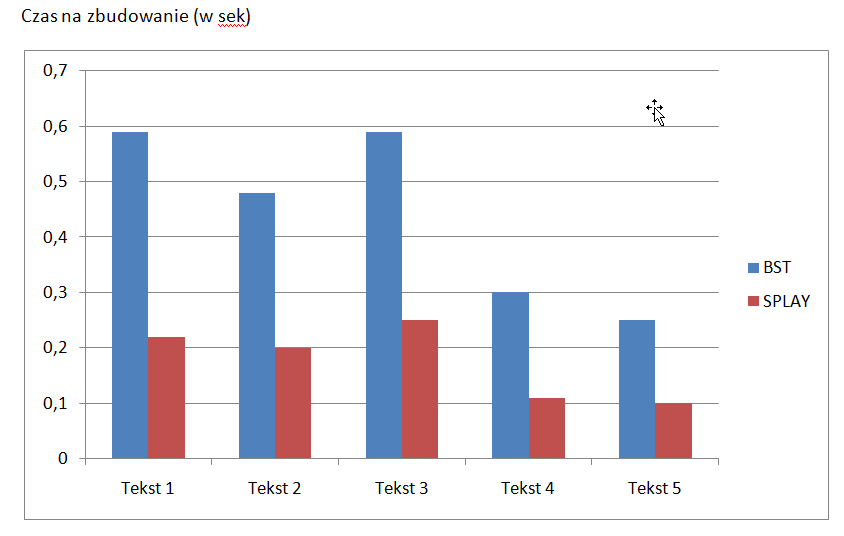
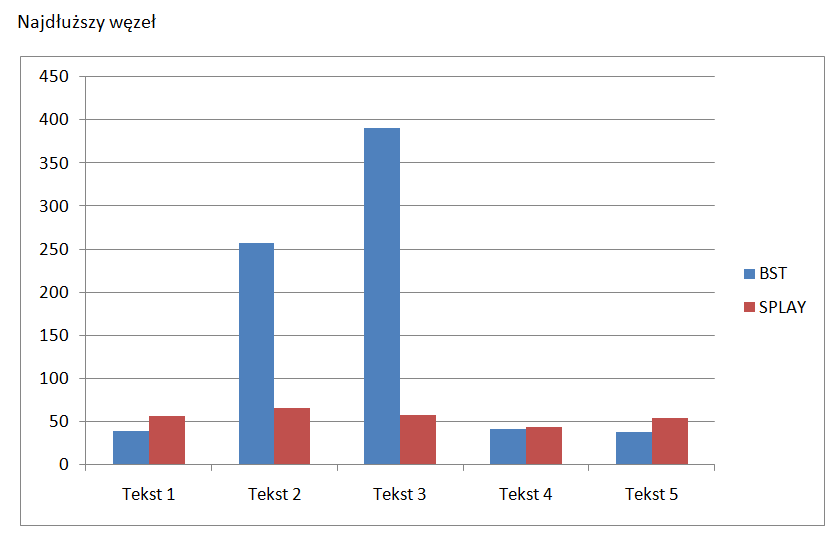
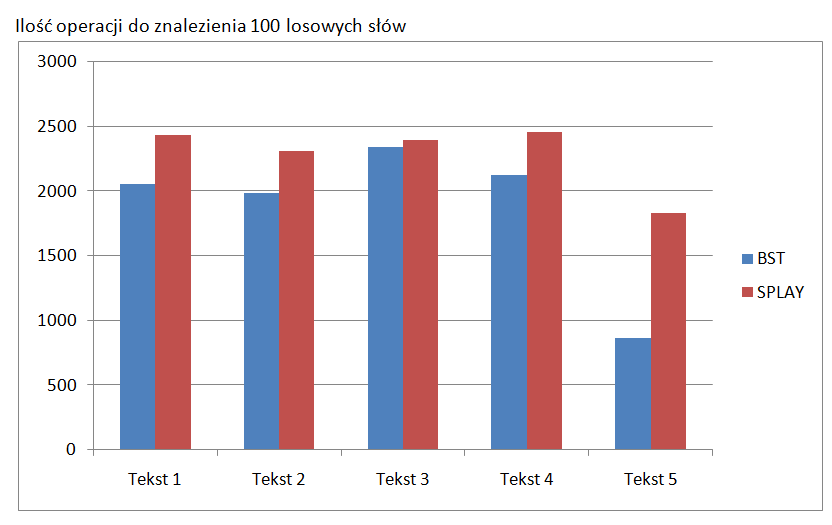
połączyłem teksty w jeden duży i zduplikowałem x16 w jeden plik i BST zrobiło w 44s Splay w 37s
Nadal brzmi mało. Ile masz L1,L2 i L3 cache? Na nowym CPU możesz mieć np. 16 czy 32MB. Żeby serio coś obserwować w benchmarku to trzeba by wrzucić np. GB tekstu, powiedzmy cała polską wikipedie ;)
co do tej średniej wysokości drzew, nie mam jestem pewien jak się za to zabrać, żeby policzyć, czy mógłbyś dać jakieś wskazówki?
