Jak myślicie, jaki będzie wynik takiego kodu:
$value = \array_rand(['apple', 'banana', 'pear']);
Co może być w $value? Pewnie jeden z tych owoców, nie? Otóż nie. Bo array_rand() zwraca losowy klucz  A nie wartość.
A nie wartość.

Jak myślicie, jaki będzie wynik takiego kodu:
$value = \array_rand(['apple', 'banana', 'pear']);
Co może być w $value? Pewnie jeden z tych owoców, nie? Otóż nie. Bo array_rand() zwraca losowy klucz A nie wartość.
Mam dodać endpoint w jednym serwisie w Javie. Serwis nowy, bo tylko jakiś rok ma. Nie wiem czym kierowali się autorzy, ale natłuczone dokładnie 47 interfejsów. Każdy z nich ma tylko jedną implementację. I teraz tak:
@AllArgsConstructor (nic innego z lomboka nie użyto), mimo że każda klasa miała jedną, dwie, maksymalnie trzy składowe do wstrzyknięcia (czyli chciało im się pisać interfejsy, nie chciało się napisać czy po prostu wygenerować konstruktora...).Osobiście nie jestem fanem interfejsów, które mają tylko jedną implementację, zwłaszcza gdy można się spodziewać podczas klepania kodu, że większej ilości po prostu nie będzie. Jeszcze, gdyby wstrzykiwano po typie interfejsu, to można to na siłę uratować, ale w opisanym przypadku powyżej jest to po prostu bez żadnego sensu.

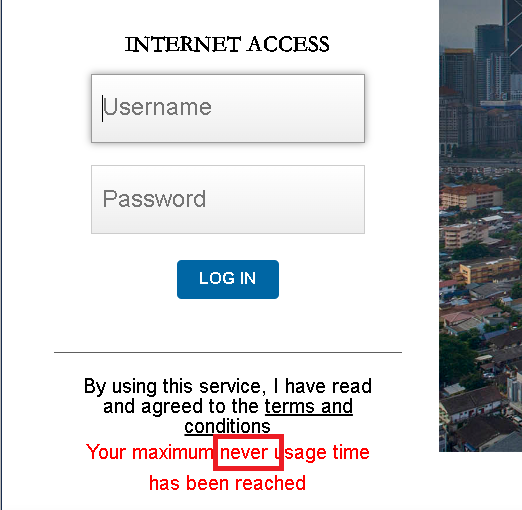
Bugi teams dalsze mistrzostwo.
Na Windows współpracownika widzę normalnie Imię Nazwisko.
Na innym komputerze (MacOS) tak się wyświetla:
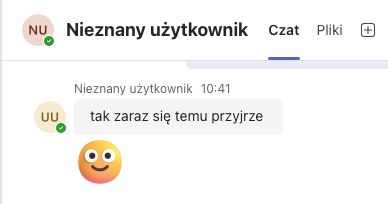
To jest jeden użytkownik! Na górze tytuł rozmowy z "NU" (nieznany użytkownik), w treści rozmowy awatar "UU" (Unknown User) :).
Nie dość, że od miesiąca nie może zsynchronizować informacji o tym użytkowniku, to jeszcze wyświetla go na dwa sposoby.
Znalazłem taki kod w kodzie źródłowym laravela:
<?php
public static function configure(?string $basePath = null)
{
$basePath = match (true) {
is_string($basePath) => $basePath,
default => static::inferBasePath(),
};
I się zastanawiam, na prawdę ten match() jest lepszy niż ternary zwykły?
$basePath = is_string($basePath) ? $basePath : static::inferBasePath();
Czytam sobie dokumentację pewnej funkcji w PHP (niestety, okropny język), i znalazłem śmieszny kwiatek:
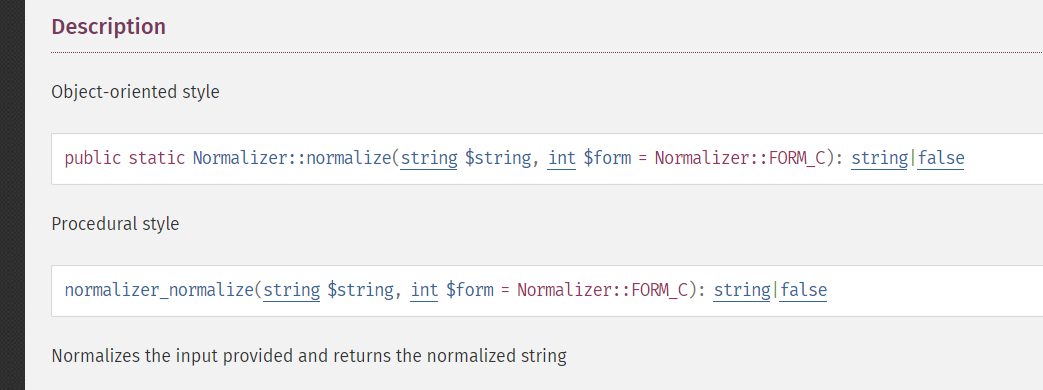
Dokumentacja tutaj pisze że globalna funkcja to "procedural style", ale już statyczna metoda na klasie to jest "Object-oriented style".
Co jest zabawne, bo oba te podejścia są proceduralne (nie żeby było z tym coś złego ofc).


