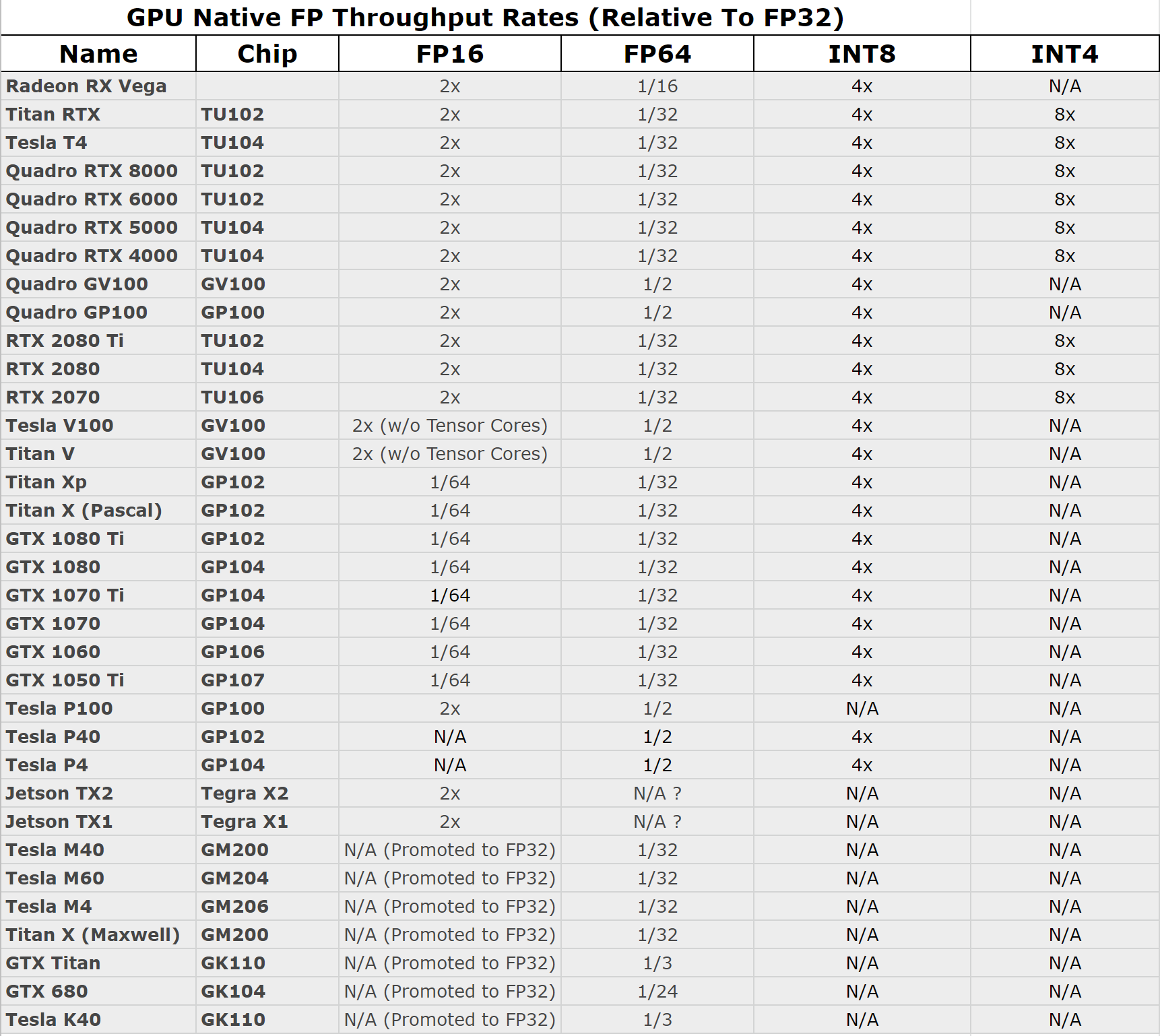
Do jakiegokolwiek modern deep learningu minimum to bedzie 1080ti albo rtx 2080 (podobno tensorflow 2.0 smiga juz na amd ale na amdkach sie nie znam wiec nic nie polece)
Znalazłem coś takiego.
Wynika z tego, że 1080ti nie obsługuje FP16. Zatem jeśli ktoś "boi się o awaryjne sytuacje, gdzie trzeba będzie więcej VRAMu", to lepszym wyborem zdają się być 8-gigowe turingi, niż 11-gigowe 1080ti.
{kind=link}
Zarejestruj się i dołącz do największej społeczności programistów w Polsce.
Otrzymaj wsparcie, dziel się wiedzą i rozwijaj swoje umiejętności z najlepszymi.
2070.rozpoczyna w markdownie listę numerowaną, mającą nieco odmienne formatowanie od standardowego tekstu, która rozjeżdża się przy zbyt dużych liczbach