R&D - Przykład przygotowań do stworzenia algorytmu. Korzystanie z COM
Wstęp
Innowacyjność jest motorem gospodarki. Można czasem znaleźć oferty pracy dla programistów w działach R&D. Być może dla współczesnego młodego programisty lub kandydata na studia techniczne R&D to skrót doskonale znany. Skrót pochodzi od angielskiego Research And Development, czyli po polsku Badania i Rozwój. Warto może wspomnieć, że działy badawczo-rozwojowe istniały w Polsce przed transformacją ustrojową w roku 1989. Wiele zakładów przemysłowych je posiadało. Pozostały po nich liczne wynalazki i patenty.Artykuł powstał na bazie rzeczywistego przykładu, nad którym autor pracował w jednej z firm. Chodziło o wyszukiwanie gotowych, już raz napisanych odpowiedzi email mentora na pytania uczestników szkoleń typu e-learning (internetowych) w oparciu o statystyczną analizę treści pytań i odpowiedzi. Algorytm miał uszeregować najlepiej pasujące (skorelowane) odpowiedzi. Dzięki temu po modyfikacji przez mentora mogły one być udzielane szybciej. Udało się uzyskać bardzo efektywne rozwiązanie dla obszernego zbioru emaili.
Tu przykładowe teksty zaczerpnięto ze zbioru wątków forum 4programmers.net. Autor wybrał nieco ponad 10 wątków z forum Off-Topic. Są one w postaci dokumentów programu MS Word - jeden wątek, jeden dokument. W dokumentach jest wiele tabel, z których trzeba wydobyć tekst i punktację, aby uzyskać formę łatwiejszą do przetwarzania przez potencjalny algorym szukający korelacji pytanie-odpowiedź.
Pokazano dwa programy narzędziowe. Wprowadzają czytelnika w komunikację między programami w modelu COM i ich wsadowe uruchamianie.
Załącznik - zbiór postów z forum w formacie MS Word
[zbior_tekstow_z_forum.zip](//4programmers.net/Download/207758/513)Dodawanie referencji w C# - podstawy
Menu Visual Studio
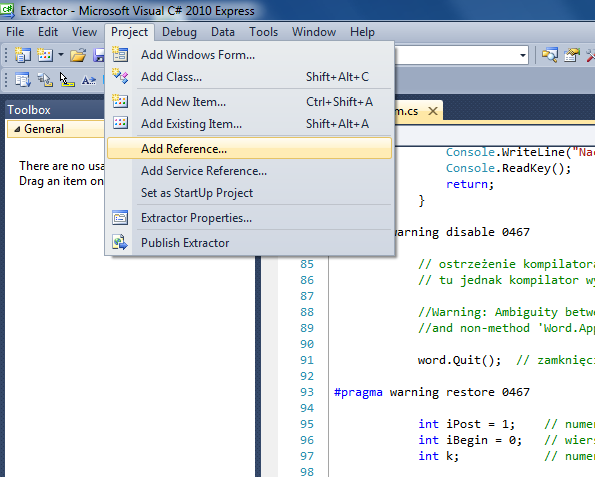
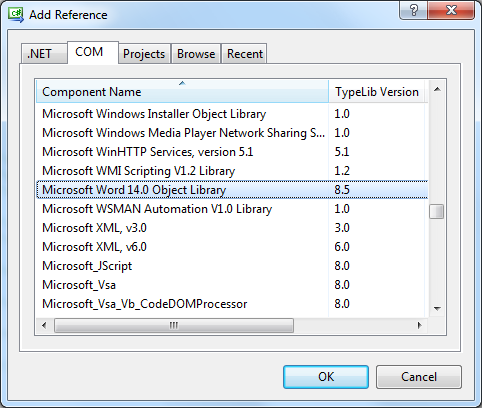
Lista dostępnych bibliotek
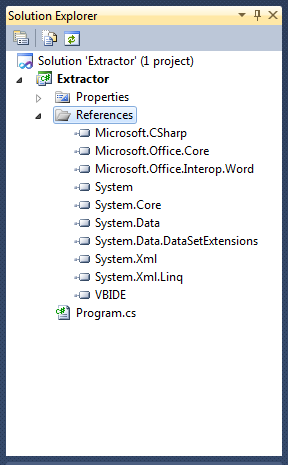
Referencje w Solution Explorerze
Wpisanie do sekcji using
// Word 2010, Reference COM: Microsoft Word 14.0 Object Library
using Word = Microsoft.Office.Interop.Word;
// Word 2003, Reference COM: Microsoft Word 11.0 Object Library
// using Word;
Program do wyodrębniania (ekstrakcji) tekstów z tabel Word
```csharp using System; using System.Collections; using System.Diagnostics; using System.IO;// Word 2010, Reference COM: Microsoft Word 14.0 Object Library
using Word = Microsoft.Office.Interop.Word;
// Word 2003, Reference COM: Microsoft Word 11.0 Object Library
// using Word;
namespace Extractor
{
class Program
{
static void Main(string[] args)
{
if (args.GetLength(0) != 4) // sprawdzenie ilości argumentów programu
{
return;
}
string docPath = args[0]; // argument 1: ścieżka folderu z dokumentami źródłowymi Word
string filename = docPath + "\\" + args[1]; // argument 2: nazwa przetwarzanego dokumentu
string topicId = args[2]; // argument 3: sygnatura grupy postów (dowolna)
string destPath = args[3]; // argument 4: ścieżka folderu z dokumentami tekstowymi
// po ekstrakcji
const int MaxPoints = 50; // założone ograniczenie z góry liczby głosów oddanych na post
char[] separators = { '\r', '\n' }; // separatory oddzielające wiersze
object openFileName = new object(); // nazwa przetwarzanego dokumentu
openFileName = filename;
object separator = new object(); // separator komórek tabel
separator = "\n";