Zapewne program tworzący spis treści wpisał komunikat o błędzie do wyjścia, a powinien raczej zatrzymać się i powiadomić o sytuacji na konsoli, żeby wydawcy książki na pewno się zorientowali.

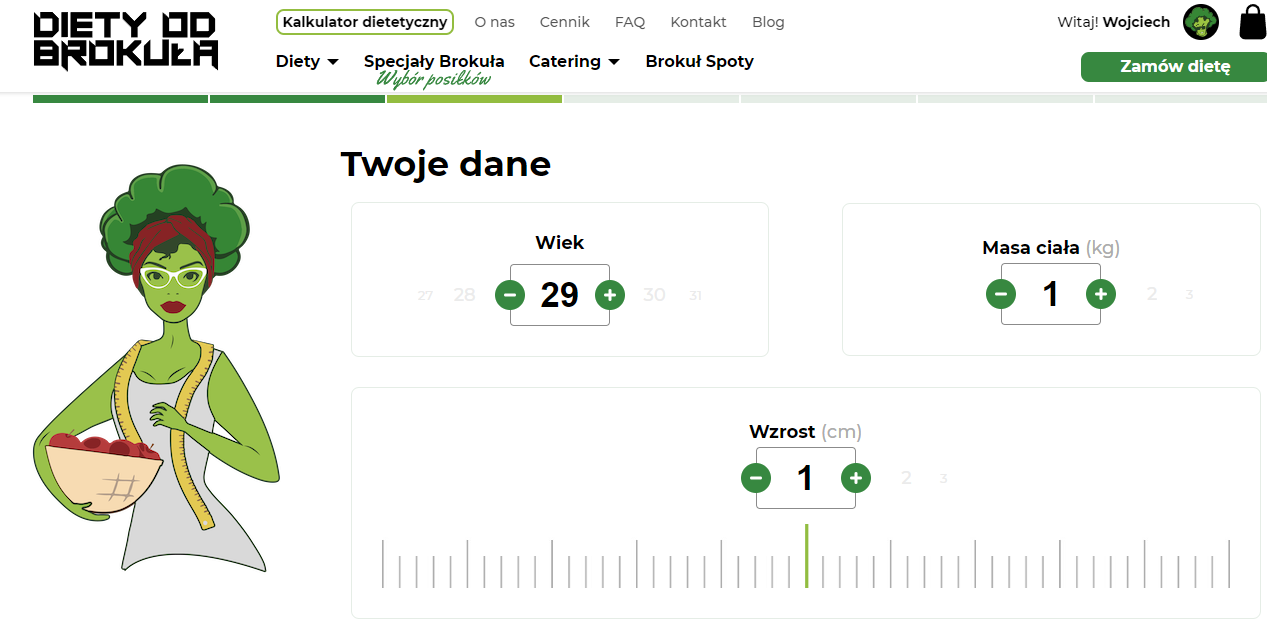
wiek, masę i wzrost wybierasz klikając w plusiki i minusiki począwszy od 1. Jak masz 180 cm to 180 kliknięć przed Tobą ;)
Na szczęście da się wpisać z klawiatury.

