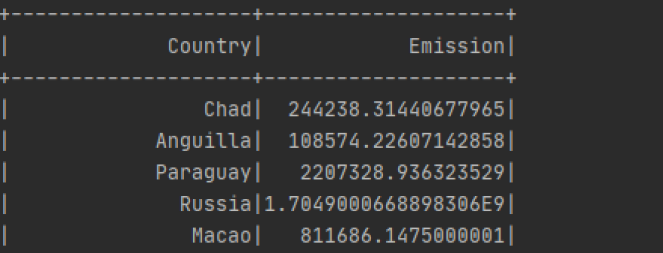
Kopiuj
21/12/28 06:01:59 ERROR Executor: Exception in task 0.0 in stage 7.0 (TID 7)
org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/worker.py", line 619, in main
process()
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/worker.py", line 611, in process
serializer.dump_stream(out_iter, outfile)
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/serializers.py", line 259, in dump_stream
vs = list(itertools.islice(iterator, batch))
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/util.py", line 74, in wrapper
return f(*args, **kwargs)
File "lab4.py", line 18, in <lambda>
df = df.map(lambda x: (x[0].strip(','),x[1].strip(','),x[2].strip(','),x[3].strip(',')))
AttributeError: 'NoneType' object has no attribute 'strip'
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:545)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:703)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:685)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:498)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.agg_doAggregateWithoutKey_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:759)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:140)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:506)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1462)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:509)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
21/12/28 06:01:59 WARN TaskSetManager: Lost task 0.0 in stage 7.0 (TID 7) (kontroler executor driver): org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/worker.py", line 619, in main
process()
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/worker.py", line 611, in process
serializer.dump_stream(out_iter, outfile)
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/serializers.py", line 259, in dump_stream
vs = list(itertools.islice(iterator, batch))
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/util.py", line 74, in wrapper
return f(*args, **kwargs)
File "lab4.py", line 18, in <lambda>
df = df.map(lambda x: (x[0].strip(','),x[1].strip(','),x[2].strip(','),x[3].strip(',')))
AttributeError: 'NoneType' object has no attribute 'strip'
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:545)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:703)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:685)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:498)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.agg_doAggregateWithoutKey_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:759)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:140)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:506)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1462)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:509)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
21/12/28 06:01:59 ERROR TaskSetManager: Task 0 in stage 7.0 failed 1 times; aborting job
Traceback (most recent call last):
File "lab4.py", line 48, in <module>
spdf.select(F.avg(F.col("Emission")).alias("average")).show()
File "/usr/local/lib/python3.6/site-packages/pyspark/sql/dataframe.py", line 494, in show
print(self._jdf.showString(n, 20, vertical))
File "/usr/local/lib/python3.6/site-packages/py4j/java_gateway.py", line 1310, in __call__
answer, self.gateway_client, self.target_id, self.name)
File "/usr/local/lib/python3.6/site-packages/pyspark/sql/utils.py", line 111, in deco
return f(*a, **kw)
File "/usr/local/lib/python3.6/site-packages/py4j/protocol.py", line 328, in get_return_value
format(target_id, ".", name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling o97.showString.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 7.0 failed 1 times, most recent failure: Lost task 0.0 in stage 7.0 (TID 7) (kontroler executor driver): org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/worker.py", line 619, in main
process()
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/worker.py", line 611, in process
serializer.dump_stream(out_iter, outfile)
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/serializers.py", line 259, in dump_stream
vs = list(itertools.islice(iterator, batch))
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/util.py", line 74, in wrapper
return f(*args, **kwargs)
File "lab4.py", line 18, in <lambda>
df = df.map(lambda x: (x[0].strip(','),x[1].strip(','),x[2].strip(','),x[3].strip(',')))
AttributeError: 'NoneType' object has no attribute 'strip'
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:545)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:703)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:685)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:498)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.agg_doAggregateWithoutKey_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:759)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:140)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:506)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1462)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:509)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2403)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2352)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2351)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2351)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1109)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1109)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1109)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2591)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2533)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2522)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
Caused by: org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/worker.py", line 619, in main
process()
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/worker.py", line 611, in process
serializer.dump_stream(out_iter, outfile)
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/serializers.py", line 259, in dump_stream
vs = list(itertools.islice(iterator, batch))
File "/usr/local/lib/python3.6/site-packages/pyspark/python/lib/pyspark.zip/pyspark/util.py", line 74, in wrapper
return f(*args, **kwargs)
File "lab4.py", line 18, in <lambda>
df = df.map(lambda x: (x[0].strip(','),x[1].strip(','),x[2].strip(','),x[3].strip(',')))
AttributeError: 'NoneType' object has no attribute 'strip'
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:545)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:703)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:685)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:498)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.agg_doAggregateWithoutKey_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:759)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:140)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:506)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1462)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:509)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)