Na forum 4programmers.net korzystamy z plików cookies. Część z nich jest niezbędna do funkcjonowania
naszego forum, natomiast wykorzystanie pozostałych zależy od Twojej dobrowolnej zgody, którą możesz
wyrazić poniżej. Klikając „Zaakceptuj Wszystkie” zgadzasz się na wykorzystywanie przez nas plików cookies
analitycznych oraz reklamowych, jeżeli nie chcesz udzielić nam swojej zgody kliknij „Tylko niezbędne”.
Możesz także wyrazić swoją zgodę odrębnie dla plików cookies analitycznych lub reklamowych. W tym celu
ustaw odpowiednio pola wyboru i kliknij „Zaakceptuj Zaznaczone”. Więcej informacji o technologii cookie
znajduje się w naszej polityce prywatności.
I widzę w networkach, że search idzie na ten sam adres, na którym jest ta podstrona tj. https://www.facesearchai.com/dashboard/search . To jest tak zrobione, że na GET zwraca html, a przy POST działa jak endpoint? W postmanie na POST zwraca mi cały html strony. To ma działać jako zabezpieczenie, czy co? To jest sposób na ukrycie endpointa?
@roark.dev wiem, ale POST z odpowiednim body puszczony przez postmana zwraca 200 i HTML strony, więc jest inny response niż w przeglądarce. I chodzi mi o tę różnicę. To jest rodzaj zabezpieczenia? Co zrobić, żeby otrzymać respons jak w przeglądarce?
A jeśli się nie da, to jak zrobić coś takiego analogicznie? Chciałbym u siebie ukryć endpointy, bo captcha cloudflare ma gotowe solvery na githubie i kradną wyniki.
To podaj jaki według ciebie idzie request w przeglądarce, jaki w postmanie, oraz co otrzymujesz tu i tu... szklanej kuli nie mamy.... poza tym są jeszcze inne rzeczy niż body - np. headery.
Za tą usługą raczej jest konkretny program ‘servera’. W żądaniu wyszukania twarzy otrzymuje nagłówek “Next-Action”; jego odpowiednia zawartość jest wymagana, by uzyskać właściwą odpowiedź. On przypuszczalnie wiąże żądanie z tym, co użytkownik przegląda na stronie. Nie sądzę, że istotne w tym przypadku jest ukrycie adresu.
Niestety już zmienili stronę, więc nie jestem w stanie wykazać jaka jest różnica responsa w przeglądarce i postmanie XD
Pomińmy to w takim razie, skoro nie znam niewiadomych i skupmy się na tytule tematu.
Jest endpoint, który przyjmuje w body:
Kopiuj
image: base64 string
turnstileToken: string
jest do niego strzelane z frontu. Okazało się, że captcha cloudflare jest beznadziejna i są na GH biblioteki do jej rozwiązywania poprzez headless browser, więc niepowołane osoby kradną wyniki z tego endpointa. Captcha od googla ma ceny jakieś z kosmosu. Jak byście zabezpieczyli taki endpoint?
Co to znaczy niepowołane? Chyba, jest tam jakieś logowanie i headery z tokenem? Można dać np. ograniczoną ilość requestó per user, lub nawet per token i konieczność odswieżenia tokeny, oraz mozliwość ograniczonej ilości odswieżenia tokenu. No ale to zależy jaki jest regulamin, bo może jest legalnym tylerazy się pytać api? Można wykrywać też anomalia po ruchu od danego usera i go banować lub obsługiwać tylko co nte żądanie.
@roark.dev Darmowa wersja pozwala niezalogowanym użytkownikom na wykonywanie pewnej ilości zapytań razem z ustawionym limiterem, który co jakiś czas wyświetla dodatkową captchę. Przez to, że są niezalogowani, to jest to śledzone po IP. No, ale takie coś obchodzą dzięki proxy. Z kolei wymuszenie konta może obniżyć sprzedaż, dlatego tak to wygląda obecnie. Ja bym wymusił posiadanie konta, ale to akurat nie moja decyzja.
Jak nie masz identyfikacji usera to nic nie pomoże poza captchą. Nawet wprowadzenie darmowego tokena nic nie da, bo token można generować co chwila, jeśli mają ciągle inne IP.
Tzn. można próbować wykrywac, że to ten sam bot, dodawac jakiś JS do komunikacji po gRPC i generowanie finerprintów z user agenta, ale też np. wersji libek itd. itd. ale to nie będzie zabezpieczenie, a bardziej utrudnienie pracy złodzejom i można liczyć jedynie, że się zniechęcą. Można też generować dynamicznie endpointy zwracane w get w endpoincie, lub po grpc/signalR - ale to wszystkie nie jest uszczelnienie na 100% a nadzieja, że haker albo nie będzie miał dostatecznej wiedzy albo się zniechęci.