LitwinWileński napisał(a):
wiek, masę i wzrost wybierasz klikając w plusiki i minusiki począwszy od 1. Jak masz 180 cm to 180 kliknięć przed Tobą ;)
I to jest dobry powód żeby schudnąć, odrąbac sobie nogi i po prostu nie być starym.
zrozumiem prostą walidację x>0, ale nie wiem gdzie szukali maksymalnych wartości xD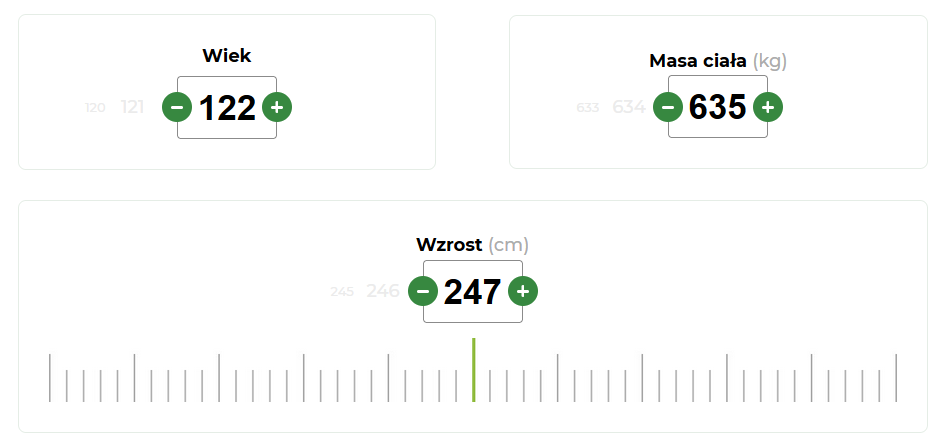

Wczoraj chciałem zobaczyć, jak się używa Scikit-learn w Pythonie.
tworzę sobie virtual env, instaluję co trzeba, przeklejam kod przykładu, nawet coś działa. Potem przeklejam kod kolejnego przykładu, odpalam i nie działa.
Pokazał się błąd:
ImportError: Error importing numpy: you should not try to import numpy from
its source directory; please exit the numpy source tree, and relaunch
your python interpreter from there.
Więc próbuję przenieść pliki nie wiadomo gdzie, ale dalej ten sam błąd.
Szukam w Google i sugerują, że wersje bibliotek mogą się nie zgadzać. Albo że ściężka się nie zgadza. Ale to się zgadzało. Nawet zapgrejdowałem Pythona, żeby nowe paczki wgrać. Albo napisali że trzeba dograć jakąś bibliotekę libopenblas-dev. Ogólnie już zacząłem przypuszczać, że to pod spodem mam niezaktualizowane paczki systemowe, z których to pod spodem korzysta. Ale nie bardzo chciało mi się w to bawić.
Dzisiaj natomiast, ponieważ chciałem zrozumieć, skąd ten błąd wynikł, to zacząłem szukać błędu, który wywołał ten podstawowy błąd.
ImportError: cannot import name 'Integral' from partially initialized module 'numbers' (most likely due to a circular import)
i tu już StackOverflow był sensownieszy i dał mi odpowiedź: https://stackoverflow.com/questions/72717979/python-importerror-cannot-import-name-from-partially-initialized-module
Co się okazało?
Otóż. To nie był problem z bibliotekami, tylko że niepozornie nazwałem plik numbers.py XD
Jaki był tego efekt? Że pod spodem jak gdzieś był importowany moduł numbers to chciał mój plik zaimportować, zamiast jakiś tam moduł pod spodem.
Zmieniłem nazwę pliku z numbers.py na blah.py i co się okazało? Działa.
Czyli czegoś się nauczyłem dzisiaj - w Pythonie trzeba uważać, jak się nazywa pliki.

@LukeJL to jak Python zostal powaznym branzowym standardem bardzo czesto mnie zastanaiwa. Problem ktory mnie ugryzl ostatnio (na samym dole link do buga) https://mas.to/@swelljoe/112957549219054708

