Cześć.
Mały zarys tego co robię:
Odziedziczyłem pewien projekt po innym zespole - w skrócie Grafana robiąca wykresy z wielu baz danych (postgres, mysql) w tej samej korporacyjnej sieci. Poprzednicy założyli, że aby nie tracić na szybkości odczytu, to należy te bazy danych przepisywać do lokalnie (na serwerze aplikacji) postawionych baz na Dockerze. Wszystko fajnie ale:
- duplikuje się dane z pewnego okresu
- pojawia się problem, kiedy na naszym 2TB serwerze jednak skończy się miejsce na ten swoisty "cache"
- Grafana i tak jest wolna jeśli zrobić jej skomplikowane zapytania z jakimiś obliczeniami.
W skrócie schemat apki wygląda tak:
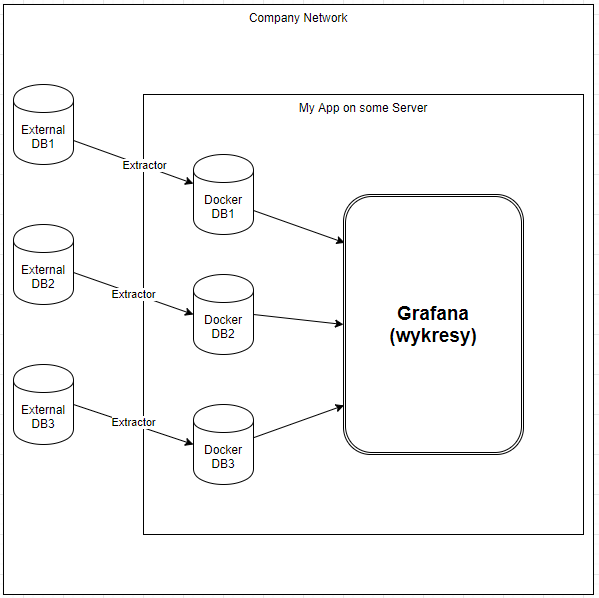
Jedyne plusy tego rozwiązania jakie widzę to:
- w trakcie przepisywania danych z bazy do bazy można coś robic z tymi danymi, ale to raczej rzadki przypadek.
Ja myślałem na sam początek w ogóle pozbyć się tychże baz Dockerowych i jechać na "zewnętrznych" zwłaszcza, że moja firma zapewnia im support i backup.
Korzyści z przepisywania danych z bazy do bazy nie widzę, żeby tylko je później wyświetlić nie widzę.
Pytanie do Was :)
Czy widzicie tu jakis potencjalny wzrost szybkości odczytu z bazy przez tą biedną Grafanę?
Czy są jakieś lepsze rozwiązania - np. cache dla częstych zapytań zamiast tych dockerowych baz, które zapchają prędko mój biedny serwerek?
Pozdrawiam i z góry dzięki za wszelkie uwagi :)