A captcha z googla ma teraz takie ceny, że wyszłoby przy tym ruchu z 20 tysięcy dolarów miesięcznie, czyli dużą część zysku, więc to się nie kalkuluje w ogóle XD
Na zwykłych użytkowników może wystarczy, ale tu chodzi o takich, którzy próbują wykorzystać to biznesowo. Więc captchę mam i chodzi mi o to, jakie kolejne kroki podjąć.
Lepszą captche. Nie wymagać kont i wykluczyć boty to jak mieć ciastko i zjeść ciastko. Ja bym wrzucił logowanie po FB/Google/itd. wrzucił to na 10% userów co włączają stronę. Zbadał, o ile spadnie ilość zainteresowania w tych 10% - tzn. czy procent ludzi z testowego setupu, którzy kupują produkt jest dużo mniejszy niż w pozostałych 90% anonimów no i policzył co się bardziej opłaca. Może włączenie logowania będzie tańsze niż captcha, a zminimalizuje koszty chmury "marnowaną" na ludzi kradnących darmowe requesty. Szklanej kuli tu nie ma - trzeba zbadać i odpalić Excela.
To typowo biznesowe pytanie które na jakimś etapie powinno paść. Ile odsiejemy i czy nie zniechęcimy innych. Testy A/B itd. Tylko to raczej nie rola programisty by decydować o cyferkach.
Dobra, to nie chcesz nic ukrywać, tylko zabezpieczyć przed botami?
Bo z treści wynika jakbyś nie wiedział co się dzieje w tej aplikacji i próbował sam z niej skorzystać w sposób zautomatyzowany.
Jeśli nie masz żadnego mechanizmu logowania itp, a nie chcesz płacić za captcha od innych to stwórz nawet prostą ale swoją, nawet w formie 200 pytań i odpowiedzi zahardkodowanych.
Pytanie jaki biznesowo procent botów/użytkowników chcesz wyciąć.
@1programmer myślałeś o normalnym cloudflare tj. takie co przepuszcza cały ruch? Jakieś pół roku temu rozkminiałem temat (punktem startowym było GCP i reCaptcha z Googla) i generalnie konkurencja nie wygląda znacząco lepiej xd
Tak czy owak wymóg rejestracji będzie pomocny zarówno bez captchy jak z nią
I widzę w networkach, że search idzie na ten sam adres, na którym jest ta podstrona tj. https://www.facesearchai.com/dashboard/search . To jest tak zrobione, że na GET zwraca html, a przy POST działa jak endpoint? W postmanie na POST zwraca mi cały html strony. To ma działać jako zabezpieczenie, czy co? To jest sposób na ukrycie endpointa?
Na pewno to nie jest "ukrycie endpointa" - co by to miało niby dać? Po prostu nazwali tak sobie endpoint i tyle.
Na 99% obecnie oponenci używają jakiegoś playwrighta albo selenium i scrapują response. Są jakieś metody na taki konkretny case?
Nie możemy wprowadzić obowiązkowego logowania, bo nie mamy jeszcze mocno ugruntowanej pozycji i boimy się spadku ruchu, a co za tym idzie konwersji. W przyszłości tak, teraz nie,
Generujcie ramdomowy response i generujcie też js który ten response prasuje. Bez ręcznego zmieniania skryptu się nie obędą a jak będzie to inne przy każdym requescie to nie ogarną.
Na 99% obecnie oponenci używają jakiegoś playwrighta albo selenium i scrapują response. Są jakieś metody na taki konkretny case?
Nie możemy wprowadzić obowiązkowego logowania, bo nie mamy jeszcze mocno ugruntowanej pozycji i boimy się spadku ruchu, a co za tym idzie konwersji. W przyszłości tak, teraz nie,
A co Wam przeszkadza że ktoś robi scrape? Podaj konkretny use-case w Twoim przypadku, bo rozwiązanie będzie zależało od tego co Ci przeszkadza w tym ze ludzie parsują response.
@Riddle Nie ludzie, tylko złodzieje z pakistanu, którzy tworzą bliźniaczą usługę poprzez ukradzione wyniki. Czyli zrobili sobie front i sprzedają na subskrypcji wyniki, które kradną, więc to chyba nie jest ok? XD
Złodzieje mieli wcześniej inne projekty i przez to dobrą pozycję w google. No to jeśli strona, która kradnie jest wyżej w wyszukiwarce od oryginalnej strony, to jest lipa.
Dostęp do API jest dodatkowo płatny.
Problemem nie są klienci indywidualni, tylko złodzieje, którzy próbują na tym zrobić biznes przy zerowych kosztach.
SEO niestety potrzebuje czasu. Chociaż na tym to się nie znam.