Coś czego ostatnio się dowiedziałem o javascript i straciłem na tym dobre 15 minut. Zagadka - czy te dwa zapisy dadzą te same rezultaty:
[a, b, c].sort((x, y) => compareFn(x.n, y.n)).map(x => x.n)
[a, b, c].map(x => x.n).sort(compareFn)
?
...
Okazuje się że w przypadku gdy mamy wartości undefined to nie:
const a = {n:3};
const b = {};
const c = {n:1};
const compareFn = (x, y) => x === undefined ? -1 : y === undefined ? 1 : x - y;
console.log([a, b, c].sort((x, y) => compareFn(x.n, y.n)).map(x => x.n)); // [undefined, 1, 3]
console.log([a, b, c].map(x => x.n).sort(compareFn)); // [1, 3, undefined]
Dokumentacja https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/sort jasno mówi:
If compareFn is supplied, all non-undefined array elements are sorted according to the return value of the compare function (all undefined elements are sorted to the end of the array, with no call to compareFn).
Czyli wartości undefined w ogóle nie trafiają do naszej funkcji sortującej i lądują zawsze na końcu bez kontroli, chcesz je mieć na początku to kombinuj. Tu wychodzi duża różnica między undefined, null a empty bo nulle są normalnie obsługiwane, a empty nie trafia nawet do funkcji map i też zawsze lądują na końcu tablicy
@obscurity Jak odejmujesz undefined od number to dostajesz NaN, a to że sortowanie się psuje jak zwracasz NaN to mnie akurat nie dziwi.
Ale przekombinowałeś.
Chodzi Ci o to:
[undefined].sort(() => /* not called; */); // [undefined];

Oficjalna strona Motorloli https://www.motorola.com/pl/smartphones/ ma "doskonały" system filtrów. Wygląda, jakby każde z urządzeń dodawała inna osoba i pisała rzeczy z palca, a system filtrów przeszukiwał te oferty i robił distinc row na parametrach, czego efektem są takie koszmarki:

