Cześć,
Mam problem z programem "Hello world" rozdział trzeci z książki Gynvaela.
Wyskakuje mi błąd jak w załączniku.
Ktoś może wie o co chodzi?

Cześć,
Mam problem z programem "Hello world" rozdział trzeci z książki Gynvaela.
Wyskakuje mi błąd jak w załączniku.
Ktoś może wie o co chodzi?

Mam książkę na półce w domu, więc mogę zajrzeć wieczorem. Chyba, że wrzucisz kod.

@Haskell:
Tutaj masz kod: https://github.com/gynvael/zrozumiec-programowanie/blob/master/007-Czesc_II-Rozdzial_3-Podstawy_architektury_komputerowe/vm.py
To jest jakiś error @Gynvael Coldwinda

@Fausto: Podrzuć plz swój kod + kod VM (ten który @szweszwe wrzucił używasz?).
Ew. można też rzucić okiem na erratę - https://zrozumiecprogramowanie.pl/#/erratumPage - a nuż to coś z tego.
@Gynvael Coldwind:
Kody tylko z Twojego Github nic swojego. Chodziło o przetestowanie przykładu "hello world" z książki. Wieczorem sprawdzę erratę.
Edit.
Niestety nic nie znalazłem, nadal to samo.
Może chodzi o to, że @Fausto wywołał python vm.py z plikiem .nasm!
A to nie chodziło właśnie o wywołanie tego hello.nasm ?
Nie, na maszynie wirtualnej uruchamia się kod bajtowy (bytecode). Żeby takowy uzyskać trzeba skompilować plik z pseudoasemblerem za pomocą nasma (tak jak pokazałem w swoim poprzednim poście).
Cytując książkę:



Podepnę się do wątku może mi wybaczycie, chodzi konkretnie o fragment wyniku w formie heksadecymalnej:
000010 02 04 20 02 00 21 09 00
konkretnie: 21 09 00
i makro:
%macro vjz 1
db 0x21
dw (%1 - ($ + 2))
%endmacro
rozumie że db emituje bajt numeru instrukcji 21
nie rozumie tej drugiej linijki a dokładnie zapisu:
(%1 - ($ + 2))
co odejmowane jest od przekazanego przez nas argumentu ? Skąd wzięła się wyemitowana 16bitowa wartość: 09 00
addjar1701 napisał(a):
Podepnę się do wątku może mi wybaczycie, chodzi konkretnie o fragment wyniku w formie heksadecymalnej:
000010 02 04 20 02 00 21 09 00konkretnie: 21 09 00
i makro:%macro vjz 1 db 0x21 dw (%1 - ($ + 2)) %endmacrorozumie że db emituje bajt numeru instrukcji 21
nie rozumie tej drugiej linijki a dokładnie zapisu:
(%1 - ($ + 2))
co odejmowane jest od przekazanego przez nas argumentu ? Skąd wzięła się wyemitowana 16bitowa wartość: 09 00
W równaniu, o które pytasz, są dwie ciekawe rzeczy:
Generalnie nasm (jak i sporo innych assemblerów) działa w ten sposób, że on po prostu emituje strumień bajtów, i każda instrukcja bądź dyrektywa mówi "wyemituj kolejne kilka bajtów w ten sposób". Co za tym idzie każda dyrektywa wie jak daleko (w bajtach) od początku kodu jest. A żeby się dostać do tej informacji, trzeba własnie użyć $.
Czyli, to równanie (dość typowe do skoków relatywnych) można przełożyć na:
dw (adres_docelowy_skoku - (adres_tych_bajtów_które_teraz_wygeneruje_to_dw - wielkość_tej_instrukcji_czyli_dw_czyli_2_bajty))
Samo dw oczywiście powoduje wyemitowanie 16-bitowej wartości (data word, gdzie word w tym kontekście oznacza 16-bitów little endian).
Celem tego równania jest wyliczenie ile bajtów trzeba dodać do licznika instrukcji żeby wykonać skok licząc od NASTĘPNEJ instrukcji (stąd to +2 tam).
Przykład:
[org 0] ; zaczynamy liczyć od 0 (co jest domyślne)
vnop ; instrukcja na adresie 0
vnop ; instrukcja na adresie 1
vjnz xyz ; instrukcja na adresie 2
vnop ; instrukcja na adresie 5 (bo ta poprzednia ma 3 bajty)
xyz: ; etykieta równa adresowi 6
vnop ; instrukcja na adresie 6
W tym przypadku dla vjnz naszym %1 jest 6, a naszym $ jest 3 (czemu 3 a nie 2? bo przed dw w makrze jest jeszcze db, które sprawia, że samo dw będzie o bajt dalej).
Jak zaczniemy liczyć wychodzi nam (6 - (3 + 2)), czyli po prostu 1. A więc możemy to interpretować jako "przeskocz jeden bajt".
I patrząc na kod faktycznie tak jest, przeskakujemy tym skokiem jeden vnop (zakładając ofc że ten skok by się wykonał).
Ostateczny bajtkod tego vjnz tam to byłby: 21 01 00
Gynvael Coldwind napisał(a):
addjar1701 napisał(a):