Puść N wyszukiwań losowych słów i policz ile średnio nodów trzeba przejść zanim się coś znajdzie (w przypadku Splay ile "ruchów" trzeba wykonać). Jak weźmiesz losowe słowa to BST pewnie będzie wygrywać, ale jak weźmiesz słowa zgodnie z rozkładem statystycznym w tekście to spodziewałbym się ze Splay będzie dużo szybszy.
edit:
@tomek3113 pokaże ci kilka "trików", zebyś nie myślał że takie gdybanie nad jakimś cache ma w ogóle sens.
- Patrz na taki kod:
#include <cstdio>
#include <cstdlib>
#include <chrono>
#include <algorithm>
#include <vector>
using namespace std::chrono;
using namespace std;
vector<int> generateArray(int count, int max) {
vector<int> array;
array.reserve(count);
for (int i = 0; i < count; i++) {
array.push_back(rand() % max);
}
return array;
}
void plain(int count, int max) {
vector<int> array = generateArray(count, max);
auto start = high_resolution_clock::now();
int v = 0;
for (int i = 0; i < count; i++) {
if (array[i] < max / 2) {
v += 1;
}
}
printf("%d %d\n", v, high_resolution_clock::now() - start);
}
void sorting(int count, int max) {
vector<int> array = generateArray(count, max);
std::sort(array.begin(), array.end());
auto start = high_resolution_clock::now();
int v = 0;
for (int i = 0; i < count; i++) {
if (array[i] < max / 2) {
v += 1;
}
}
printf("%d %d\n", v, high_resolution_clock::now() - start);
}
int main() {
int count = 10000000;
int max = 10;
plain(count, max);
sorting(count, max);
}
Obie funkcje robią dokładnie to samo, robią tablicę z losowymi wartościami w zakresie 0..max a potem w pętli zliczają ile z tych wartości jest mniejsze od max/2 (powinna być jakaś połowa). Jedyna różnica między tymi dwiema funkcjami jest taka, ze funkcja sorting sortuje tablicę przed tą pętlą zliczającą. Sama pętla wygląda tak samo, więc gdyby patrzeć na to tylko z perspektywy złożonosci obliczeniowej to mamy w obu funkcjach O(n), a jednak empirycznie możesz to sobie odpalić i zobaczysz że wersja sortujaca będzie w praktyce dużo szybsza, u mnie na laptopie jakieś 3 razy (przy -O0). Zastanów się czemu tak się dzieje.
- Teraz drugi trik:
#include <cstdio>
#include <cstdlib>
#include <chrono>
#include <algorithm>
#include <vector>
using namespace std::chrono;
using namespace std;
vector<int> generateArray(int count, int max) {
vector<int> array;
array.reserve(count);
for (int i = 0; i < count; i++) {
array.push_back(rand() % max);
}
return array;
}
void sequential(int count, int max) {
vector<int> array = generateArray(count, max);
std::vector<int> indices(count);
std::iota(std::begin(indices), std::end(indices), 0);
auto start = high_resolution_clock::now();
int v = 0;
for (int index: indices) {
v += array[index];
}
printf("%d %d\n", v, high_resolution_clock::now() - start);
}
void randomized(int count, int max) {
vector<int> array = generateArray(count, max);
std::vector<int> indices(count);
std::iota(std::begin(indices), std::end(indices), 0);
std::random_device rd;
std::mt19937 g(rd());
std::shuffle(indices.begin(), indices.end(), g);
auto start = high_resolution_clock::now();
int v = 0;
for (int index: indices) {
v += array[index];
}
printf("%d %d\n", v, high_resolution_clock::now() - start);
}
int main() {
int count = 10000000;
int max = 10;
randomized(count, max);
sequential(count, max);
}
Znowu mamy dwie funkcje które robią dokładnie to samo, liczymy ile czasu wykonuje się prosta pętla sumująca elementy tablicy. Jedyna różnica jest taka, że w jednym przypadku lecimy po kolejnych indeksach tablicy (bo nasze indices ma wartości 0,1,2,3...) a w drugim przypadku lecimy losowymi indeksami (bo zrobiliśmy shuffle na tablicy indeksów). Z punktu widzenia złożoności obliczeniowej znowu jest tu zwyczajnie O(n), a jednak u mnie lokalnie opcja sekwencyjna jest 5 razy szybsza. Znowu, zastanów się czemu jest taka różnica, skoro niby robimy dokładnie to samo.
(Wszystko to przy -O0)