czy


Ludzie to mają fantazje aby zastraszać bank niebezpiecznikiem bo nie lubią danej implementacji logowania :D
Zwróciłem uwagę, że ING jako jeden z ostatnich banków na polskim rynku wymusza na użytkownikach logowanie przez podanie tylko kilku wybranych znaków hasła. O wadach tego rozwiązania toczyło się już wiele dyskusji, natomiast zastanawia mnie jedna rzecz:
W jakiej formie bank przechowuje hasła użytkowników? Hasło w całości można zahashować dzięki czemu bank nigdzie nie przechowuje hasła w formie możliwej do odczytania. Natomiast aby porównać poszczególne znaki hasła trzeba to hasło mieć w formie do odczytania. Ewentualnie przechowywać hashe każdej kombinacji wybranych znaków z hasła (w co nie chce mi się wierzyć). Czy zatem bank, w swojej trosce o bezpieczeństwo hasła, przechowuje je przewrotnie w plaintexcie?Oczywiście postuluje, jako jeden z wielu użytkowników, o udostępnienie użytkownikom opcji wpisywania hasła w całości, co przynajmniej umożliwi ustawienie sobie hasła o odpowiedniej długości i poziomie skomplikowania. Do tego czasu połowa użytkowników pewnie nadal będzie miała za hasło "12345678", co sprytniejsi "23456789" Emotikon: Mrugający
Prośba o przekazanie opinii w górę drabinki korporacyjnej. Mam nadzieję, że prośby o zdrowy rozsądek zostaną w końcu wysłuchane, inaczej chyba zostanie nam kampania oparta o Niebezpiecznik, Zaufaną Trzecią Stronę, ewentualnie konsultacje z CERT Polska.
Pozdrawiam
DC
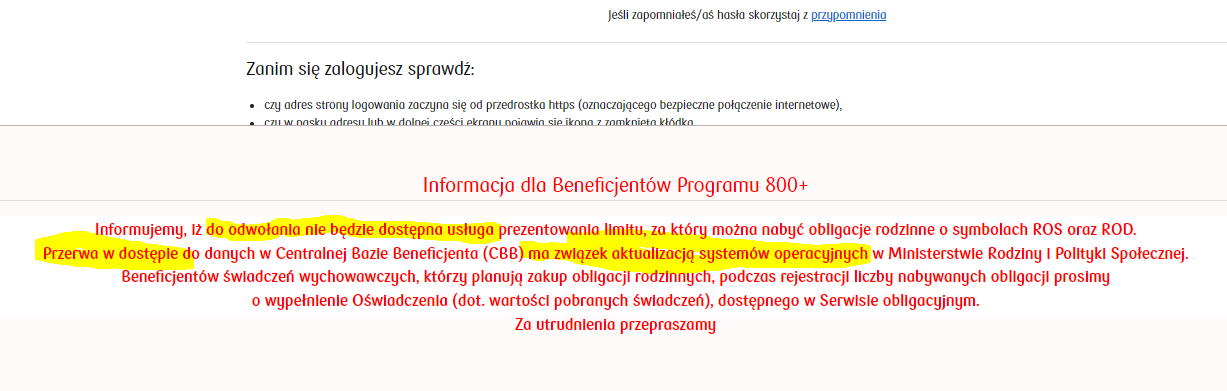
Wygląda to na nieplanowaną "aktualizację systemów operacyjnych". Źródło: https://www.zakup.obligacjeskarbowe.pl/
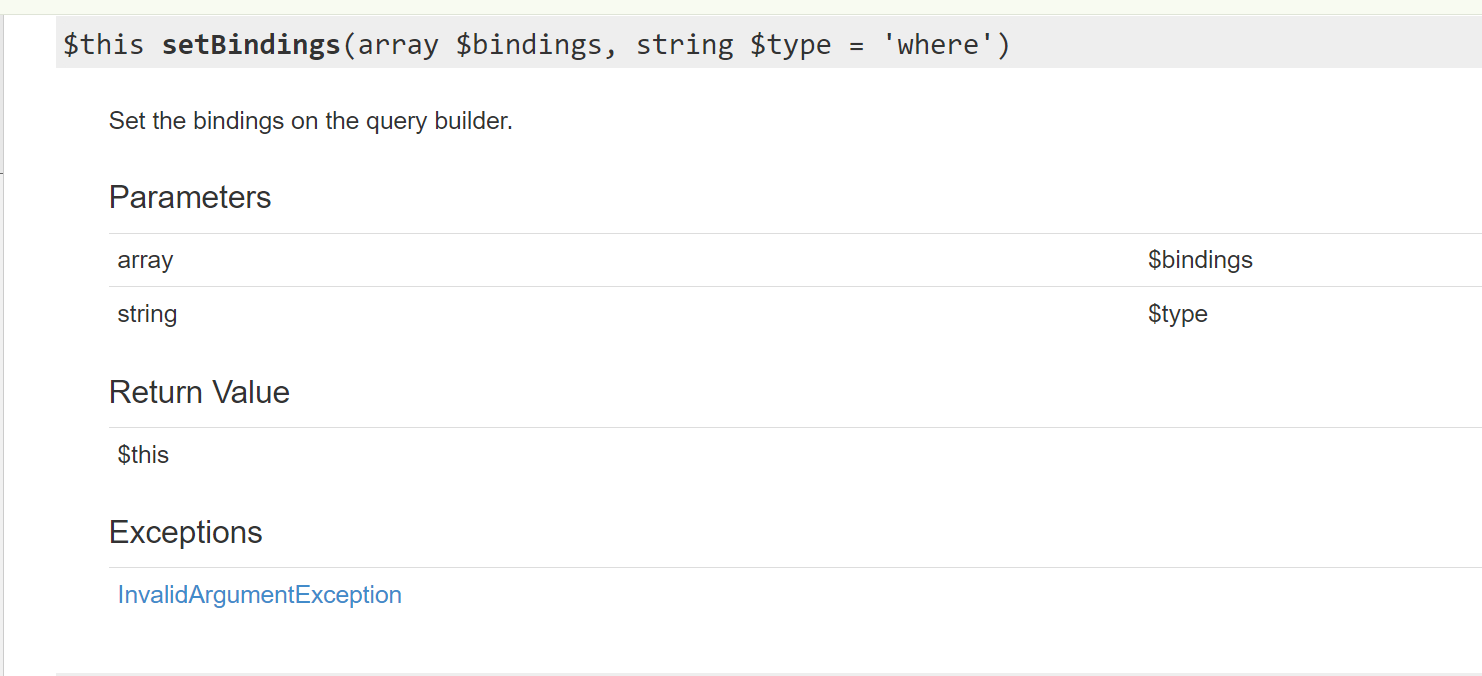
To ma być dokumentacja? https://laravel.com/api/11.x/Illuminate/Database/Query/Builder.html#method_setBindings

https://www.esp.pwpw.pl/Account/Index
Maksymalny rozmiar załącznika to 1024KB, na szczęście włączenie najniższej jakości w aparacie dawało załączniki około 800KB.

Źródło: https://api.raporty.pse.pl/
PSE chyba jednak stać na to by to poprawić...


