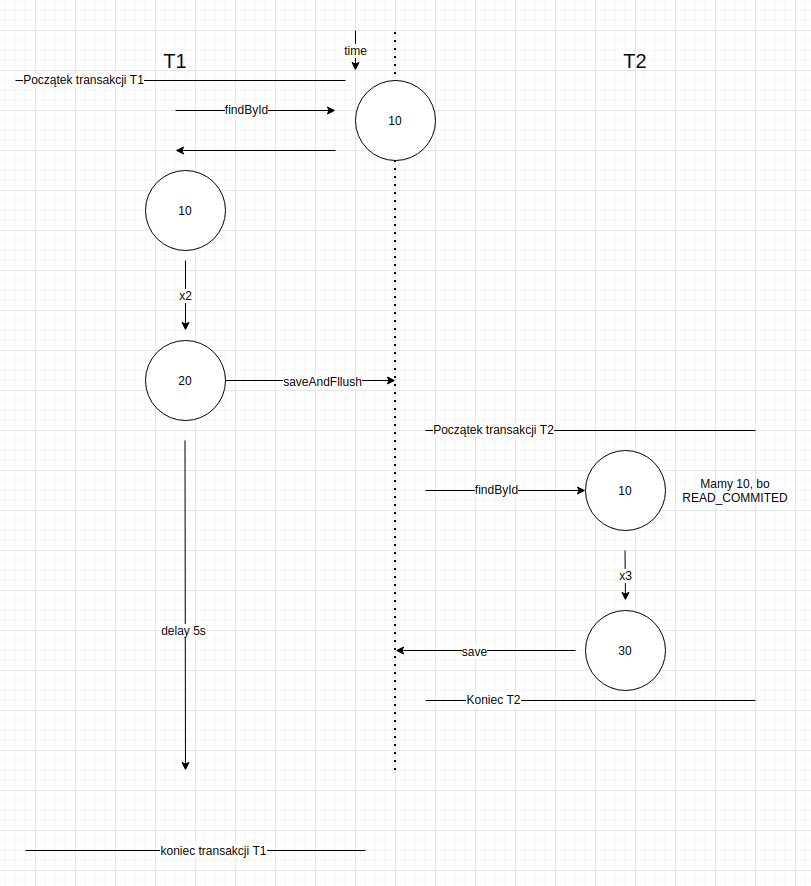
Cześć, mam taką zagwozdkę w temacie relacyjnych baz i transakcji.
Mam transakcję T1, która pobiera z repo counter (10), mnoży go x2 (20), zapisuje, ale metodą saveAndFlush, aby update poszedł od razu, po czym czeka załóżmy 5s (bo np jest jeszcze jakaś długa operacja biznesowa) i dopiero się commituje.
W międzyczasie (ale po tym jak fizycznie poszedł update countera (20) w T1) transakcja T2 pobiera counter (jest 10, bo izolacja READ_COMMITED), mnoży go x3 (30) i zapisuje do DB - i to jest zanim T1 się zakomituje, bo T2 nie ma żadnych długich operacji.
No i w wyniku mamy counter = 30. No i tu jest ok, ale zastanawiam się dlaczego request http, który zrobił T2 kręci się aż do czasu kiedy skończy się T1? W logach widzę, że T2 robi sql z updatem countera na 30 dużo wcześniej. Czy ta T2 musi z jakiegoś powodu czekać na commit T1? Czemu tak jest?
I dodatkowo jeśli mam w T1 saveAndFlush, a na jej końcu rzucę jakiś RuntimeException to rollback tej transakcji coś zrobi w ogóle? Odkręci ten update jak rozumiem?
Jeśli T1 nie ma flusha tylko normalny save, to request z T2 trwa ułamek sekundy, ale counter na końcu jest 20, bo T1 puszcza update do bazy na samym końcu transakcji i to jest dla mnie zrozumiałe.