@Riddle Nie ludzie, tylko złodzieje z pakistanu, którzy tworzą bliźniaczą usługę poprzez ukradzione wyniki. Czyli zrobili sobie front i sprzedają na subskrypcji wyniki, które kradną, więc to chyba nie jest ok? XD
Złodzieje mieli wcześniej inne projekty i przez to dobrą pozycję w google. No to jeśli strona, która kradnie jest wyżej wyszukiwarce od oryginalnej strony, to jest lipa.
Generujcie ramdomowy response i generujcie też js który ten response prasuje. Bez ręcznego zmieniania skryptu się nie obędą a jak będzie to inne przy każdym requescie to nie ogarną.
Wyjaśnisz bardziej, jak to ma działać i jaki da efekt, bo nie czaję?
Pomyślałem, żeby zwracać wynik (zdjęcia) i z jakimś przesunięciem bitowym, żeby przychodziły scorruptowane z endpointa i odwracać to na froncie za pomocą algorytmu zaciemnionego obfuscatorem. Niby można to odwrócić, ale zrobiłem tak z tokenem turnstile tj. captchy cloudflare i jedną metodę im zblokowałem. Tylko jeśli renderują całą stronę to lipa, a robią to teraz prawie na pewno, bo czeka się dużo dłużej na wyniki.
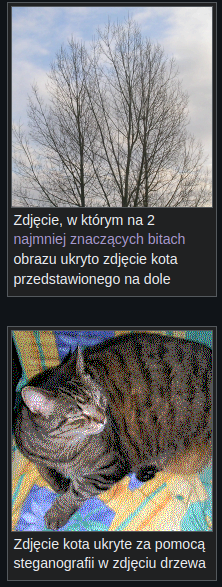
Albo może da się użyć steganografi do takiego czegoś? Kiedyś widziałem, że jest taka pseudo emulowana konsola ala gameboy i gry tam były zakodowane w kanale alfa obrazków PNG. No i zastanawiam się, czy by może nie dało się kodować prawdziwych wyników w jakichś fake wynikach XD
Co myślicie, odklejka i strata czasu? Może lepiej skupić się na SEO i po prostu wyświetlać się wyżej w wyszukiwarce?
odwracać to na froncie za pomocą algorytmu zaciemnionego obfuscatorem
No ale skoro będzie to na froncie, to znaczy, że potencjalny złodziej ma do tego dostęp. OK, możesz zaciemnić kod - w czasach, gdy ludzie się tym zajmowali to było to mocne utrudnienie. Tylko teraz taki kod wrzucisz do AI/ML i jemu nie robi różnicy, czy masz function setCośTam (int Xcoords, bool showBlaBla) czy X(d:e){x4xazs;}, więc algorytm odszyfrowujący z frontu po chwili będzie jawny i działający na potrzeby Hindusów/Pakistańczyków (czy jak to się tam odmienia).
Myślę, że poradzi sobie 300x lepiej od człowieka. W końcu - my, żeby rozumieć kod, dajemy opisowe nazwy zmiennych czy funkcji, formatujemy kod, bo inaczej trudno jest odczytać i zrozumieć. Taki interpreter JS czy PHP tak samo sobie radzi ze zrozumieniem wersji pierwotnej, jak i zminifikowanej/zaciemnionej. Czyli, skoro maszyna (np. intepreter czy kompilator) sobie radzi tak samo, niezależnie od tego, czy masz ładne nazwy, czy krzaczki - myślę, że analogicznie będzie znacznie łatwiej AI zrozumieć, co robi dany kawałek kodu po jego zamaskowaniu.
Czyli apka z pierwszego postu używa Twojego Endpointu "za darmo"?
IMHO żadne obfuskacje nie mają sensu.
Chcesz blokuj im IP.
Dla osób korzystających za darmo z Twojego rozwiązania dodaj do obrazka jawny IP z jakiego był request u Ciebie i info typu utworzono za pomocą strony: Twoja strona www.
Raz na dwa dni sprawdzisz z jakiego IP robią reqesty sam korzystając z ich strony, a każdy użytkownik ich rozwiązania ma na tacy podany właściwy adres Twojej strony.
Tylko to oczywiście też kwestia biznesowa.
@cerrato akurat zrobiłem tak 2 dni temu z tym tokenem captchy, testowałem na wszystkich najlepszych modelach pod programowanie i nie udało im się, więc to też nie tak 100%. Jak AI nie da rady i trzeba by nad tym siedzieć, to można by żonglować tym i w końcu pływakom z Gangesu może się odechce XD
No i tych złodziei to nie jest jeden, tylko było z 5 - 6, ale innym właśnie się odechciało w końcu albo rozkminiają to, co wcześniej zmieniłem. Nie byliśmy świadomi skali, a także niektórych dziur, nie tylko na froncie.










{kind=link}
{kind=link}
{kind=link}