Ciekawe czy ten róż to ostateczna wersja, czy pójdą na całość i dodadzą więcej kolorów, aby mieć gejowską tęczę zamiast paska postępu. Wszystko poragią zepsuć. 

Krew mi się gotuje jak widzę tego typu błędy kompilacji… Przeciążanie funkcji to syf, taki sam jak przeciążanie operatorów (albo nie, te są jeszcze gorsze). Kompilator zna typ zmiennej (32-bit integer ze znakiem), ale biedak nie potrafi wybrać odpowiedniej funkcji bo brakuje przeciążenia dla tego typu danych, więc trzeba mu ją palcem pokazać (tzn. rzutowaniem).
Dlatego właśnie olewam tego typu wynalazki i w swoim silniku, jeśli mam jedną funkcję, ale która może obsługiwać różne typy danych (np. integery o różnych rozmiarach i znakach), to mają oddzielne nazwy — np. Game_MapS32 (32-bitowy integer ze znakiem), Game_MapU32 (to samo, tyle że bez znaku), Game_MapF32 (32-bitowy float) itp. itd.
Żadnych problemów z kompilacją, żadnych problemów dotyczących nie tego przeładowania co chcieliśmy (bo kompilator automatycznie wybrał inne), do tego możliwość celowego użycia funkcji dla innego typu, aby uniknąć wyjścia poza zakres (kompilator sam wykona rzutowanie przez i po wywołaniu funkcji). Eskil znów miał rację.
Fajny fuckup systemowej szukajki:

Coś im rozciąganie kontrolek na całego klienta nie wychodzi.
Jaki niesamowity wybor: 
W kodzie pewnego open-sourceowego projektu:
if (level === 2) return ['indent', 'indent-1'];
if (level === 3) return ['indent', 'indent-2'];
if (level === 4) return ['indent', 'indent-3'];
if (level === 5) return ['indent', 'indent-4'];
if (level === 6) return ['indent', 'indent-5'];
if (level === 7) return ['indent', 'indent-6'];
if (level === 8) return ['indent', 'indent-7'];
if (level === 9) return ['indent', 'indent-8'];
if (level === 10) return ['indent', 'indent-9'];
if (level === 11) return ['indent', 'indent-10'];
if (level === 12) return ['indent', 'indent-11'];
U mnie na projekcie był kod
if(JAKIS_ENUM.equals(zmienna)) {
return true;
} else {
return false;
}
Ale ktoś to po 10 latach zauważył i poprawił na
if(JAKIS_ENUM == zmienna) {
return true;
} else {
return false;
}
obscurity napisał(a):
W kodzie pewnego open-sourceowego projektu:
Oczywiście dałoby się to napisać bez ifologii, np tak:
if (level === 0 || level === 1) {
return ['indent', 'indent-none'];
}
const indentClasses = ['indent-1', 'indent-2', 'indent-3', 'indent-4', 'indent-5', 'indent-6', 'indent-7', 'indent-8', 'indent-9', 'indent-10', 'indent-11', 'indent-12'];
return ['indent', indentClasses[Math.max(indentClasses.length, level - 2)]];
albo nawet tak:
const indentClasses = ['indent', 'indent', 'indent-1', 'indent-2', 'indent-3', 'indent-4', 'indent-5', 'indent-6', 'indent-7', 'indent-8', 'indent-9', 'indent-10', 'indent-11', 'indent-12'];
return ['indent', indentClasses[Math.max(indentClasses.length, level)]];
Ale taki zapis dla mnie miał bardzo poważną wadę - nie da się na pierwszy rzut oka ocenić który level odpowiada któremu indentowi. Są równe? Jeden w górę? Jeden w dół? Dwa w górę? Chciałem żeby to było widoczne, dlatego wybrałem taką ifologię, że if (level == coś) return indent-coś.
Możnaby też wygenerować klasę po prostu, np tak:
if (level === 0 || level === 1) {
return ['indent', 'indent-none'];
}
const indent = Math.max(indentClasses.length, level - 2);
return ['indent', 'indent-' + indent];
Ale wtedy nazwa klasy nie pojawiłaby się w source-codzie i jej wyszukanie daje nam wtedy:

Więc taka ifologia, może i wydaje się niehaxiorska i amatorska, to dla mnie jest prosta, czytelna, łatwa do zmiany - właśnie dlatego że jest taka prymitywna. Nie muszę sobie łechtać ego próbując niepotrzebnie skomplikować ten kod.