Wyrażenia Regularne (Regular Expression)
piechnat
Regular Expressions, Regex, Regexps - Wzorce tekstu, mające odwzorować dany łańcuch symboli lub meta-symboli. Najpopularniejszym wykorzystaniem są:
- Sprawdzenie czy łańcuch pasuje do wzorca (np.
matches,test) - Wyszukiwanie łańcuchów pasujących do wzorca (np.
match,matchAll) - Zamiana pasującego łańcucha na inny, lub na część pasującego wzorca (np.
replace) - Rozdzielenie łańcucha na kolekcję w miejscu pasującym do wzorca (np.
split)
Wyrażenia regularne są już często wbudowanym elementem bibliotek standardowych wielu popularnych języków, takich jak Java, PHP, JavaScript, C#, Python, Ruby, C++ i innych - a znaczy to że można ich używać bez żadnej konfiguracji.
Kilka lat temu popularne były różne wersje wyrażeń regularnych: bash patterns, extended patterns (ereg), aż to czasu kiedy to wzorce zaczerpnięte z języka Perl stały się aktualnym standardem. Można się odnosić do nich skrótem PCRE - Perl Compatible Regular Expressions.
Użycie w popularnych językach programowania
Spróbujemy sprawdzić czy ciąg `Jestem Adam` pasuje do wzorca `\w+`. Znak specjalny `\w` oznacza literę lub cyfrę, `+` oznacza "więcej niż jeden raz" (czyli chcemy sprawdzić czy występuje "litera lub cyfra więcej niż jeden raz") - dokładniej o znakach specjalnych w sekcji niżej. Teraz skupmy się na użyciu wyrażeń regularnych w języku programowania:Java:
if ("Jestem Adam".matches("\w+")) {
PHP:
if (preg_match('/\w+/', 'Jestem Adam') > 0) {
JavaScript:
if (/\w+/.test("Jestem Adam")) {
C#:
Match result = Regex.Match("Jestem Adam", @"\w+");
if (result.Success) {
Python:
import re
if (re.search("\w+", "The rain in Spain")):
Ruby:
if ("Jestem Adam" =~ /\w+/)
C++:
#include <regex>
regex pattern("\w+");
if (regex_match("Jestem adam", pattern)) {
Wyrażenia regularne
Symbole specjalne w wyrażeniach regularnych można podzielić na:
- Kwantyfikatory - definiującą ilość wystąpień innego symbolu (np. dwa razy, co najmniej raz, zero lub więcej razy)
- tzw. "Wildcard" - pasującego do jakiegoś znaku (np. dowolny znak, jeden z grupy, każdy oprócz, litery, cyfry, znaki akcentowane, białe znaki)
- Meta znaki - nie oznaczających faktycznych znaków, (np. koniec linii, początek linii, początek słowa)
- Grupy - Pod-wzorców, alternatywa, tzw. "look behind" oraz "look ahead"
Są jeszcze inne, bardziej specyficzne i dokładne elementy wyrażeń regularnych, można znaleźć o nich informację tutaj.
Proste przykłady
Poniżej znajduje się lista przykładowych wyrażeń regularnych z możliwymi podmiotami które do nich pasują:
Podmiot1 | Podmiot2 | Wyjaśnienie | Wzorzec
-- | -- | --
Yo | Yoooooo | Znak Y oraz znak o występujący jeden lub więcej razy | Yo+
mp3 | mp4 | Znaki mp oraz jeden ze znaków 3 lub 4 | mp[34]
rak | rok | Znak r, dowolny znak, znak k | r.k
patrz | patrzę | Znaki patrz oraz znak ę zero lub jeden raz | patrzę?
patrzymy | patrzysz | Znaki patrzy i jedna z grup znaków my lub sz | patrzy(my|sz)
http:// | https:// | Znaki http, znak s zero lub jeden raz, znaki :// | https?://
dom | radom | Znaki dom a następnie koniec ciągu | dom$
Pz^%$# | Pz%#GT | Początek ciagu, a następnie znaki Pz | ^Pz
Oczywiście dopasowanie wzorca w ciągu nie musi odbywać się od jego początku do końca. Wzorzec words? może zostać odnaleziony zarówno w słowach word, words jak również I don't like words.
Praktyczny przykład
Chciałem znaleźć w tekście wystąpienia słów mających 3 lub 4 litery, które kończą się na e lub t. Oto wynik:
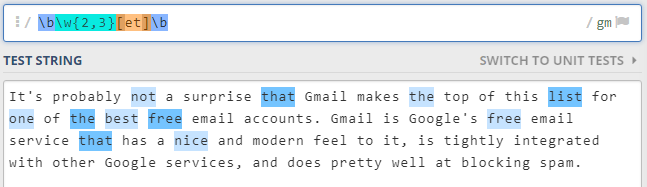
Do skorzystania z wyrażeń regularnych online skorzystałem z narzędzia regex101.com
Co może być problemem że program z wykorzystaniem regular expresion u mnie działa a na innym komputerze nie
Super artykuł! Dziękuję!
Wyjaśnienie niezbędne bardzo początkującym takim jak ja, bo długo się samemu do tego dochodzi...: Kiedy widzimy "na piśmie" ukośniki odwrotne dwa (w przypadku tego artykułu tam gdzie pokazano kasowanie "specjalności" jakiegoś znaku, np. kropki), to pisząc to w swoim kodzie stosujemy tylko jeden.
to jest chyba bledne ?
Jak dopasujesz slowa konczace sie na "t" ?
Wreszcie normalny artykuł o RegEx, coś się z niego nauczę xD
albo poprostu:
http://perldoc.perl.org/perlre.html
Wyśmienity artykuł, tylko o '+' powinieneś więcej napisać...
No i przydałby się opis pełnej notacji perla, czyli
(?:)i inne tego typu przydatne rzeczy :)Jeśli ktoś szuka full wypas opisu pełnej notacji zapraszam na genialną stronę:
http://www.regular-expressions.info
Dla mnie bomba. Zawsze chciałem poznać te wyrażenia...
preg* to wyrazernia regularne perla (podobno szybsze)
bardzo dobry artykuł. nareszcie nauczylem sie tych wyrazen!
ale mam jedną uwage: wyrażeń regularnych można uzywac tez w funkcjach preg_, np. preg_match(), preg_replace(), itd...
ale ogólnie umie gosć nieźle tłumaczyć.
Jak mogłem pominąć ten art :)
Super! Tylko tam gdzie jest mu* jeszcze m dodaj :)
masz świętą racje, a poza tym skąd ja to caaat wziąłem a nie caaal :-) całe to badziewie do poprawki...
problem w tym że, poprawienie tego na tym forum jest dosyć trudne, długo się grzebałem za nim porobiłem wszystkie slashe przed średnikami i itp... jak bym teraz to edytował to by się jeszcze więcej błędów zrobiło ;-( może w coyote będzie lepiej albo jak masz ochotę to sam spróbuj to poprawić ;-p
"c.*l" - caat, cut, ct, cool, coooool, coooooooooooooooool itd..
Zmieniłbym ten przykład - sugeruje on, że * sygnalizuje wystąpienie dowolnej liczby takich samych elementów, a to przecież nieprawda.
casdaqw412$!@#!tllllll też spełnia warunek :)
dzięki temu artowi nauczyłem się wyrażeń regularnych... bardzo dobry text! dzięki dla autora!
Swietny i tyle
Bardzo dobry artykuł :) Wiele się można nauczyć :D Polecam !!
Prosto, zabawnie i na temat :)