Podepnę się do wątku może mi wybaczycie, chodzi konkretnie o fragment wyniku w formie heksadecymalnej:
000010 02 04 20 02 00 21 09 00konkretnie: 21 09 00
i makro:%macro vjz 1 db 0x21 dw (%1 - ($ + 2)) %endmacrorozumie że db emituje bajt numeru instrukcji 21
nie rozumie tej drugiej linijki a dokładnie zapisu:
(%1 - ($ + 2))
co odejmowane jest od przekazanego przez nas argumentu ? Skąd wzięła się wyemitowana 16bitowa wartość: 09 00W równaniu, o które pytasz, są dwie ciekawe rzeczy:
- Przekazany argument %1. Do tego skoku przekazuje się zazwyczaj "label", czyli oznaczenie miejsca, do którego skok ma się odbyć. Czyli de facto adres w pamięci (co czasem jest tożsame z offsetem w pliku).
- Oraz $, czyli adres w pamięci tej konkretnej przetwarzanej instrukcji/dyrektywy (tj. dw).
Generalnie nasm (jak i sporo innych assemblerów) działa w ten sposób, że on po prostu emituje strumień bajtów, i każda instrukcja bądź dyrektywa mówi "wyemituj kolejne kilka bajtów w ten sposób". Co za tym idzie każda dyrektywa wie jak daleko (w bajtach) od początku kodu jest. A żeby się dostać do tej informacji, trzeba własnie użyć $.
Czyli, to równanie (dość typowe do skoków relatywnych) można przełożyć na:
dw (adres_docelowy_skoku - (adres_tych_bajtów_które_teraz_wygeneruje_to_dw - wielkość_tej_instrukcji_czyli_dw_czyli_2_bajty))Samo dw oczywiście powoduje wyemitowanie 16-bitowej wartości (data word, gdzie word w tym kontekście oznacza 16-bitów little endian).
Celem tego równania jest wyliczenie ile bajtów trzeba dodać do licznika instrukcji żeby wykonać skok licząc od NASTĘPNEJ instrukcji (stąd to +2 tam).
Przykład:
[org 0] ; zaczynamy liczyć od 0 (co jest domyślne) vnop ; instrukcja na adresie 0 vnop ; instrukcja na adresie 1 vjnz xyz ; instrukcja na adresie 2 vnop ; instrukcja na adresie 5 (bo ta poprzednia ma 3 bajty) xyz: ; etykieta równa adresowi 6 vnop ; instrukcja na adresie 6W tym przypadku dla vjnz naszym %1 jest 6, a naszym $ jest 3 (czemu 3 a nie 2? bo przed dw w makrze jest jeszcze db, które sprawia, że samo dw będzie o bajt dalej).
Jak zaczniemy liczyć wychodzi nam (6 - (3 + 2)), czyli po prostu 1. A więc możemy to interpretować jako "przeskocz jeden bajt".
I patrząc na kod faktycznie tak jest, przeskakujemy tym skokiem jeden vnop (zakładając ofc że ten skok by się wykonał).Ostateczny bajtkod tego vjnz tam to byłby: 21 01 00
Dziękuję ślicznie za bardzo przystępne i obszerne wyjaśnienie 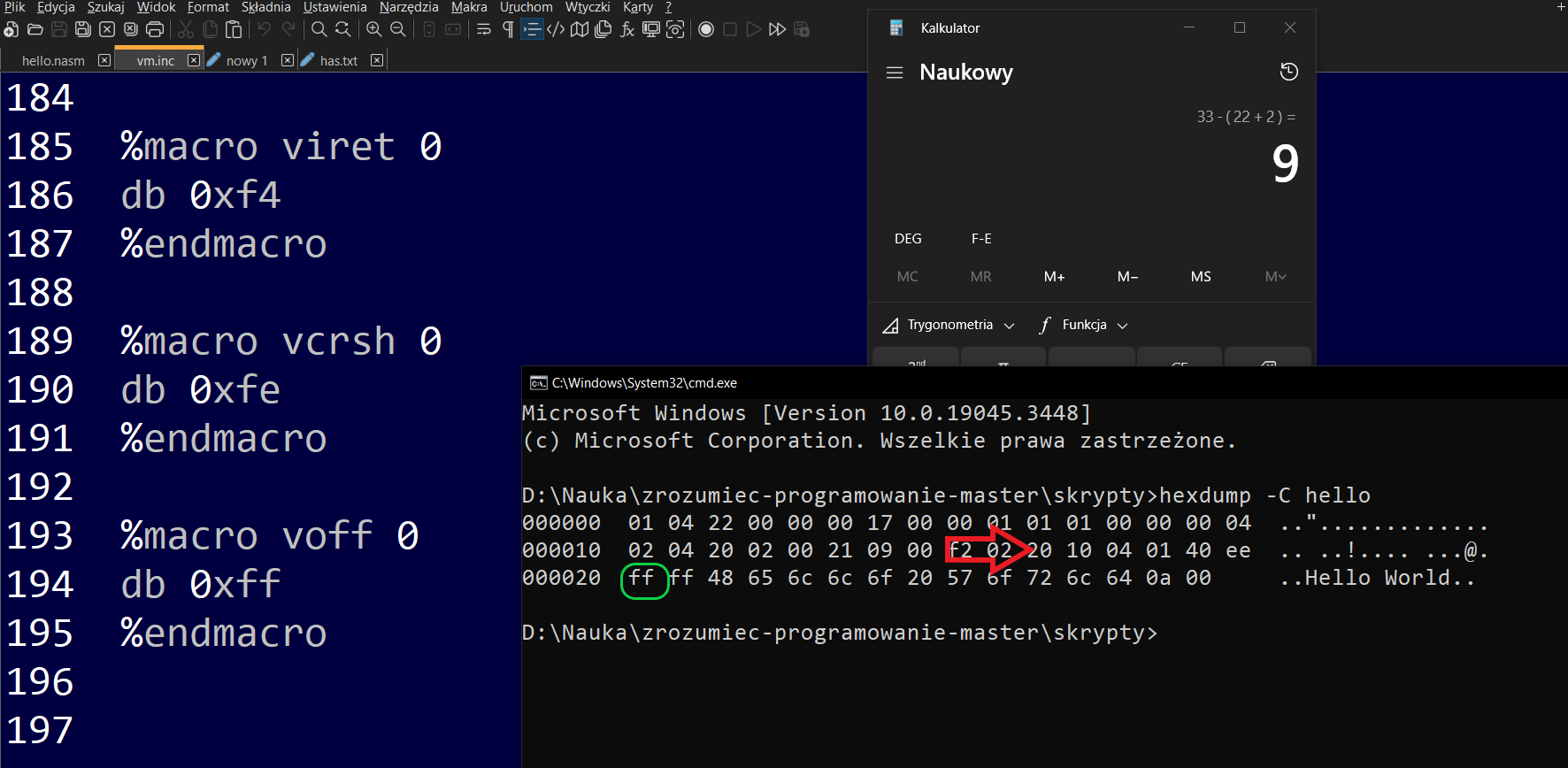 przesyłam screena - tak dla upewnienia się czy dobrze zrozumiełem
przesyłam screena - tak dla upewnienia się czy dobrze zrozumiełem