object nestedTables = new object(); // flaga nakazująca przetwarzanie tabel zagnieżdżonych
nestedTables = true;
ArrayList lines = new ArrayList(); // lista wierszy
// KillWordProcesses(); // zakończenie wszystkich uruchominych procesów aplikacji Word
// podczas tworzenia programu ta funkcja bywa przydatna
Word.Application word = new Word.Application(); // uruchomienie aplikacji Word
word.Visible = false; // nie wyświetlaj aplikacji Word
Word.Document doc = null; // dokument otwierany w aplikacji Word
try
{
doc = word.Documents.Open(ref openFileName); // otwarcie dokumentu
}
catch (Exception ex)
{
// tu: obsługa wyjątku
}
foreach (Word.Table t in doc.Tables) // przekształć wszystkie tabele
// w dokumencie na tekst
{
string s = t.ConvertToText(ref separator, ref nestedTables).Text; // konwersja tabel na tekst
string[] range = s.Replace(('\v').ToString(), "").Split(separators); // usunięcie zbędnych znaków
// i podział na wiersze
lines.AddRange(range); // dodanie wszystkich wierszy
} // pojedynczej tabeli do listy
object saveFileName = new object();
FileInfo fi = new FileInfo(filename);
saveFileName = destPath + '\\' + fi.Name.Substring(0, fi.Name.Length - (".doc").Length) + "-Kopia.doc";
try
{
doc.SaveAs(ref saveFileName); // zapisanie dokumetu pod inną nazwą
}
catch (IOException ex)
{
// tu: obsługa wyjątku
}
#pragma warning disable 0467
// ostrzeżenie kompilatora przed możliwością dwojakiego zinterpretowania kodu
// tu jednak kompilator wybiera poprawnie i ostrzeżenie można wyłączyć
//Warning: Ambiguity between method 'Word._Application.Quit(ref object, ref object, ref object)'
//and non-method 'Word.ApplicationEvents4_Event.Quit'.
word.Quit(); // zamknięcie Worda
#pragma warning restore 0467
int iPost = 1; // numer kolejny postu w wątku na forum
int iBegin = 0; // wiersz z początkiem kolejnego postu w tekście niepodzielonym
int k; // numer kolejny wiersza w tekście niepodzielonym
// iteracja po wszystkich wierszach dokumentu
for (int li = 0; li < lines.Count; li++)
{
// znajdowanie tekstu zawierającego liczbę głosów oddanych na post
// teksty postaci np. "4Głosuj na ten post"
// ograniczenie MaxPoints = 50 jest przyjęte z bardzo dużym zapasem
// zwykle oddawanych jest 0, 1, 2, 3 głosy, najczesciej zero
// iteracja 0..50 byłaby bardzo nieefektywna przy innym rozkładzie ilości
// oddawanych głosów, tu jest wystarczajaca, przerywana przez break
// po znalezieniu tekstu
for (int j = 0; j < MaxPoints; j++)
{
if (lines[li].ToString() == j.ToString() + "Głosuj na ten post")
{
// utworzenie nazwy pliku (pojedynczy post) do dalszego przetwarzania
string filename2 = destPath + @"\Post_" + topicId + "_" + iPost.ToString("D04") + "_" + j.ToString("D02") + ".txt";
StreamWriter sw = new StreamWriter(filename2); // otwarcie strumienia do zapisu pliku
for (k = iBegin; k <= li; k++) // iteracja po wierszach dokumentu bez tabel
{
string s = lines[k].ToString().Trim(); // obcięcie skrajnych spacji i znaków sterujących wiersza
// pozostawienie tylko odstępów jednej spacji miedzy słowami
while (s.Contains(" "))
{
s.Replace(" ", " ");
}
if (s != j.ToString() + "Głosuj na ten post")
{
try
{
sw.WriteLine(s);
}
catch (IOException ex)
{
// tu: obsługa wyjątku
}
}
}
sw.Close();
FileInfo fi2 = new FileInfo(filename2);
Console.WriteLine(fi2.Name); // po pomyślnym przetworzeniu i zapiasaniu postu kolejne iteracje
// wypisz nazwę pliku na ekranie konsoli
iPost++;
iBegin = k;
break;
}
}
}
// zakończenie wszystkich uruchominych procesów aplikacji Word
// podczas tworzenia programu ta funkcja bywa przydatna
// KillWordProcesses();
}
// funkcja kończenia wszystkich procesów Worda
// w fazie tworzenia algorytmu przetwarzania
// zdarzają sie pomyłki prowadzące do uruchomienia
// Worda zbyt wiele razy
static void KillWordProcesses()
{
Process[] processList = Process.GetProcesses();
foreach (Process process in processList)
if (process.ProcessName.ToLower() == "winword")
process.Kill();
}
}
}
<h3>Program do wsadowego uruchamiania ekstrakcji</h3>
```csharp
using System;
using System.Diagnostics;
using System.IO;
namespace Batch
{
class Program
{
/// <summary>Parametry użyte podczas testów</summary>
/// <param name="args[0]">C:\Users\Artur\Desktop\BatchExtractor\Extractor\zbior_tekstow_z_forum</param>
/// <param name="args[1]">C:\Users\Artur\Desktop\BatchExtractor\Extractor\bin\Release\Extractor.exe</param>
/// <param name="args[2]">C:\Users\Artur\Desktop\Extracted</param>
static void Main(string[] args)
{
if (args.GetLength(0) != 3) // sprawdzenie ilości argumentów programu
{
return;
}
string docsPath = args[0]; // argument 1: ścieżka do folderu
// zawierającego dokumenty Word
string execFile = args[1]; // argument 2: ścieżka do programu
// wyodrębniającego tylko tekst z dokumentów Word
string destPath = args[2]; // argument 3: ścieżka do folderu
// z wyodrębnionymi tekstami
// dodanie sygnatury czasowej do nazwy folderu destPath
DateTime dt = DateTime.Now.ToLocalTime();
destPath += " " + dt.ToShortDateString() + " " + dt.ToString(@"hh\.mm\.ff");
if (!Directory.Exists(destPath))
{
try
{
Directory.CreateDirectory(destPath);
}
catch (Exception ex)
{
// tu: obsługa wyjątku
}
}
// utworzenie i przetworzenie listy plików Word
string[] docFiles = Directory.GetFiles(docsPath, "*.doc");
int i = 0;
foreach (string f in docFiles)
{
i++;
FileInfo fi = new FileInfo(f);
Console.WriteLine("Podaj sygnaturę dla:\n" + fi.Name);
string s = Console.ReadLine();
string topicId = i.ToString("D02") + '_' + s;
Process p = new Process();
p.StartInfo.UseShellExecute = false; // nie używaj funcji ShellExecute
p.StartInfo.RedirectStandardOutput = true; // kieruj wyjście programu uruchamianego
// wsadowo do programu uruchamiającego
p.StartInfo.CreateNoWindow = true; // nie twórz okna programu uruchamianego
p.StartInfo.FileName = execFile; // uruchamiany program
// przekazanie argumentów
p.StartInfo.Arguments = '"' + fi.DirectoryName + "\" \"" + fi.Name + "\" " + i.ToString("D02") + '_' + s + ' ' + '"' + destPath + '"';
try
{
p.Start(); // uruchomienie programu
string output = p.StandardOutput.ReadToEnd(); // pobranie przekierowanego
// strumienia wyjściowego
p.WaitForExit(); // oczekiwanie na zakończenie procesu
Console.WriteLine(output); // wypisanie pobranego strumienia wyjścia
// w oknie programu uruchamiającego
}
catch (Exception ex)
{
// tu: obsługa wyjątku
}
/*
// w czasie tworzenia programu warto ograniczyć ilość prztwarzanych plików
if (i == 3)
{
break;
}
*/
}
// usunięcie kopii dokumentów Word
try
{
string[] DeleteSet = Directory.GetFiles(destPath, "*Kopia.doc");
foreach (string f in DeleteSet)
{
File.Delete(f);
}
}
catch (Exception ex)
{
// tu: obsługa wyjątku
}
// zkończenie przetwarzania
Console.WriteLine("Przetwarzanie wsadowe zakończone.");
Console.WriteLine("Naciśnij dowolny klawisz...");
Console.ReadKey();
}
}
}