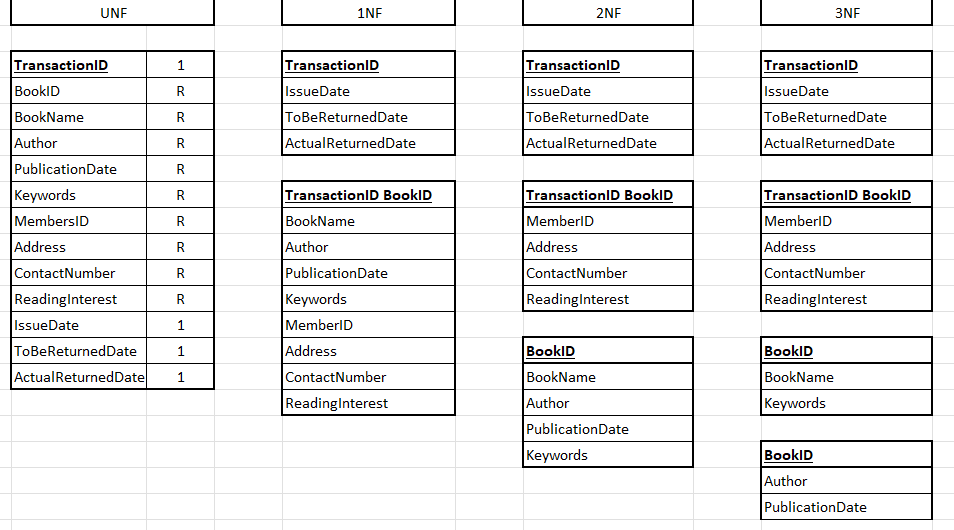
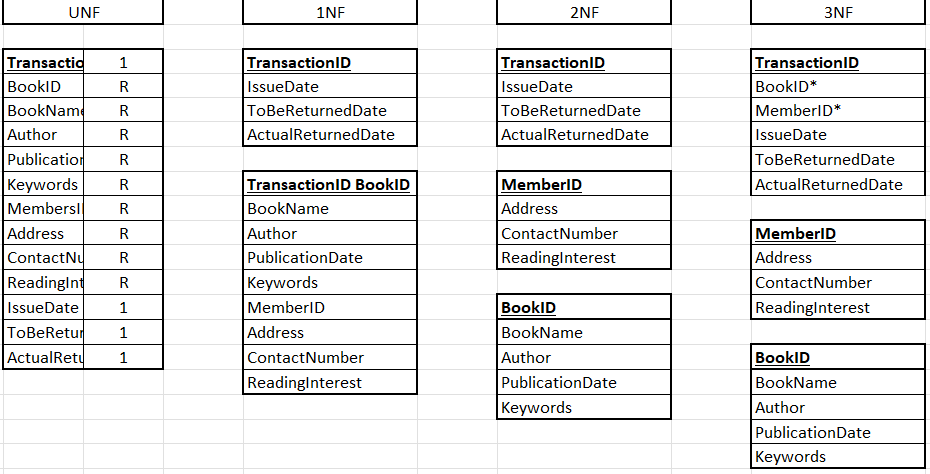
Poszedlem za Twoimi radami i przeksztalcilem to tak jak zrozumialem. Tworze obecnie diagram z relacjami i mam problem jak powiazac ta tabele posredniczaca za pomoca kluczy (PK i FK) oraz relacje jakie w niej wystepuja. Zalozylem ze trzy slowa keywords powinny wystarczyc - potem bede musial te slowa pouzupelniac jakimis danymi, dlatego tez boje sie ze w pewnym momencie rozbuduje sie to za bardzo i bede zmuszony spedzic grom czasu na uzupelnianiu tabeli.

Transaction (jedna do wielu) Members - jedna tranzakcja musi miec jednego uzytkownika, ale uzytkownik moze miec wiele transakcji
Members (jedna do wielu) Addresses - jeden uzytkownik moze miec jeden adres, ale moze byc wiele uzytkownikow pod jednym adresem
Transaction (jedna do wielu) Books - jeden tranzakcja odnosi sie jedynie do jednej ksiazki, ale ksiazki moga byc wiele razy wypozyczane i moga miec wiele tranzakcji
No i tutaj zaczely sie schody. Nie wiem czy nie dalem za wiele FK do tabeli posredniczacej, bo wlasciwie tutaj juz zglupialem. Ogolnie to bylaby to relacja wiele do wielu, ale z tego co wiem po to jest ta posredniczaca aby tego uniknac i wprowadzic relacje jedna do wielu i wiele do jednej.
Jedna ksiazka ma wiele slow kluczowych, slowa kluczowe moga opisywac wiele ksiazek.
Books (jedna do wielu) BooksKeywords - ale jak pomysle ze dojde do momentu kodowania kluczy PK i FK to mnie az ciarki biora.
BooksKeywords (wiele do jednej) Keywords - ale jak taka relacje zapisac skoro jedna Keyword_ID z tabeli jest pobierane az trzykrotnie w innej tabeli? Czy to co przedstawiam ponizej ma racje bytu? Czy cos nalezaloby zmienic?

Zabieram sie zaraz za fizyczny model ERD. Mam nadzieje ze powyzsze jest poprawne :D Nie chcialbym zaczynac od nowa ;(
Czuje ze brakuje mi wyobrazni albo tez wiedzy jak taka tabela laczaca powinna dzialac. Podejrzewam ze powinienem zastosowac tam nowe ID ktore bylo by PK, a w tej tabeli tylko dwie pozycje Book_ID i Keyword_ID jako FK. Ale nie jestem w stanie wyobrazic sobie jak fizycznie takie zastosowanie moze dzialac. ;(
Fizyczny model w takim razie wygladalby w ten sposob. Bardzo duzo pozycji zastrzeglem jako NOT NULL, co moze byc pozniej dla mnie strasznie problematyczne.

Chyba ze to tak powinno wygladac (czyzby nagle olsnienie?), Dwa FK, bo wlasciwie PK jest zbedny?: